 )
)���ԣ�Nicol�IJ������������ӣ�https://taozj.org/2016/04/�Ƽ�ϵͳ���õ��Ƽ��㷨/�����β���Ķ�ԭ��ǰ����
������һλ�㷨ʦ����ʦ��Spark����ѧϰ�ʼǣ�����һ�����Ƽ�ϵͳ��
�������Ƽ�ϵͳ�ĵ����Ƽ�������
�����������Ƽ��㷨ʵ����
����һ���Ƽ�ϵͳ�����ͳ�������ָ��
����1.1 �Ƽ�ϵͳ���ص�
������֪������һ���Ƽ�ϵͳ���������Ƚ��٣��Ե�С��һЩ��Ȼ���Ҷ��Ƽ�ϵͳ�ձ�Ĺ۵��ǣ�
����(1)��Ҫ��UI>����>�㷨�������Ƽ�ϵͳ��һζ���Ƚ����㷨���Ǹ�������ͨ�������о�����Ƽ������еĴ��кܶ�ļ������ƣ��еĿ��ǹ���ʵ��������٣��Ƽ�ϵͳ��Ҫ����������������ת����ͬʱ����Ҫ���ǹ�˾ҵ�������Լ�������ϵͳ�ļ��ɣ������γ��Ƽ�ϵͳ��ҵ��֮�������ѭ����
����(2)�Ƽ�ϵͳ���߲��Ժܺã����ߺ�Ҫôû���ϸ�IJ��Խ����ֻ��ƾ�о���Ҫôʵ��Ч����ǿ���⣬������ҪԵ�����߲��ԱȽ����룬������AB�ھ��������۶���ǰ�˻��Ǻ�̨Ҫ�ܸߣ�û���ۺ���з�ʵ������ʵ�֣�
����(3)�Ƽ�ϵͳ�ܵ����ⲿ���������ر�ࣨ���ڡ��������صȣ�������ϵͳ��Ҫ���ϵĵ������£�û��һ�����ݵ����顣

����1.2 �Ƽ�ϵͳ������ָ��
���������Ƽ�ϵͳ�Ƚϸ��ӣ������漰��������ָ��Ҳ�ܶࡣ��Ȼ���û��������Ϊ����Ч����Ϊ�Ȿ�������Ƽ�ϵͳ������Ŀ�꣬�����κ���Դ���ɱ�̫�ߣ��Ƽ�ϵͳ������������������ָ�ꡣ
����(1)�Ƽ�ȷ�ȣ���������������������ã����ҽ�Ϊ�Ŀۣ������Ǹ����о������㷨����Ҫ�IJο�ָ�ꡣ������˵���Ƽ�ϵͳ����������Ԥ�⡱�͡��Ƽ����������Ƽ�ϵͳȷ�ȵ����ְ�����
����Ԥ�⣺ѧϰ�û�������ģ�ͣ�����Ԥ���û�����δ�Ӵ���������֣���ʵ���Կ�����һ���ع�ģ�ͣ�һ���þ����������߾��������������
TopN�Ƽ������û�һ�����Ի����Ƽ��б�����һ��ͨ��ȷ�ȡ��ٻ��ʵ�ָ������������NҲ��һ���ɱ���������Ը��ݲ�ͬ��N������Ӧ�㷨��ROC��������һ�������Ƽ�Ч����
����(2)�����ʣ��������ھ��㷨�Է���β��Ʒ����������Ķ����ǣ��������û��Ƽ����IJ�Ʒ��������Ȼ��������ֵIJ�����Ʒ���ܲ�Ʒ������ռ�ı��������ַ�ʽ�ȽϵĴ���������Ϊ�Ƽ�ϵͳ����̫ЧӦƵ�������Ժõ��Ƽ��㷨Ӧ����������Ʒ���Ƽ��ļ��ʲ�࣬�������ҵ����Ժ��ʵ��û�������ʵ���лῼ����Ϣ�ء�����ϵ����ָ�ꡣ
����(3)�����ԣ���ԭ�����Ա���Ϊ����һ�����ϵ������������Ƽ�ϵͳ�漰��������̫�࣬���ֻ�Ƽ��û�һ������������Ʒ��ʧ�ܷ��ձȽϵĴ���Ҳ����ʵ�������Ƽ�Ч������
����(4)��ӱ�ԣ�ԭ��������Щ�û�û�нӴ�����û�в���������Ʒ�����������жȱȽϵ͵���Ʒ�����û���˵�DZȽ����ʵ���Ʒ���������������Ч�������˾������ָ���е㳶~~
����(5)���ζȣ����ָ��Ƚϵ����ۣ��������û������Ƽ�ϵͳ�������Ƽ����и��������ɵģ��Լ��Ƽ�ϵͳ�ڲ�����������ġ���������ѷ����Ʒ�Ƽ�������Ƽ����ɣ���Ϊ�û����һ���ú����ģ������û�������̼ҵ��������������еִ�������
����(6)��׳�ԣ�������Թ����Ƽ��㷨���̻������µ���߲�Ʒ���Ƽ�Ƶ�ʣ�ˮ���������۵ȡ�
����������̬�����Ƽ�
���������Ͼ�������㷨���������û�-��Ʒ�Ľ������ݶ�̬���ɸ��Ի����Ƽ�������̬����ָ��û�����û��������ݵ�ʱ�����������ϵͳ��������ʱ����Ϊ�ij���������ʹ�õľ�̬���ݰ�����
����(1)�û�ע��ʱ����Ա����䡢����ѧ������Ȥ���˿�ͳ��ѧ��Ϣ��
����(2)��Ȩ���罻�����˺ŵĺ�����Ϣ��
������������Ƽ����������Ը���ÿ���û�Ԥ�����ú��������ݣ�Ҳ���Ը���ͬ���û��֮��������ͣ��������ַ����������Ƽ������Ƚϴ����漰����Ʒζ���õĸ��Ի�ǿ����Ʒ���ο���ֵ���ޣ�ͬʱ�ڴ����˽��ʶ��ǿ������£��������ݲ������ܹ����õ����ڶ����罻���������ϢЧ����ȽϺã���Ҳ��Ҫ��Ӧ��ƽ̨��Ȩ����ſ��ԡ�
����Ȼ����������������¼�����û����¼������Ʒ�����������⣺
�¼����û�������������Ʒ��ѡ���������˿�ͳ����Ϣ���д����ȵ����ͣ�������Եõ����������ݣ���ȡ�������Ϣ��ѡ��ӽ��ĺ��ѽ���UserCF�Ƽ������û�չʾһЩ��Ʒ�����dz��������д����Ժ������ԡ���ƷҪ�����ԣ����õ��û��ķ�����Ȼ�����ѧϰ��Nadav Golbandi�㷨����
�¼�����Ʒ��UserCF���¼������Ʒ���������Ǻ����У���ΪֻҪ���û������������Ʒ���������Ʒ�ͻ�������ɢ����������ItemCF�ͱȽ����أ�������Կ��ǿ�ʼʹ�û������ݵ��Ƽ����Ȼ�������һ���̶Ⱥ��л���Эͬ����������
���������������ݵ��Ƽ�
��������Ҫ�����û�֮ǰ��ϲ�ã��Ƽ����Ƶ���Ʒ����ϵͳ�����û����ԺͲ�Ʒ���������湹�ɣ�ǰ�߰����û��Ĺ������ԣ������˿�ͳ����Ϣ���Լ��û�����ʷ��Ʒ������Ϣ������Կ�����Ӱ�����֣�Ȼ��õ����û�����ϲ����Ӱ�������������������Ƕ���Ʒ�ı�����������������ͨ�����������ƶȾͿ���ʵ���Ƽ��ˡ�ͬʱҲ�ܸо���������ͬ���͵���Ʒ����ά�����ƣ������㷨�Ṥ���ıȽϺã����ڵ���ǧ��ٹֵ���Ʒ�����ܹ���Ч��һ�㡣
���������������Ҫ������������Ƽ��Ƿ���������ԣ���������û�֮ǰ�İ���ֻ�����Ƽ�ͬ��IJ�Ʒ����Ȼ�����Ƽ�ϵͳ�ļ�ֵ��ʮ�����ޣ����������ȷ�Ƽ�������ͬ������Ʒ�ͻ�ܺ��ˡ�
����Pandora�������Ƽ����Ǹ����͵Ļ������ݵ��Ƽ�ϵͳ�����ǰ�����ʹ�ø���ά�ȵ����Խ���������Ȼ������û�֮ǰ����Ȥ�����Ƽ��������Է������֡�
�����ġ�Эͬ�����㷨
����Эͬ�����㷨�����Ƽ�ϵͳ�������㷨�ˣ�Ҳ��Ϊ����������㷨��Эͬ����ǣ�浽�û�����Ʒ�Ľ�����Ϣ��Ҳ�����û���Ϊ����һ���û�������Ʒ����Ϊ�����У�
�������Է�����Ϊ�����û���ȷ���ֳ���ij���Ʒ�͵�ϲ�ã������û�����Ʒ�Ĵ�֡����۵���Ϣ��
�������Է�����Ϊ����������ȷ�����û��Բ�Ʒϲ�õ���Ϊ������ҳ�������Ϊ�ȣ������������ıȽ϶࣬�������д�������������Ҫ����������ת���ſ�����ʵ�ʵ���;��
����4.1 �����û���Эͬ�����㷨(UserCF)
��������ڵļ����ǡ���ϲ��������Ʒ���û���������ͬ�������ƵĿ�ζ��ƫ�á�UserCFʵ�ֵIJ��������
����(1)�ҵ���Ŀ���û���Ȥ���Ƶ��û�Ⱥ��
���������û�u��v������������Ʒ����ΪN(u)��N(v)����ô������Ȥ���ƶȿ��Լ�Ϊ
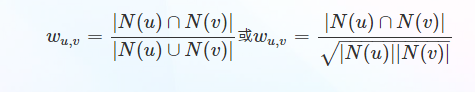
����(2)�ҵ�����������û�ϲ���ģ���Ŀ���û�û����˵������Ʒ�Ƽ�֮��
����UserCF�ṩ��һ������K��ʾҪ����Ŀ���û���Ȥ�����Ƶ��˵ĸ������ڱ�֤���ȵ�ͬʱ��K���˹������Ƽ������������������Ʒ�����ж�ָ����Ƕ�ָ�궼�ή�͡�
����4.2 �������ݵ�Эͬ�����㷨(ItemCF)
����Ŀǰ�õ���㷺���Ƽ��㷨������ͨ����Ʒ����������ͨ���û�����Ʒ����Ϊ��������Ʒ֮������ƶȣ�������ܹ������û���Ȥ����Ʒ���ض�����֮ǰ���ָߵ���Ʒ���ơ�ItemCF�IJ������������
����(1)������Ʒ֮������ƶȡ�
������Ʒ���ƶȿ��Ա�ʾΪ����ʵ��ǰ���֧�ֶȱȽ���
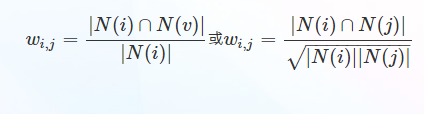
�����ڶ���ʽ�ӱȵ�һ��ʽ�Ӻ��ڿ��Գͷ����Ȳ�Ʒj��
����(2)������Ʒ�����ƶȺ��û�����ʷ��Ϊ�����û������Ƽ��б���
����4.3 ����ģ�͵�Эͬ�����㷨
����User-CF��Item-CF�ϳ�Ϊmemory-based CF����model-based CFʹ��һ�����ѧϰ�ķ�ʽ��������������û�ϲ����Ϣ��ѵ����һ���Ƽ�ģ�ͣ�Ȼ�����ʵʱ���û�ϲ�õ���Ϣ����Ԥ��ͼ����Ƽ���
�������õ�ģ�Ͱ���LSI����Ҷ˹����ȡ�
����4.4 UserCF��ItemCF֮��ıȽ�
��������ʵ������У�������Ʒ�ĸ�����ԶԶС���û��������ģ�������Ʒ�ĸ��������ƶ���ԱȽ��ȶ�������������ɹ��������������Լ��㲽�裬�Ӷ���������������������û���ʵʱ�Ը���һЩ�����Ǿ���ʹ�õij���������Ҫ���ݾ����ҵ�����������֣�User-CFƫ���ڷ�Ӧ�û�СȺ���ȵ㣬������ữ����Item-CF����ά���û�����ʷ��Ȥ�����磺
�����������š��Ķ�����Ƽ��������Ķ������Ϣ��ʵʱ���µģ�����ItemCF�������������Ҫ���ϸ��£����û������ŵĸ��Ի��Ƽ������ر��ǿ��������û�������Ϊ���ᵼ�������û��ľ����˶���
�������ڵ����������ģ������û����Ѵ��۱Ƚϸߣ����ԶԸ��Ի��ľ�ȷ�̶�Ҫ��Ҳ�Ƚϸߣ���һ���û����µ���Ϊ��Ҳ�ᵼ���Ƽ����ݵ�ʵʱ�仯
����Эͬ���˵��㷨ȱ��Ҳ�����ԣ����������������֮�⣬�����̼ҵ��û������Ͳ�Ʒ�������ܶ࣬���Ծ���ļ�������dz��Ĵ�ij��������û�������Ķ��������ޣ���������ͬʱҲ�Ǹ߶�ϡ��ġ�
�����塢���ڱ�ǩ���Ƽ�����
�������ڱ�ǩ���Ƽ��㷨Ҳ��ʮ�ֳ����ģ����綹��������������Ʒ���۵ȡ���ǩ��Ϣһ���Ϊר�ҡ�ѧ�����ı�ǩ��һ��Ϊ��ͨ�û�����Ʒ��ı�ǩ��UGC, User Generated Content��������ǩ������һ��Ҫô������Ʒ�����ģ��������֡���𡢲��صȣ�Ҳ�����û�����Ʒ�Ĺ۵����ۣ�������ˡ����á�����ǿ�ȣ���Ԫ�飨�û�����Ʒ����ǩ��ͨ����ǩ���û�����Ʒ������ϵ��
�������ڱ�ǩ�Ƽ�������ӱ��磺ͳ��һ���û���õı�ǩ��ͳ��ÿ����Ʒ�����ı�ǩ��Ȼ������ͨ��һ���Ĺ�ϵ�Ƽ���������ȻҲ����չ�ֱ�ǩ�ƣ����û�����Լ�����Ȥ�ı�ǩ��Ȼ�����˸��Ի��Ƽ���
�������ڵľ������Ա������궼����ʹ�ñ�ǩ��Ϣ��

����
�������ڱ�ǩ�������û������ԱȽ�ǿ������һ����ͬ����˼�û�����������ԱȽϴ淶�����Կ��ǣ��û����۵�ʱ���ṩ���ñ�ǩ�����û�������Լ���������죬���Ƽ��ı�ǩ��������Ʒ�����ԽϺõı�ǩ���Լ��û��Լ����õı�ǩ���û�һ���ԣ�����Ϊ����ͨ����Ȼ���Դ��������Ա�ǩ���������������û����������������۽������֣���ǩҲ�г�β�ֲ�ЧӦ�����Գ������ű�ǩ����ô��ȡ��Щ���컯�����ñ�ǩ���и���ȷ���Ƽ�Ҳ��Ӧ���о��Ŀ��⣨�����ֲ�/SVD?����
���������
̽���Ƽ������ڲ������ܣ��� {1,2,3} ����
�Ƽ�ϵͳʵ��
(2011-)2014 �����ܽ����ƪ
Netflix Prize �е�Эͬ�����㷨
������һλ�㷨ʦ����ʦ��Spark����ѧϰ�ʼǣ�����һ�����Ƽ�ϵͳ��
�������Ƽ�ϵͳ�ĵ����Ƽ�������
�����������Ƽ��㷨ʵ����
�������ı��179���Ժ����Ķ���ƪ����ֱ������179���ɡ�
����������m���Ի�ȡ������Ŀ¼
���������Ź����Ƽ�������
�㷨�����ݽṹ
�����Ƽ���15�������������
�������ǣ������������㷨�����ݽṹ���ڿͼ��������簲ȫ�������ݼ�����ǰ�˿�����Java��Python��Web��������������iOS������C/C++��.NET��Linux�����ݿ⡢��ά�ȡ����������ѧϰ���顢�Ƽ������������Դ�����ǰ����ֵ�ù�ע��15���������Ź��ں�����






























����˵�������а�