 )
)����K-Means����
����ǰ�漸�����ǽ����˼ලѧϰ�������Ӵ���ǩ��������ѧϰ�Ļع�ͷ����㷨�����£����������ලѧϰ�㷨�����ࣨclustering���������������ҳ�������ǩ���ݵ������Ե��㷨�����ǽ�����K-Means����˼�룬���һ��ͼ��ѹ�����⣬Ȼ����㷨��Ч������������������ǰѾ���ͷ����㷨������������һ����ලѧϰ���⡣
�����ڵ�һ�£�����ѧϰ�����У����ǽ��ܹ��Ǽලѧϰ��Ŀ���ǴӲ�����ǩ��ѵ���������ھ������Ĺ�ϵ�����࣬���Ϊ���������cluster analysis����һ�ַ���۲�ķ����������������Ե�������Ϊһ�飬��һ�ࣨcluster����ͬ���е�����������������������ơ���ලѧϰ����һ����������nά������ʾһ���۲�ֵ�����磬�������ѵ����������ͼ��ʾ��
����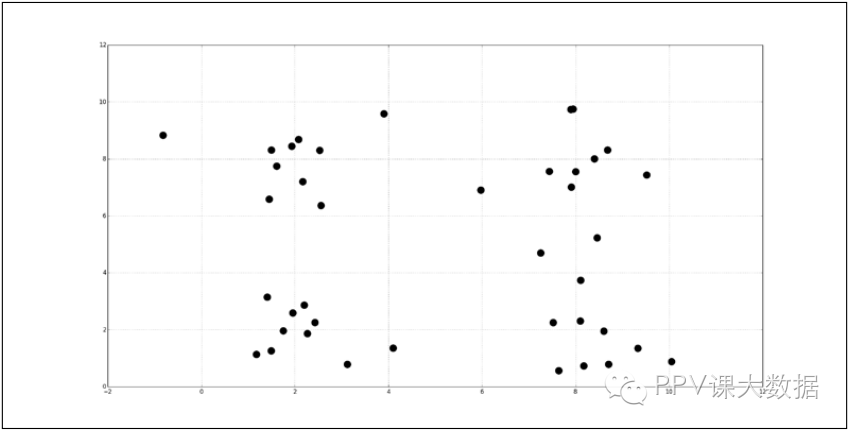
���������㷨���ܻ�ֳ����飬��Բ��ͷ����ʾ������ͼ��ʾ��
����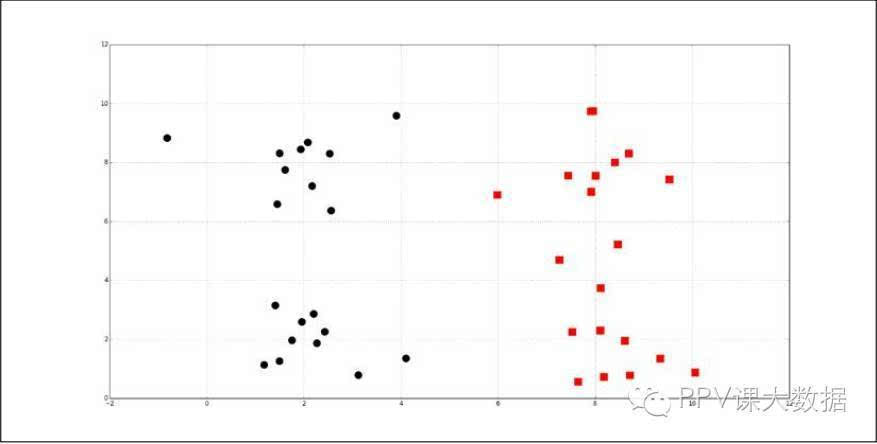
����Ҳ���ֳܷ����飬����ͼ��ʾ��
����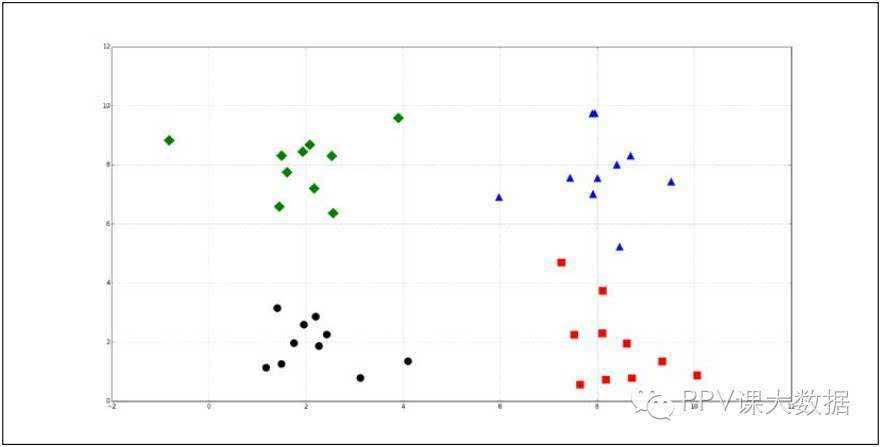
��������ͨ������̽�����ݼ����罻��������þ����㷨ʶ��������Ȼ����û�м����������û������Ƽ���������ѧ�����������ҳ�������ģʽ�Ļ����顣�Ƽ�ϵͳ��ʱҲ���þ����㷨���û��Ƽ���Ʒ��ý����Դ�����г������У������㷨�������û����顣���棬���Ǿ���K-Means�����㷨��Ϊһ�����ݼ����ࡣ
����K-Means�����㷨���
�������ھ��г�ɫ���ٶȺ����õĿ���չ�ԣ�K-Means�����㷨��������������ľ������K-Means�㷨��һ���ظ��ƶ������ĵ�Ĺ��̣���������ĵ㣬Ҳ�����ģ�centroids�����ƶ����������Ա��ƽ��λ�ã�Ȼ�����»������ڲ���Ա��K���㷨������ij���������ʾ���������K-Means�����Զ�������������ͬ���࣬���Dz��ܾ�������Ҫ�ּ����ࡣK������һ����ѵ����������С������������ʱ���������������������ָ���ġ����磬һ��Ь���������¿�ʽ������֪��ÿ���¿�ʽ������ЩDZ�ڿͻ������������пͻ���Ȼ����������ҳ����ࡣҲ��һЩ����û��ָ����������������ŵľ��������Dz�ȷ���ġ��������ǻ����һ������ʽ�������������ž�����������Ϊ�ⲿ����Elbow Method����
����K-Means�IJ������������λ�ú����ڲ��۲�ֵ��λ�á����������ģ�ͺ;��������ƣ�K-Means���������Ž�Ҳ���Գɱ�������С��ΪĿ�ꡣK-Means�ɱ�������ʽ���£�
����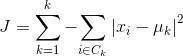
������k�ǵ�k���������λ�á��ɱ������Ǹ��������̶ȣ�distortions��֮�͡�ÿ����Ļ���̶ȵ��ڸ������������ڲ���Աλ�þ����ƽ���͡������ڲ��ij�Ա�˴˼�Խ��������Ļ���̶�ԽС����֮�������ڲ��ij�Ա�˴˼�Խ��ɢ����Ļ���̶�Խ�����ɱ�������С���IJ�������һ���ظ�����ÿ��������Ĺ۲�ֵ���������ƶ������ĵĹ��̡����ȣ�������������ȷ����λ�á�ʵ���ϣ�����λ�õ������ѡ��Ĺ۲�ֵ��λ�á�ÿ�ε�����ʱ��K-Means��ѹ۲�ֵ���䵽������������࣬Ȼ��������ƶ�������ȫ����Աλ�õ�ƽ��ֵ��������������±���ʾ��ѵ������������һ�£�
��������
����X0
����X1
����1 7 5
����2 5 7
����3 7 7
����4 3 3
����5 4 6
����6 1 4
����7 0 0
����8 2 2
����9 8 7
����10 6 8
����11 5 5
����12 3 7
�����ϱ����������ͱ�����ÿ��������������������ͼ������ʾ��
����%matplotlibinlineimportmatplotlib.pyplotaspltfrommatplotlib.font_managerimportFontPropertiesfont=FontProperties(fname=r"c:\windows\fonts\msyh.ttc",size=10)
����importnumpyasnpX0=np.array([7,5,7,3,4,1,0,2,8,6,5,3])X1=np.array([5,7,7,3,6,4,0,2,7,8,5,7])plt.figure()plt.axis([-1,9,-1,9])plt.grid(True)plt.plot(X0,X1,'k.');
����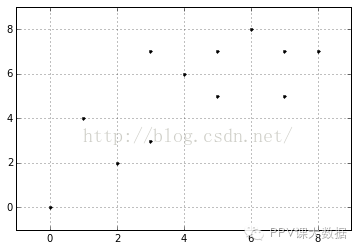
��������K-Means��ʼ��ʱ������һ��������������ڵ�5���������ڶ���������������ڵ�11������.��ô���ǿ���ÿ��ʵ�����������ĵľ��붼���������������䵽����������档���������±���ʾ��
��������
����X0
����X1
������C1����
������C2����
�����ϴξ�����
�����¾�����
�����Ƿ�ı�
����1 7 5 3.16 2.00 None C2 YES
����2 5 7 1.41 2.00 None C1 YES
����3 7 7 3.16 2.83 None C2 YES
����4 3 3 3.16 2.83 None C2 YES
����5 4 6 0.00 1.41 None C1 YES
����6 1 4 3.61 4.12 None C1 YES
����7 0 0 7.21 7.07 None C2 YES
����8 2 2 4.47 4.24 None C2 YES
����9 8 7 4.12 3.61 None C2 YES
����10 6 8 2.83 3.16 None C1 YES
����11 5 5 1.41 0.00 None C2 YES
����12 3 7 1.41 2.83 None C1 YES
����C1���� 4 6
����C2���� 5 5
�����µ�����λ�úͳ�ʼ����������ͼ��ʾ����һ����X��ʾ���ڶ����õ��ʾ������λ�����Դ�ĵ�ͻ����ʾ��
����C1=[1,4,5,9,11]C2=list(set(range(12))-set(C1))X0C1,X1C1=X0[C1],X1[C1]X0C2,X1C2=X0[C2],X1[C2]plt.figure()plt.title('��һ�ε����������',fontproperties=font)plt.axis([-1,9,-1,9])plt.grid(True)plt.plot(X0C1,X1C1,'rx')plt.plot(X0C2,X1C2,'g.')plt.plot(4,6,'rx',ms=12.0)plt.plot(5,5,'g.',ms=12.0);
����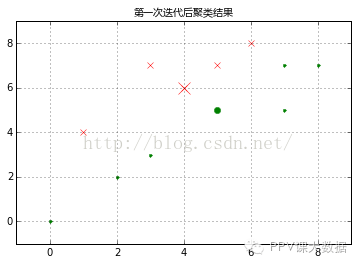
���������������¼�������������ģ��������ƶ�����λ�ã������¼�����������������ĵľ��룬�����ݾ���Զ��Ϊ�������¹��ࡣ������±���ʾ��
��������
����X0
����X1
������C1����
������C2����
�����ϴξ�����
�����¾�����
�����Ƿ�ı�
����1 7 5 3.49 2.58 C2 C2 NO
����2 5 7 1.34 2.89 C1 C1 NO
����3 7 7 3.26 3.75 C2 C1 YES
����4 3 3 3.49 1.94 C2 C2 NO
����5 4 6 0.45 1.94 C1 C1 NO
����6 1 4 3.69 3.57 C1 C2 YES
����7 0 0 7.44 6.17 C2 C2 NO
����8 2 2 4.75 3.35 C2 C2 NO
����9 8 7 4.24 4.46 C2 C1 YES
����10 6 8 2.72 4.11 C1 C1 NO
����11 5 5 1.84 0.96 C2 C2 NO
����12 3 7 1.00 3.26 C1 C1 NO
����C1���� 3.80 6.40
����C2���� 4.57 4.14
������ͼ������£�
����C1=[1,2,4,8,9,11]C2=list(set(range(12))-set(C1))X0C1,X1C1=X0[C1],X1[C1]X0C2,X1C2=X0[C2],X1[C2]plt.figure()plt.title('�ڶ��ε����������',fontproperties=font)plt.axis([-1,9,-1,9])plt.grid(True)plt.plot(X0C1,X1C1,'rx')plt.plot(X0C2,X1C2,'g.')plt.plot(3.8,6.4,'rx',ms=12.0)plt.plot(4.57,4.14,'g.',ms=12.0);
����
�����������ظ�һ��������������������ƶ�����λ�ã������¼�����������������ĵľ��룬�����ݾ���Զ��Ϊ�������¹��ࡣ������±���ʾ��
��������
����X0
����X1
������C1����
������C2����
�����ϴξ�����
�����¾�����
�����Ƿ�ı�
����1 7 5 2.50 5.28 C1 C1 NO
����2 5 7 0.50 5.05 C1 C1 NO
����3 7 7 1.50 6.38 C1 C1 NO
����4 3 3 4.72 0.82 C2 C2 NO
����5 4 6 1.80 3.67 C1 C1 NO
����6 1 4 5.41 1.70 C2 C2 NO
����7 0 0 8.90 3.56 C2 C2 NO
����8 2 2 6.10 0.82 C2 C2 NO
����9 8 7 2.50 7.16 C1 C1 NO
����10 6 8 1.12 6.44 C1 C1 NO
����11 5 5 2.06 3.56 C2 C1 YES
����12 3 7 2.50 4.28 C1 C1 NO
����C1���� 5.50 7.00
����C2���� 2.20 2.80
������ͼ������£�
����C1=[0,1,2,4,8,9,10,11]C2=list(set(range(12))-set(C1))X0C1,X1C1=X0[C1],X1[C1]X0C2,X1C2=X0[C2],X1[C2]plt.figure()plt.title('��������������',fontproperties=font)plt.axis([-1,9,-1,9])plt.grid(True)plt.plot(X0C1,X1C1,'rx')plt.plot(X0C2,X1C2,'g.')plt.plot(5.5,7.0,'rx',ms=12.0)plt.plot(2.2,2.8,'g.',ms=12.0);
����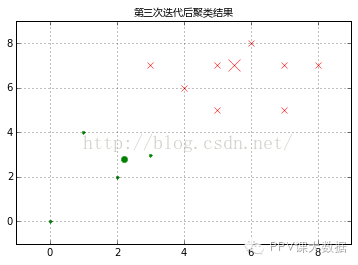
�������ظ�����ķ����ͻᷢ��������IJ����ˣ�K-Means�������������ʱ��ֹͣ�ظ�������̡�ͨ����������ǰ�����ε����ijɱ�����ֵ�IJ�ﵽ����ֵ��������ǰ�����ε���������λ�ñ仯�ﵽ����ֵ�������Щֹͣ�����㹻С��K-Means�����ҵ����Ž⡣����������Žⲻһ����ȫ�����Ž⡣
�����ֲ����Ž�
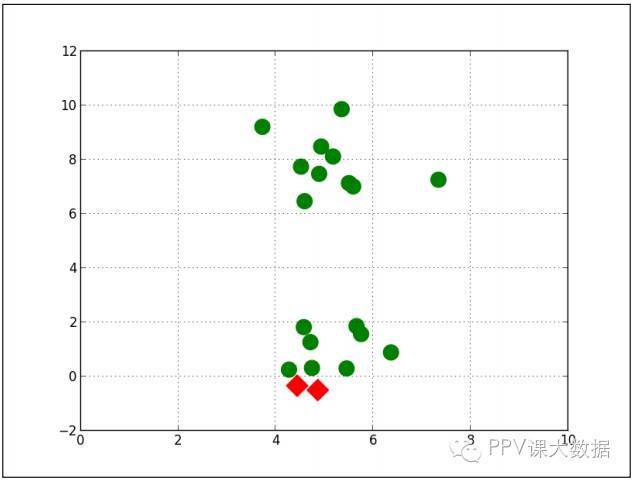
����ǰ����ܹ�K-Means�ij�ʼ����λ�������ѡ��ġ���ʱ������������ã����ѡ������Ļᵼ��K-Means����ֲ����Ž⡣���磬K-Means��ʼ����λ������ͼ��ʾ��
����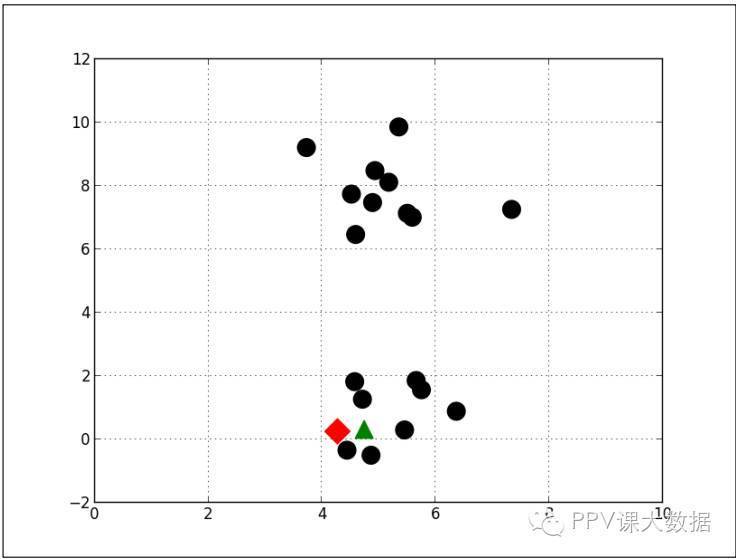
����K-Means���ջ�õ�һ���ֲ����Ž⣬����ͼ��ʾ����Щ�����û��ʵ�����壬����������������ֹ۲�ֵ�����Ǹ��к����ľ�������Ϊ�˱���ֲ����Ž⣬K-Meansͨ����ʼʱҪ�ظ�����ʮ���������ϰٴΡ�ÿ���ظ�ʱ����������ĴӲ�ͬ��λ�ÿ�ʼ��ʼ����������С�ijɱ�������Ӧ������λ����Ϊ��ʼ��λ�á�
����
�����ⲿ����
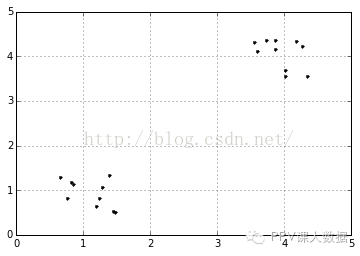
�������������û��ָ��KK��ֵ������ͨ���ⲿ������һ���������ƾ����������ⲿ�����Ѳ�ͬKKֵ�ijɱ�����ֵ������������KKֵ������ƽ������̶Ȼ��С��ÿ�������������������٣����������������Ļ���������ǣ�����KKֵ��������ƽ������̶ȵĸ���Ч����ϼ��͡�KKֵ��������У�����̶ȵĸ���Ч���½���������λ�ö�Ӧ��KKֵ�����ⲿ���������������ⲿ������ȷ����ѵ�KKֵ����ͼ�������Կɷֳ����ࣺ
����importnumpyasnpcluster1=np.random.uniform(0.5,1.5,(2,10))cluster2=np.random.uniform(3.5,4.5,(2,10))X=np.hstack((cluster1,cluster2)).Tplt.figure()plt.axis([0,5,0,5])plt.grid(True)plt.plot(X[:,0],X[:,1],'k.');
����
�������Ǽ���Kֵ��1��10��Ӧ��ƽ������̶ȣ�
����fromsklearn.clusterimportKMeansfromscipy.spatial.distanceimportcdistK=range(1,10)meandistortions=[]forkinK:kmeans=KMeans(n_clusters=k)kmeans.fit(X)meandistortions.append(sum(np.min(cdist(X,kmeans.cluster_centers_,'euclidean'),axis=1))/X.shape[0])plt.plot(K,meandistortions,'bx-')plt.xlabel('k')plt.ylabel('ƽ������̶�',fontproperties=font)plt.title('���ⲿ������ȷ����ѵ�Kֵ',fontproperties=font);
����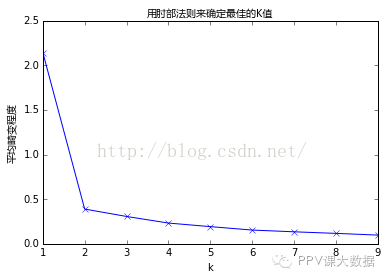
������ͼ�п��Կ�����Kֵ��1��2ʱ��ƽ������̶ȱ仯�����2�Ժ�ƽ������̶ȱ仯�������͡�����ⲿ����K=2���������������ⲿ������ȷ��3�������ѵ�Kֵ��
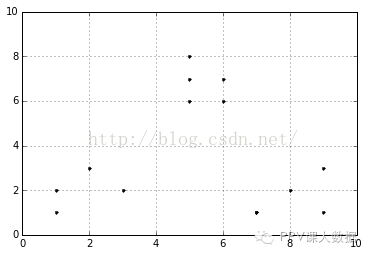
����importnumpyasnpx1=np.array([1,2,3,1,5,6,5,5,6,7,8,9,7,9])x2=np.array([1,3,2,2,8,6,7,6,7,1,2,1,1,3])X=np.array(list(zip(x1,x2))).reshape(len(x1),2)plt.figure()plt.axis([0,10,0,10])plt.grid(True)plt.plot(X[:,0],X[:,1],'k.');
����
����fromsklearn.clusterimportKMeansfromscipy.spatial.distanceimportcdistK=range(1,10)meandistortions=[]forkinK:kmeans=KMeans(n_clusters=k)kmeans.fit(X)meandistortions.append(sum(np.min(cdist(X,kmeans.cluster_centers_,'euclidean'),axis=1))/X.shape[0])plt.plot(K,meandistortions,'bx-')plt.xlabel('k')plt.ylabel('ƽ������̶�',fontproperties=font)plt.title('���ⲿ������ȷ����ѵ�Kֵ',fontproperties=font);
����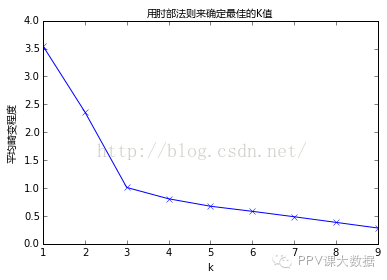
������ͼ�п��Կ�����Kֵ��1��3ʱ��ƽ������̶ȱ仯�����3�Ժ�ƽ������̶ȱ仯�������͡�����ⲿ����K=3��
��������������
�������ǰѻ���ѧϰ����Ϊ��ϵͳ����ƺ�ѧϰ��ͨ���Ծ������ݵ�ѧϰ��������Ч���IJ��ϸ�����Ϊһ����������K-Means��һ�ַǼලѧϰ��û�б�ǩ��������Ϣ���ȽϾ����������ǣ����ǻ�����һЩָ����������㷨�����ܡ������Ѿ����ܹ���Ļ���̶ȵĶ�������������Ϊ��������һ�־����㷨Ч������������Ϊ����ϵ����Silhouette Coefficient��������ϵ��������ܼ����ɢ�̶ȵ�����ָ�ꡣ����������Ĺ�ģ��������˴�����Զ���������ܼ����࣬������ϵ���ϴ˴˼��У������ܴ���࣬������ϵ����С������ϵ����ͨ������������������ģ�����ÿ�����������ľ�ֵ�����㹫ʽ���£�
����s=b-amax(a,b)
����a��ÿһ�����������˴˾���ľ�ֵ��b��һ��������������������Ǹ�������������ľ���ľ�ֵ����������������Ĵ�K-Means����һ�����ݼ��зֱ�2��3��4��8���࣬Ȼ��ֱ�������ǵ�����ϵ����
����importnumpyasnpfromsklearn.clusterimportKMeansfromsklearnimportmetricsplt.figure(figsize=(8,10))plt.subplot(3,2,1)x1=np.array([1,2,3,1,5,6,5,5,6,7,8,9,7,9])x2=np.array([1,3,2,2,8,6,7,6,7,1,2,1,1,3])X=np.array(list(zip(x1,x2))).reshape(len(x1),2)plt.xlim([0,10])plt.ylim([0,10])plt.title('����',fontproperties=font)plt.scatter(x1,x2)colors=['b','g','r','c','m','y','k','b']markers=['o','s','D','v','^','p','*','+']tests=[2,3,4,5,8]subplot_counter=1fortintests:subplot_counter+=1plt.subplot(3,2,subplot_counter)kmeans_model=KMeans(n_clusters=t).fit(X)fori,linenumerate(kmeans_model.labels_):plt.plot(x1[i],x2[i],color=colors[l],marker=markers[l],ls='None')plt.xlim([0,10])plt.ylim([0,10])plt.title('K = %s, ����ϵ�� = %.03f'%(t,metrics.silhouette_score(X,kmeans_model.labels_,metric='euclidean')),fontproperties=font)
����d:\programfiles\Miniconda3\lib\site-packages\numpy\core\_methods.py:59: RuntimeWarning: Mean of empty slice. warnings.warn("Mean of empty slice.", RuntimeWarning)
����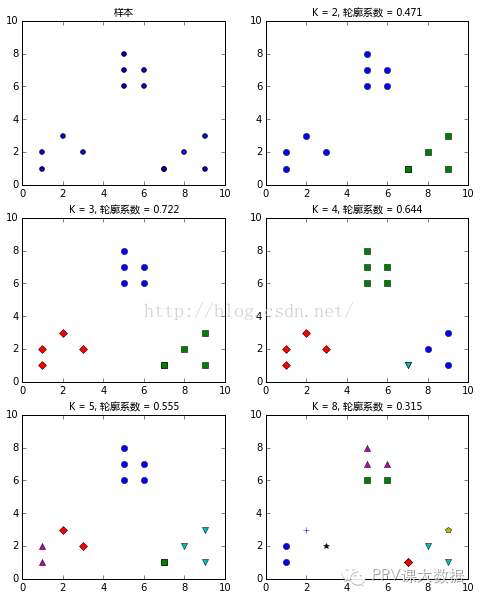
��������Ȼ��������ݼ����������ࡣ��K=3K=3��ʱ������ϵ�������ġ���K=8K=8��ʱ��ÿ��������������˴˺ܽӽ��������������������Ҳ�dz��ӽ��������ʱ����ϵ������С�ġ�
����ͼ������
����ǰ�������þ����㷨̽���˽ṹ�����ݼ��������������������һ�������⡣ͼ��������image quantization����һ�ֽ�ͼ����������ɫ�滻��ͬ����ɫ������ѹ��������ͼ�����������ͼ��Ĵ洢�ռ䣬���ڱ�ʾ��ͬ��ɫ���ֽڼ����ˡ�����������У����ǽ��þ������һ��ͼƬ���ҳ�����ͼƬ�������ɫ��ѹ����ɫ��ɫ�壨palette����Ȼ�����������ѹ����ɫ��ɫ����������ͼƬ�����������Ҫ��mahotasͼ�����⣬����ͨ��pip install mahotas��װ��
����importnumpyasnpfromsklearn.clusterimportKMeansfromsklearn.utilsimportshuffleimportmahotasasmh
�������ȣ�����ͼƬ��Ȼ��ͼƬ����չ����һ����������
����original_img=np.array(mh.imread('mlslpic\6.6 tree.png'),dtype=np.float64)/255original_dimensions=tuple(original_img.shape)width,height,depth=tuple(original_img.shape)image_flattened=np.reshape(original_img,(width*height,depth))
����Ȼ��������K-Means�㷨�����ѡ��1000����ɫ�����н���64���ࡣÿ���������ѹ����ɫ���е�һ����ɫ��
����image_array_sample=shuffle(image_flattened,random_state=0)[:1000]estimator=KMeans(n_clusters=64,random_state=0)estimator.fit(image_array_sample)
����KMeans(copy_x=True, init='k-means++', max_iter=300, n_clusters=64, n_init=10, n_jobs=1, precompute_distances='auto', random_state=0, tol=0.0001, verbose=0)
����֮������ΪԭʼͼƬ��ÿ�����ؽ�����ķ��䡣
����cluster_assignments=estimator.predict(image_flattened)
����������ǽ���ͨ��ѹ����ɫ��������������ѹ�����ͼƬ��
����compressed_palette=estimator.cluster_centers_compressed_img=np.zeros((width,height,compressed_palette.shape[1]))label_idx=0foriinrange(width):forjinrange(height):compressed_img[i][j]=compressed_palette[cluster_assignments[label_idx]]label_idx+=1plt.subplot(122)plt.title('Original Image')plt.imshow(original_img)plt.axis('off')plt.subplot(121)plt.title('Compressed Image')plt.imshow(compressed_img)plt.axis('off')plt.show()
����
����ͨ������ѧϰ����
����������������У����ǽ�����ͷ�����������о�һ����ලѧϰ���⡣�㽫�Բ�����ǩ�����ݽ��о��࣬���һЩ������Ȼ������Щ����������һ���ල������������
������������һֻè��һ�������ټ���������һ�������ֻ��������Ͽ����������˴�绰�ģ���ʵ��ֻ��������è�����ա������Ƭ�ĵúܰ�����������������Ѻ�ͬ��һ����ϲ�����ǡ�����֪��һ������ֻ�뿴è����Ƭ��һ������ֻ�뿴������Ƭ������Ҫ����Щ��Ƭ����̫�鷳�ˡ��������Ǿ���һ����ලѧϰϵͳ���ֱ�è������Ƭ��
��������һ�µ����£�������ȡ�봦�������ݣ���һ��ԭʼ�ķ�������ͼƬ���࣬����ͼƬ�������ܶ�ֵ������ֵ��Ϊ���ͱ�����������ǰ������ı�����ʱ�ĸ�ά������ͬ��ͼƬ��������������ϡ��ġ����⣬���������ͼƬ�����ȣ��ߴ磬��ת�ı仯��ʮ�����С��ڵ����£�������ȡ�봦�����棬���ǻ�������SIFT��SURF����������������ͼƬ����Ȥ�㣬�������ͼƬ�����ȣ��ߴ磬��ת�仯�������С�������������У����ǽ��þ����㷨������Щ��������ѧϰͼƬ��������ÿ��Ԫ�ؽ�������ɴ�ͼƬ�г�ȡ�ģ������䵽ͬһ����������������������ַ�����ʱҲ��Ϊ�Ӿ��ʴ���bag-of-features����ʾ�������������ļ�����ʴ�ģ����Ĵʻ�����ơ����ǽ�ʹ��Kaggle's Dogs vs. Cats competition�����1000��èͼƬ��1000�Ź�ͼƬ���ݡ�ע�⣬ͼƬ�в�ͬ�ijߴ磻�������ǵ����������������ر�ʾ����������Ҳ����Ҫ������ͼƬ�����ų�ͬ���ijߴ硣���ǽ�ѵ������60��ͼƬ��Ȼ����ʣ�µ�40ͼƬ�����ԣ�
����importnumpyasnpimportmahotasasmhfrommahotas.featuresimportsurffromsklearn.linear_modelimportLogisticRegressionfromsklearn.metricsimport*fromsklearn.clusterimportMiniBatchKMeansimportglob
�������ȣ����Ǽ���ͼƬ��ת���ɻҶ�ͼ���ٳ�ȡSURF��������SURF���������������Ƶ�������ȣ����Ը���ı���ȡ�����Ǵ�2000��ͼƬ�г�ȡ��������Ȼ�Ǻܷ�ʱ��ġ�
����all_instance_filenames=[]all_instance_targets=[]forfinglob.glob('cats-and-dogs-img/*.jpg'):target=1if'cat'infelse0all_instance_filenames.append(f)all_instance_targets.append(target)surf_features=[]counter=0forfinall_instance_filenames:print('Reading image:',f)image=mh.imread(f,as_grey=True)surf_features.append(surf.surf(image)[:,5:])train_len=int(len(all_instance_filenames)*.60)X_train_surf_features=np.concatenate(surf_features[:train_len])X_test_surf_feautres=np.concatenate(surf_features[train_len:])y_train=all_instance_targets[:train_len]y_test=all_instance_targets[train_len:]
����Ȼ�����ǰѳ�ȡ���������ֳ�300���ࡣ��MiniBatchKMeans��ʵ�֣�����K-Means�㷨�ı��֣�ÿ�ε����������ȡ����������ÿ�ε�����ֻ������Щ�������ȡ��һС�������������ĵľ��룬���MiniBatchKMeans���Ը���ľ��࣬�������Ļ���̶Ȼ����ʵ���ϣ���������ࣺ
����n_clusters=300print('Clustering',len(X_train_surf_features),'features')estimator=MiniBatchKMeans(n_clusters=n_clusters)estimator.fit_transform(X_train_surf_features)
����֮������Ϊѵ�����Ͳ��Լ��������������������ҳ�ÿһ��SURF���������࣬��Numpy��binCount()���м���������Ĵ���Ϊÿ����������һ��300ά������������
����X_train=[]forinstanceinsurf_features[:train_len]:clusters=estimator.predict(instance)features=np.bincount(clusters)iflen(features)<n_clusters:features=np.append(features,np.zeros((1,n_clusterslen(features))))X_train.append(features)X_test=[]forinstanceinsurf_features[train_len:]:clusters=estimator.predict(instance)features=np.bincount(clusters)iflen(features)<n_clusters:features=np.append(features,np.zeros((1,n_clusterslen(features))))X_test.append(features)
�����������������������Ŀ����ѵ��һ�����ع��������Ȼ��������ľ�ȷ�ʣ��ٻ��ʺ�ȷ�ʣ�
����clf=LogisticRegression(C=0.001,penalty='l2')clf.fit_transform(X_train,y_train)predictions=clf.predict(X_test)print(classification_report(y_test,predictions))print('Precision: ',precision_score(y_test,predictions))print('Recall: ',recall_score(y_test,predictions))print('Accuracy: ',accuracy_score(y_test,predictions))
������ලѧϰϵͳ����ʹ�������ܶ���Ϊ�����������ͻ���˱����ع���������õľ�ȷ�ʺ��ٻ��ʡ����ң����ǵ���������ֻ��300ά����100x100����ͼƬ��10000άҪС�öࡣ
�����ܽ�
�������£����ǽ��������ǵĵ�һ���ලѧϰ���������ࡣ����������̽���ޱ�ǩ���ݵĽṹ�ġ����ǽ�����K-Means�����㷨���ظ�����������������棬���ϵĸ����������λ�á���ȻK-Means���ලѧϰ��������Ч����Ȼ�ǿ��Զ����ģ��û���̶Ⱥ�����ϵ��������������Ч����������K-Means�о����������⡣��һ������ͼ��������һ���õ�һ��ɫ��ʾһ��������ɫ��ͼ��ѹ�����������ǻ���K-Means�о��˰�ලͼ����������������
������һ�£����ǽ�������һ���ලѧϰ������ά��dimensionality reduction����������ǰ����ܹ��İ�ලè��ͼ������������ƣ���ά�㷨�����ھ���������Ϣ�����Ե�ͬʱ�����ͽ��ͱ������ϵ�ά�ȡ�
����������飺��ѩҹ���ӣ�Ӣ����: Allen��������ѧϰ�㷨����ʨ��ϲ������Machine Learning�ĺڿƼ�����Deep Learning��Artificial Intelligence������Ȥ��������עkaggle�����ھ���ƽ̨�������ݡ�Machine Learning��Artificial Intelligence����Ȥ�ĸ�λͯЬ����һ��̽�֡�






























����˵�������а�