 )
)���������߰���TiDB �ǹ��� PingCAP �Ŷӿ�����һ���ֲ�ʽ SQL ���ݿ⡣����������� Google �� F1��TiDB ֧�ְ�����ͳ RDBMS �� NoSQL �����ԡ��ڹ��� ITOM ����ƽ̨ OneAPM�ٰ�ļ����������У�TiDB �ĸ�����ʦ����� HBase ���ԡ�TiDB �����ƺ�ϵͳ�ܹ��ȷ����������ϸ����������Ϊ�ݽ�������
����HBase ���
����������֪���� SQL ���洦�ڶ�������������˾��һ���� Oracle�������Ѿ������˴����ľ��飬��һ���ǹȸ裬�ȸ� F1 ��2012�귢����һƪ���ģ�������Ϊ����ȫ��������� SQL OLTP ���ݿ⡣
����1978�����ң����ݿ�ոշ�չʱ������SQL RDBMS��2000�����ң����ڿ�ʼ���л��������������� Oracle ���ݿ�Ҳ�����ϴ�ij�������ڣ���ͳ�����ݿ���Ǽ����ڴ�ͳ�������������õñȽ϶���� MySQL ����� HBase �� NoSQL Ҳ�����˴������û���
����Ϊʲô����� NoSQL���ʼ�����˶��� SQL Database����ʱ�Ƚϸ߶��� Oracle����Դ�Ļ��� MySQL��PostgreSQL����������ҵ���Ѹ�ٷ�չ�����ݿ��Ϊ��ƿ�������Ǵ�ʹ�� NoSQL �ĵ�����NoSQL �� Scale ���ڵ�һλ�����ҵ����ٷ�չ�����ݻ��Ϊؽ���������Ҫ���⡣��ʱ��������˻�ѡ���������һ���ԡ�ʲô��һ���ԣ�����ʹ����ʱ������Ҽ���Ϊ���ѣ�����һ��˫���ϵ����Ӧ�����ݿ���������������������һ���ں����б������ӽ������ڶ�������ĺ����б�����Ҽӽ�ȥ������������б������ݿ���ڲ�ͬ�Ļ����ϣ�����Ҫ��֤һ���ԡ�������ܻ����������ĺ��ѣ�����ĺ�����ȴ�Ҳ����ҵ���������������м���ܻ���ֶ�������������Ұ����Ϊ���ѣ�Ȼ�������ݵ�ʱ�� Crush ���ˣ����ʱ��ͳ�����ǻ�����һ����Ϣ���У��еĻ���Ҫ��һЩ��������Щ������ NoSQL �ﴦ����������鷳��
������������ HBase ʹ������С��˾���м��� HBase �� Committer �����Ծ���һЩ�ĺ����֧�ֲַ�ʽ���������ܹ����֮ǰ�����⡣Ϊʲô���������ѡ��ʱ��С��ѡ�� HBase �أ���Ŀǰ�����˵����Ҫ���Ǽ���ѡ�ͺ��˲Ŵ����ϵĿ��ǡ� MongoDB ���Ӧ�ò�İ�������õ�һ���̶Ⱥ��ܻ���ָ������⣬���������º�����ҷ��� MongoDB �����������ݿⶼ���ǡ�ʮȫʮ�����ģ�û����ã�ѡ�����ʺϵ���Ϊ��Ҫ��
�����ܶ�ʱ���Ʒ���������ԣ������������Ի��߹�������£�ʹ���������ܷdz�˳�֣�����ʮ֮�˾Ŷ����������鷳������С��ʹ�� HBase �ͷdz�˳�֣��������Ĺ�˾��һ���������ܼ��������Ϥ��ʹ�ó�����Ҳ��֪������Ӧ��������ʲô���������Ի���ָ��ָ��������⡣
����
������ʵ�ϣ�HBase �зdz��õ����ԣ�Ŀǰ��С��˾����ÿ����һ���� OPS ����� Pinterest �������ǵ� HBase ÿ�������������� OPS ���������������Զ���ܶ������˾�� HBase �ڶ�дһ���Է���dz���ɫ���кܺõ��Զ� Scale ��������ͨ��Block Cache �� Bloom Filters���ԺܺõĽ����ѯ���⣬�Ƿ��ڴ�����Ҳ����ͨ��Bloom Filters���ж���
������һ���棬Oracle ��һ����������� CPU/Ӳ�����Ӧ�� HBase Ҳ���һ���������Ƶ���Ӧ�� RegionServer �ϡ�����һ���ֲ�ϵͳ��˵�������Ҫ��ѯһ������������ֱ�Ӱ���������Ƶ���Ӧ�� RegionServer ��ִ�С��ٱ���������㣬������һ�������ݣ�����һǧ�������ݣ��ֲ���10���ڵ��ϣ�������ͷ����������нڵ�ͬʱ���㣬������������Ƶõ����ж�Ӧ���ݵĺͣ�����ռ���10�����ݵĺͼ��ɡ���ʵ�����Լ��������ƣ����DZȽϸ��ӵ����ݿ��Ż�������ʵ�������������ӡ����� HBase �������� Coprocessor ��ʵ�֡�
�������Ӧ�ö� MVCC �Ƚ���Ϥ��Ҳ���Ƕ�汾�������ŵ����ڿ��Զ�ζ�ȡ������ block��Ȼ����һ���ܺõ����ԣ��������õ� Database ��MVCC ����û���� compaction ֮ǰ���Իص��κ�ʱ������ݡ������Ʒ�����Ҳ����ÿ����Сʱ��һ�ο��գ�ʵ�������ʹ�� MVCC �ص�����һ��Ļ���������ȫ����Ҫ���ա�
����TiDB������
���������ٽ���һ�����ǵIJ�Ʒ TiDB��Ti ��Ԫ�����ڱ����Ԫ�ء��������˽������Ŷӵij���Ա����֪�����Ƕ��Ƚ� Geek��ȡ����Ҫô��ϣ������ѡһ��������֣���������ѧ����һ��ϣ����ĸ�� ���ǿ���һȦ���ÿӶ��Ѿ���ռ���ˡ����ǣ������ڻ�ѧԪ�����ڱ�������һ��������Ϊ��Ŀ���ƣ����� Database ���ԣ��������Ǹ����ȶ��ģ��պ��ѽ����к�ǿ�ķ���ʴ�ԣ�����ѡ�����ѣ�Ti����
����
������Ϊ TiDB ��Ŀ���ǹȸ� F1��������Ȼ�������������ԡ������ǿ�������ֲ�ʽһ�£�Ҳ����˵����Ӧ����˵�����ù��ĺ���ֳɶ��ٸ������������һ�����DZ��뱣֤�ģ���������֮ǰ�ᵽ�� A ��ע B����������Ӻ��ѻ���ת�ʣ�����ֱ������һ�� SQL �㶨�������赣���м���̡�����һ�������Ǽ��� MySQL Э�飬���ڴ����70% �Ļ�������˾����ʹ�� MySQL��Ϊ�˿��Ǵ�ҵ�Ǩ�Ƴɱ������ǻ���� MySQL Э�顣ͬʱ�������Ѿ��ܶ� APP �� MySQL �����У�Ϊ�����ṩ�˳���IJ��������� TiDB �IJ�������ٶ������ÿ���ύһ�д���ʱ����������6���������е��� Test ����ٶ��� Test ����ʱ���Լ��ʮ���ӡ�Ϊ���չ˸������氮���ߣ����ǻ�֧���� LevelDB ��RocksDB��LMDB��BoltDB �ȡ�TiDB ��Ҫ�Dz��� Go ���Կ����ģ��������������⣬�������ܷdz��ߡ�
����ϵͳ�ܹ�
����
�����κ��� MySQL Э��д�ij�����ֱ��ʹ�� TiDB �����м��� MySQL Э����ص����ݣ��������� SQL Layer����������� KV �㣬������ F1 �� Spanner �������Ϊ���ܵĵط�����ײ�Ĺ����Ǵ� KV ��ʼ���� KV �����ϼ�һ���ֲ�ʽ�� KV ������֧������Ȼ������ SQL ���ֱ��ӳ�䵽 KV ���ϡ�
����
���������������ҽ��� �ֽ� TiDB ʹ�õķֲ�ʽ����������� HBase ��ʵ�ֵģ����ڰ汾�У����Dzο����� Google �� Percolator ��ģ�͡����ȼ�����һ�� Client����Ϊ�����һ�� Timestamp���� Google �����н���Time Oracle����������ʱ���������֮���������д����������ʱ������п��ն�������ύ֮ǰҪ�� Prepare ��Prepare��ʱ������Ƿ��ͻ������ύʱ��õ� Commit �������������û���κγ�ͻ�Ϳ����ύ��
����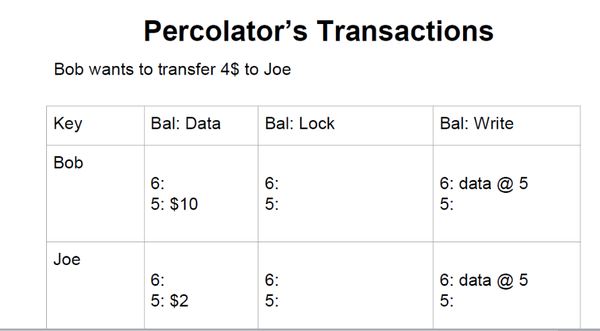
������ͼ������һ��ʵ��������ʻ������ Bob ��10���𣬶� Joe ��5����ǰ������ִ�����汾����ǰ�ǵ�6���汾��ָ����ǵ�5���汾��Ϊ10����Joe ��2����
����
��������BobҪת4����� Joe����һ����Ҫ��ת��ȥ4����10������6�������ڱ��۵�4����Ȼ����עһ���Լ���������
����
����Joe��ǰ�ǵ�7���汾����Ϊ���õ���4���������������6����ͬʱ����Լ�ָ������һ������ Bob��
����
�������ڰ˸��汾ʱ��������ָ�����ڵ�7����ʱ��������ɾ����������ʵ�ʱ����������ɾ������ô������ͻ�Ѳ����ڣ����Խ����ύ��ͬʱ��������Լ�����ɾ�����м仹��һЩ�������������̡�
������������ģ���л��е��㣬�� Time Oracle ����һ��ʱ������������������ϵͳ�����ܡ�Google ��������һ����Ӧ�����������ܵ�������ÿ�롣��Ϊ����ʼ�ͽ�����ʱ����Ҫȡһ�� Timestamp ��������������д������ٶ���һ����ÿ�룬�����Ѿ���������ʵ�֡�ʵ���ϣ������и��õķ�ʽ��������ٶȣ��� HLC ��һЩ Time Oracle�ĸĽ��㷨��
����
�������� Spanner �������ص�ο������ǹȸ� Spanner �� F1 ������ Spanner �߶�������ʱ�ӣ����Թȸ���һ��ԭ���Ӻ� GPS ʱ�ӣ�GPS �źſ��Ը�������λ�ú�ʱ�䡣Ϊʲô��Ҫԭ�����أ����� GPS ʱ���ر������ܵ����ţ�������������ʱ GPS ʱ�ӾͲ������У���ԭ������Ȼ���á�
����
����
������ͼ�ǹȸ� F1 ��һЩ��Ϣ�����е�������˹ȸ� F1 ����ƪ���ģ��������Ȥ�Ļ�����ϸ��һ����Ŀǰ���� TiDB �����Ķ�����ʵ����ƪ���ġ�������һǧ�����ݣ�������Ҫ��ijһ�м�����ʱ���ڴ�ͳ���ݿ���Ӧ����β���������˵�ڷֲ�ʽ�����£�����MySQL ��һ������һ���������⼸������ʵ�֣����һ����뱣֤ index ��һ���ԡ�����ϸ����ο����ġ�
����
����TiDB ����δ� SQL Ǩ�Ƶ� KV �ϵ��أ��ɻ���֪ʶ��֪����ͳ�� RDBMS ���ݿ����һ����һ�� B-Tree�����ڷֲ�ʽ��ϵ�����ݿ⣬վ�ڸ��ϲ�һ�㿴������ȸ��F1�����ݿ�ײ㶼�� KV �㣬���� KV �����²����������һ�� User Table���� TiDB ��������Table�Ľṹ���� uid��name�� email ���ɡ��� TiDB ����һ�������н��� RowID �����еIJ������������������� RowID ������ RowID ��1�� uid ��XX��Name �� Bob��Email �� bob@Email.com���ⶼ����Ԫ��Ϣ��������� Column name �ܳ�������������ݿ���洢����ԭ��Ϣ���� TiDB �У� ÿһ�ж���Ψһ��UID��
�������� Table �� ID ��1��uid �� ID ��2��name ��ID��3��email �� ID ��4�������ݿ��д洢Ϊһ�� KV �ṹ��Ȼ��� TableID��RowID ��ColumnID �������±��룬ֱ�ӽ��������һ���г�4�� KV ����ʱ��������� select �� Email ����ijһ��ֵ�Ļ������ǿ���ֱ��ȡ������Ӧ��ֵ���ٶȷdz��졣
�������� MySQL
����TiDB �� MySQL Э���кܺõļ����ԡ���һЩ�Ƚ�֪���� MySQL Ӧ�ú������ߣ�����WordPress��PhpMyAdmin�� MySQL Workbench��������ֱ�ӻ��� TiDB ���С��������ݿ���������չ�������ǵ������ݿ⡣��Σ�TiDB �����ݸ��� ORM ������ XORM ��Beego ORM �ȣ��ܹ�֧�ֺܶ� MySQL ��Ӧ�á�ÿһ�δ�����£���Щ ORM Test ���Զ�����һ�Σ��Ӷ���֤�� MySQL �ļ����ԣ���Ȼ����һЩ�Ƚ�ϸ��������ʱû��֧�֡������Ѿ�֧���첽�� Schema ��������� DDL �����������������ϵ�ҵ��
������������
����Ŀǰ TiDB ��ȫ��Դ�� Github ���档��Դ�Ϳ��ŵĸ����������£��ܶ��˾����ν�Ŀ�Դֻ�ǰѴ����ϴ�һ�£����ڱȽ�֪���İ���Ҳͦ��ģ����֪���ܶ���Ŀ���Ѿ�������ά�������������Ǵ�����ȫ��һ�����ŵ���̬�����������飬ȫ���Ĵ��룬ȫ�������ۣ� Code Review��Bug Tracking��Roadmap ���ǿ�Դ�ģ��Ͼ�ͨ�õķֲ�ʽ OLTP ��ϵ�����ݿ���һ���dz�ǰ�ض��Ҽ�����Ҫ������δ�������ϵ� DBaaS ����Ҫ��ɲ��֣����������Ŀǰ����������������ʹȫ��������û��һ��̫���쿪Դ���������TiDBҲĿǰҲ�������ڣ��Ӽܹ������������ǽ� SQL ��� KV �����˺ܳ��ķ��룬��Ҳ������ϣ����������ܸ����Լ�����Ҫ������Ľ��ж��ƣ�����Ҳ��ú����������ijһ�ҹ�˾������ij�����˵������Dz����ģ����� PingCAP ֻ�ǽ���һ�ѻ������������ܴ�ã��ƶ�������ƽ�Ĺ�����������ĺ�����˾�Ͷ��������ߣ�һ�� TiDB �����й���һ�����綥���Ŀ�Դ��Ŀ��ʵ�ֹ�Ӯ��
�����õ���Ŀ���������������ƶ����ͱ��� HBase��HBase �������κ�һ����˾����������һֱ�ƶ���������Ŀǰ������ GitHub ״̬���� 3200+�� Star���� 32�� Contributors�����ǿ���һ����ͷ���dz���л��ң�ϣ����Ҷ��ܲ��������
��������ϵ���� ITOM��ҵ�����ҵ OneAPM����ʦ������OneAPM �����ڰ�����ҵ�û��ṩȫջʽ�����ܹ����Լ� IT ��ά��������ͨ��һ��̽����ܹ������־��������ȫ������APM ���������ء����ɱ����Լ������ݷ����ȹ��ܡ����Ķ����༼�����£������ OneAPM �ٷ���������
����ת�ԣ�https://news.oneapm.com/tidb-mysql/






























����˵�������а�