 )
)������ȥ����������������һֱæ���������Ӱ��Ĵ����ݿ�Դ������Apache Spark 2.0����Ҫ�汾������������ǰSpark 1.0���������������յ��˺ܶ�������������Spark 2.0���ǻ������ǹ�ȥ��������õľ����ܽ��������ģ������ؼ�ǿ���û�ϲ���Ĺ��ܣ������˴�Ҳ����ĵط��������ܽ���Spark2.0��������Ҫ�Ľ������������١������ܣ�����������ǻ��ں�������������������Щ���⡣
�����ڼ�����������֮ǰ��������ϲ���������ӽ������ҿ�����Databricks����Apache Spark 2.0�ļ���Ԥ���棨�����棩�ˣ������ݰ�ʹ��upstream branch-2.0������ʹ�������dz���ֻҪ��������Ⱥʱѡ��2.0��branch preview�����汾�Ϳ����ˡ�
����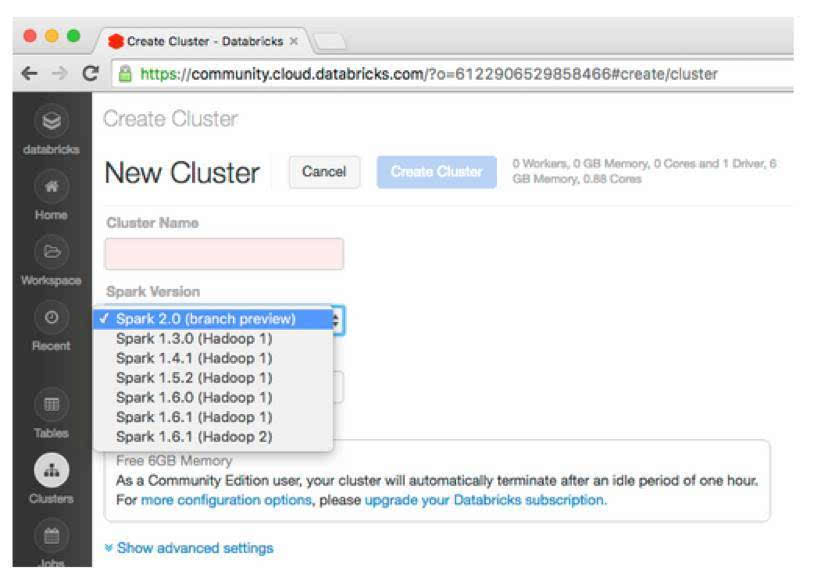
������Databricks����һ����Apache Spark 2.0����Ԥ���漯Ⱥ�Ĺ������̽�ͼ
��������Apache Spark 2.0�����շ��������輸�ܲ��ܳ�¯��������Ԥ����ּ���ô����ǰԤ��һ���°�Ĺ��ܣ�һ���������ҵĺ����ģ�һ����Ҳ���������ڷ������հ�ǰ���ռ�һЩ�û�������bug���档
�������������������µı仯�ɡ�
����
����Spark 2.0�����������١�������
��������SQL���APISpark����������Ϊ����һ�������������API��ֱ�ۡ�����ʹ�ã�Spark 2.0��������һ��ͳ���������������������ƣ�1������SQL֧�֣�2��ͳһ���ݿ�DataFrame��/���ݼ�API��
������SQL���棬�����Ѿ���Spark��SQL���������ش���չ���������µ�ANSI SQL����������֧���Ӳ�ѯ���ܡ� Spark 2.0������������99��TPC-DS��ѯ������SQL��2003�еĺܶ��֧�֣�������SQL��SparkӦ����ʹ�õ���Ҫ�ӿ�֮һ����SQL���ܵ���չ��������˽�����Ӧ����ֲ��Sparkʱ����Ĺ�����
�����ڱ��API���棬���Ǽ���API��
����l ��Scala/Java��ͳһ��DataFrames��Dataset����Spark 2.0��ʼ��DataFramesֻ���У�row�����ݼ���typealias�ˡ�������ӳ�䡢ɸѡ��groupByKey֮������ͷ���������select��groupBy֮��������ͷ�����������Dataset���ࡣ���⣬����¼����Dataset�ӿ��������ṹ����������Structured Streaming���ij�������Python��R�����еı���ʱ���Ͱ�ȫ��compile-time type-safety���������������ԣ����ݼ��ĸ�����Ӧ������Щ����API�С���DataFrame������Ҫ�ı�̳�������Щ�����������ڵ��ڵ�DataFrames�ĸ�����Բ鿴���ݼ�API�ֲ���Щ�˽⡣
����l SparkSession������һ������ڣ�ȡ����ԭ����SQLContext��HiveContext������DataFrame API���û���˵��Spark�����Ļ���Դͷ������ʹ���ĸ���context�������������ʹ��SparkSession�ˣ�����Ϊ������ڿ��Լ������ߡ�ע��ԭ����SQLContext��HiveContext��Ȼ��������֧�����¼��ݡ�
����l �������ܸ��ѵ�Accumulator API�����������һ���µ�Accumulator API�����������Ͳ���ϸ���࣬ͬʱ��ר��֧�ֻ������͡�ԭ����Accumulator API�Ѳ���ʹ�ã���Ϊ�����¼�����Ȼ������
����l �� ��DataFrame�Ļ���ѧϰAPI����Ϊ��ML API���֣���Spark 2.0�У�spark.ml�����䡰�ܵ���API����Ϊ����ѧϰ����ҪAPI���֣�����ԭ����spark.mllib����Ȼ���������Ժ�Ŀ����ص�Ἧ���ڻ���DataFrame��API�ϡ�
����l ����ѧϰ�ܵ��־û��������û����Ա������������ѧϰ�Ĺܵ���ģ���ˣ�Spark�����������ṩ֧�֡�
����l R���Եķֲ�ʽ�㷨�����ӶԹ�������ģ�ͣ�GLM�������ر�Ҷ˹�㷨��NB�㷨�������ع������Survival Regression��������㷨��K-Means����֧�֡�
�����ٶȸ��죺��Spark��Ϊ��������������2015���Spark�ĵ��飬91%���û���Ϊ��Spark��˵����������Ϊ��Ҫ�ġ���ˣ������Ż�һֱ�������ڿ���Sparkʱ�����ǵ��ص㡣�ڿ�ʼSpark 2.0�Ĺ滮ǰ������˼����������⣺ Spark���ٶ��Ѿ��ܿ��ˣ����ܷ�ͻ�Ƽ��ޣ���Spark�ﵽԭ���ٶȵ�10���أ�
��������������⣬������ʵ�������ڹ���Spark����ִ�в���ʱ�ķ�ʽ�������������ִ����������棬����Spark��������MPP���ݿ⣬���ǻᷢ�֣�CPUѭ�����������ù�������ִ�����⺯�����ã�������CPU������ڴ��ȡ/д���м����ݣ�ͨ������CPUѭ���е��˷����Ż����ܣ�һֱ���������ִ��������ϳ�ʱ�������Ĺ����ص㡣
����Spark 2.0�����˵ڶ���Tungsten���棬�������Ǹ����ִ���������MPP���ݿ�������������ģ�������Щ�����������ݴ����У�����Ҫ˼�����������ʱʹ���Ż�����ֽ��룬�������ѯ�ϳ�Ϊ��������������ʹ�����⺯�����ã���������CPU��ע���м����ݡ����ǽ���һ������Ϊ��whole-stage code generation����
�����ڲ��ԡ��Ա�Spark 1.6��Spark 2.0ʱ�������г����ڵ����д����������������ѵ�ʱ�䣨��ʮ�ڷ�֮һ��Ϊ��λ��������ı���֤������һ��Tungsten�����ǿ��Spark 1.6�����������ɼ�����code generation����ʹ�ã���һ���������һЩ�������ҵ���ݿ���Ҳ�����ã��������ǿ�����������ʹ������whole-stage code generation�������ٶȱ�֮ǰ����һ����������
���������ڵ�̨�����϶�10�ڼ�¼ִ����aggregations��joins������
����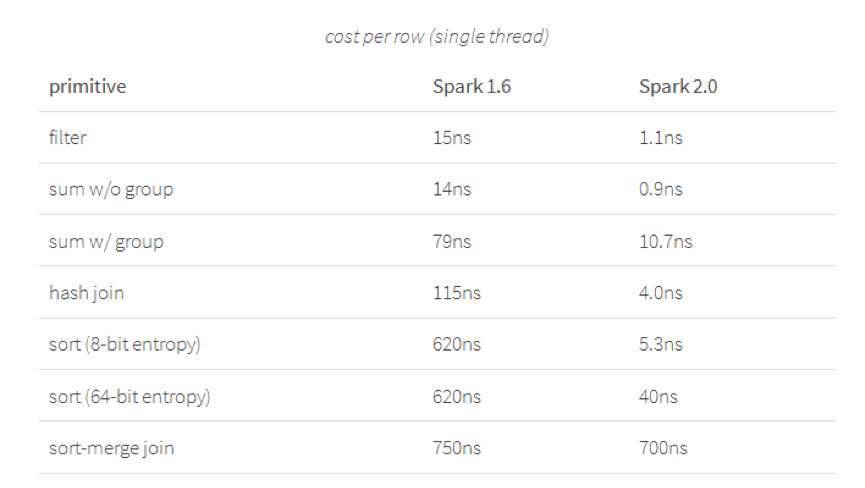
����ÿ�кķѣ����̣߳�
��������µ�������ִ�ж˶Զ˲�ѯʱ����������ģ�����ʹ��TPC-DS��ѯ����Щ�����������ԶԱ�Spark 1.6��Spark 2.0��
����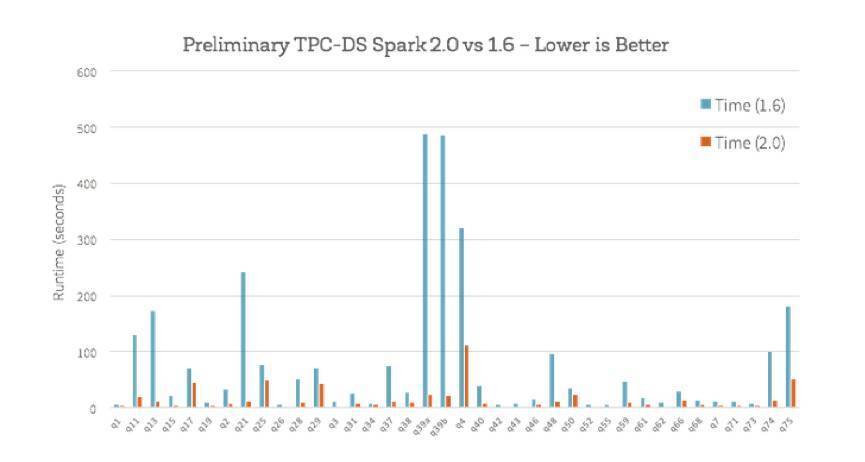
��������֮�⣬Ϊ�˸Ľ�Catalyst optimizer�Ż���������nullability propagation֮�ೣ����ѯ��Ч�������ǻ����������������Ľ���ʸ����Parquet���������½�������������������������
���������ܣ��ṹ����������Ϊ������ͳһ������������������Ĺ��ߣ�Spark Streamingһֱ�Ǵ����ݴ������쵼�ߡ���������API����DStream����Spark 0.7�г������룬��Ϊ�������ṩ��һЩ��ǿ������ԣ�������ֻ��һ�����壬���ģ�ݴ����Լ������¡�
����Ȼ�����ڴ��������ٸ���ʵ�����Spark Streaming����֮�����Ƿ�����Ҫ����ʵ���������ߵ�Ӧ�þ�����Ҫ��ֹһ�����������档������Ҫ���������������ջ����������ջ�������ڲ��洢ϵͳ������Ҫ�д���ҵ�����������������ˣ�����˾��Ҫ��ֹһ�����������棬������Ҫ�������ǿ����˶Զˡ�������Ӧ�á���ȫջϵͳ��
������һ�ֿ����ǽ�����һ�е��������ݣ�Ҳ����˵���õ�һ�ı��ģ���������������������ݡ�
���������ֵ�һ��ģ���У��д�����������֡����ȣ��ڽ��յ����ݵĵ�һʱ����д����dz����ѣ�Ҳ���о����ԡ���Σ���ͬ�����ݷֲ����䶯��ҵ�����������ӳٶ�������ʵ�ʲ�������ս�ԡ��ٴΣ��������ϵͳ����MySQL����Amazon S3����֧����������������еĻ���ѧϰ�㷨��streaming�����ж��������á�
����Spark 2.0�Ľṹ��Streaming API�Ǵ��������ݵ�ȫ�·�ʽ��Դ�ڡ����������м���𰸵����ʽ���Dz��������Dz��������ݡ�������ʵ����Դ�ھ��飺�Ѿ��˽���α�д��̬���ݼ����������ݣ��ij���Աʹ��Sparkǿ���DataFrame/Dataset API���ܽ�����ľ��顣�ṹ����������Ը����������Catalyst�Ż����ҳ�����ʱ���Խ���̬����ת��Ϊ��̬���������ݵ�����ִ�У��������������������ṹ�����ݣ�������ɢ������infinite����ʱ���Ϳ��Լ������������ķ�ʽ��
������Ϊ��һԸ��ʵ�ֵĵ�һ����Spark 2.0�����˳�ʼ�汾�Ľṹ��������API������һ������DataFrame/Dataset API�ϵģ���С����չ����ͳһ֮�����е�Spark�û���˵ʹ�������dz��������ܹ�������Spark ������API�����֪ʶ���ش�ʵʱ�������⡣����ؼ��Ĺ��ܰ�����֧�ֻ����¼�ʱ��Ĵ���������/�ӳ����ݣ�sessionization�Լ�����ʽ����Դ��Sink�Ľ��ܼ��ɡ�
����Streaming��������һ���dz��㷺�Ļ��⣬�����Ҫ�˽�Spark 2.0�нṹ���������ĸ�����Ϣ�����ע�����ͣ���������Spark 2.0�������һЩϸ����������ڵļƻ���
��������Spark���û����ʹ��Spark����Ϊ����������������ܡ�Spark 2.0����Щ����ﵽ��֮ǰ���������������˶Զ��ֹ������ص�֧�֡�����ϣ�����ǵ�Ŭ�����������⣬��ϣ����һ���������
������Ȼ����Apache Spark 2.0���հ淢��֮ǰ�����Dz�������ȫ�����������Ĺ���Ǩ�Ƶ����Ԥ�����ϡ������·�������Databricks�Ͼ������أ������棩����������������ǻ�½��������Databricks�ͻ�������
����ԭ�����ӣ�https://databricks.com/blog/2016/05/11/spark-2-0-technical-preview-easier-faster-and-smarter.html
�������ߣ�Reynold Xin
�������룺��ޱ
����������






























����˵�������а�