 )
)��������Ŀ¼
����1. R�Դ�����
����2. reshape2�����ع�
����3. dplyr
����4. tidyr
����5. �ַ�������
����1. R�Դ�����
����1.1 ת��
����ʹ�ú���t()�ɶ�һ����������ݿ����ת�ã��������ݿ���������ɱ������У�����
����
��������array����ά��ת�� aperm
����
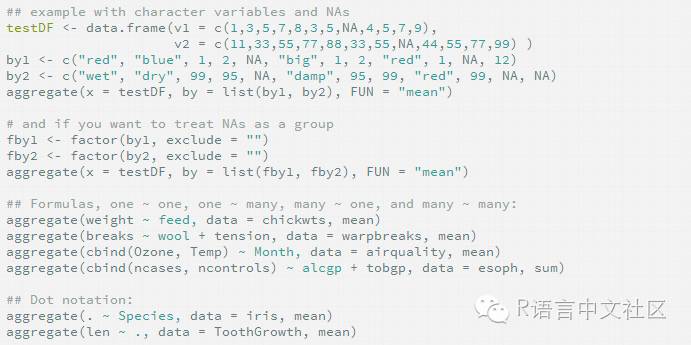
����1.2 ��������aggregate
������R��ʹ��һ������by������һ��Ԥ�ȶ���õĺ������۵���collapse�����ݡ����ø�ʽΪ��
��������x�Ǵ��۵������ݶ���by��һ����������ɵ��б�����Щ��������ȥ�����µĹ۲⣬��FUN�����������������ͳ�����ı������������������������¹۲��е�ֵ��
����
����by�еı���������һ���б��У���ʹֻ��һ����������Ҳ�������б���Ϊ���������Զ�������ƣ�����by��list(Group.cyl=cyl,Group.gears=gear)��
����
����1.3 apply
����������
����1.4 union��intersect
����
����1.5 �ϲ� cbind��rbind
��������ϲ�����ͨ�����������ݿ������ӹ۲⡣
����(1)rbind() ������ϲ��������ݿ����ݼ���
����(2)cbind() ������ϲ��������ݿ����ݼ���
����ע���������ݿ��У��У���������ͬ�����x��ӵ��y��û�еı������ںϲ�����֮ǰ�������´�����
����(1)ɾ��dataframeA�еĶ��������
����(2)��dataframeB�д����ӵı���������ֵ��ΪNA(ȱʧ)��
����
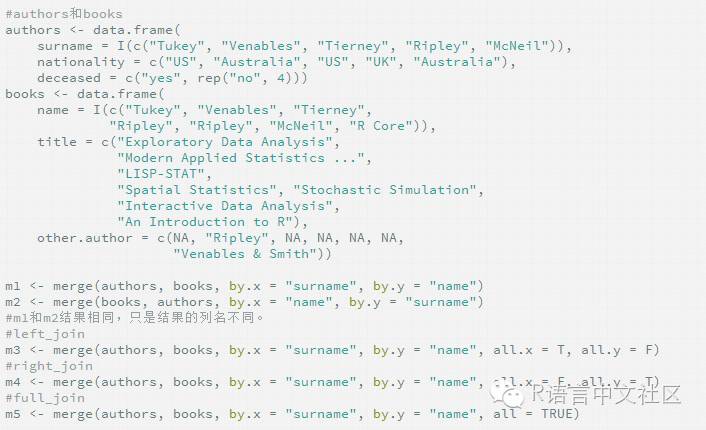
����1.6 ƥ��ϲ� merge
����mergeЧ��ͬdplyr��join��join��Ч�����ߡ�
����(1)inner_join �ȼ��� merge(all=F)
����(2)left_join �ȼ��� merge(all.x=T, all.y=F)
����(3)right_join �ȼ��� merge(all.x=F, all.y=T)
����(4)full_join �ȼ��� merge(all=T)
����
����1.7 �ų��ظ����� unique
����unique ��������ȥ�����������ݿ���������е��������ظ���Ԫ�ء�
����
����2. reshape2��
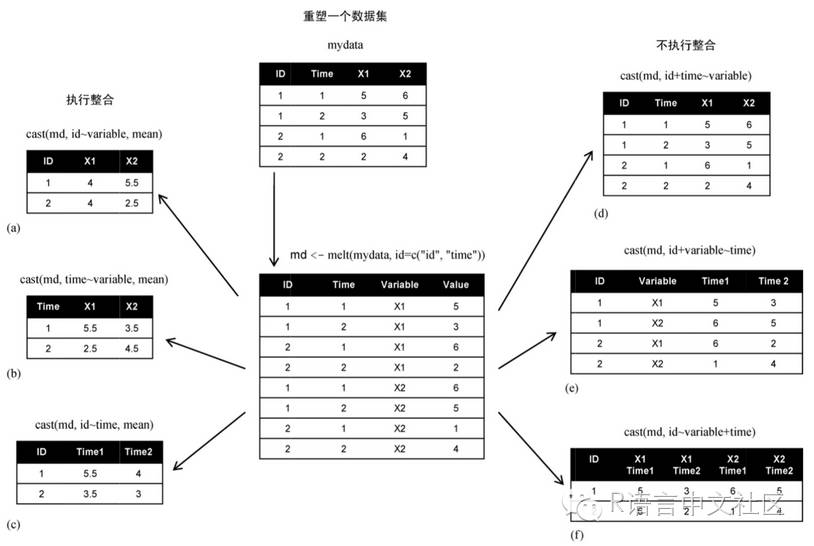
�������Ƚ����ݡ��ںϡ���melt������ʹÿһ�ж���һ��Ψһ�ı�ʶ��-������ϡ�Ȼ�����ݡ���������cast��������ʹ���κκ��������ݽ������ϳ���Ҫ���κ���״��
����ע��reshape������������Ϊcast()��reshape2������������Ϊdcast()��acast()
����
����2.1�ں�-melt
�������ݼ����ں��ǽ����ع�Ϊ����һ�ָ�ʽ��ÿ������������ռһ�У����д���ҪΨһȷ�������������ı�ʶ��������
����
����2.2����-dcast��acast
����Use acastor dcastdepending on whether you want vector/matrix/array output or data frame output. Data frames can have at most two dimensions.
����1.dcast�������صĽ����һ�����ݿ�
����2.acast�������صĽ�������������������������
�������ø�ʽΪ��
����
��������mdΪ���ںϵ����ݣ�formula������Ҫ�Ľ����FUN�ǣ���ѡ�ģ��������Ϻ�����
�������ܵĹ�ʽ���磺
�����������ʽ�У�rowvar1 + rowvar2 + ... ������Ҫ�����ı������ϣ���ȷ�����е����ݣ���colvar1 + colvar2 + ... ������Ҫ�����ġ�ȷ���������ݵı������ϡ�
����
����
����3. dplyr
����3.1 ��������
����3.1.1 ��������
������������������ݼ�ת��Ϊ��ʾ���Ѻõ� tbl_df ����
����
����3.1.2 ɸѡfilter
���������������ж�ɸѡ������Ҫ��������ݼ�, ������ base::subset() ����
����
������R�Դ�����ʵ��:
�������˴�������, ��֧�ֶ�ͬһ�����������������, ��:
����3.1.3 ���� arrange
����
������R�Դ�����ʵ��:
����
����3.1.4 ѡ��select
������������������ѡ�������ݼ�:
����
�����ų�����:
����select�����⺯��
����(1)starts_with(x, ignore.case = TRUE): names starts with x
����(2)ends_with(x, ignore.case = TRUE): names ends in x
����(3)contains(x, ignore.case = TRUE): selects all variables whose name contains
����(4)matches(x, ignore.case = TRUE): selects all variables whose name matches the regular expression x
����(5)num_range("x", 1:5, width = 2): selects all variables (numerically) from x01 to x05.
����(6)one_of("x", "y", "z"): selects variables provided in a character vector.
����(7)everything(): selects all variables.
����
����":" ѡ�������У�contains��ƥ������
����ͬ��������R�Դ���subset() ����.
����
����3.1.5 �����±���mutate
�����������н����������㲢����Ϊ����:
����
����mutate_each()
������ÿһ�����д��庯����
����plyr::mutate() �� base::transform() ����, �������ڿ�����ͬһ������Ը����ӵ��н��в�����
����
����ͨ��data.frame�п���ʵ��
����3.1.6 ����summarise
����
����count()
����
����3.1.7 tally
����
����3.2 ����group_by
�����������ݼ�ͨ�� group_by() �����˷�����Ϣ��,mutate(), arrange() �� summarise() �������Զ�����Щ tbl ������ִ�з������ (R���Է��ͺ���������).
����
������: һЩ����ʱ��С����
����n(): ������� n_distinct(x): ���� x ��Ψһֵ�ĸ���
����3.3 ��ʽ����(�ܵ�) %>% �� %.%
����dplyr������������һ��������������then��ʹ��ʱ����������Ϊ��ͷ, Ȼ�����ζԴ����ݽ��жಽ����������:
����
���������ݴ�����˼·д����, һ��������, ����д����, �ӽ��ڴ����ҵ���Ȼ����˳�� �Ա�һ����R�Դ�����ʵ�ֵ�.
����
���������ﻹ��ʾ: ͨ�� %>% �Ƕδ������������δ��룬�����ٶ������ܶ.
��������������ʵĸ������ ggplot2 ��� + ���Ӻ�һ��, ���ӳ���������Ĺ�����? ������ʵ��ʹ���ж�������ܰ�.
����3.5 ����ƥ��ϲ�join
����(1)inner_join(x, y) ��ֻ����ͬʱ������x,y���е���
����(2)left_join(x, y) ����������x���Լ�y��ƥ�����
����(3)semi_join(x, y) ������x�У���y����ƥ����У����Ϊx���Ӽ�
����(4)anti_join(x, y) ������x�У���ƥ��y���У����Ϊx���Ӽ�����semi_join�෴
����(5)full_join(x, y) ����������x��y���
����(6)right_join(x, y) ����������y���Լ�x��ƥ�����
����
����3.6 �������ݿ�
����(1)dplyr �����������ݿ�
����(1)ʹ���뱾�����ݿ����һ�����
����(3)ֻ֧������SELECT���
����(4)֧��SQLite, PostgreSQL/Redshift, MySQL/MariaDB, BigQuery, MonetDB
����3.7 ���ô��庯���任����
����
����4. tidyr
����tidyr��������Ҳ��Hadley Wickham, ��dplyr�����ʹ�ã���reshape2��������������ڿ�...��
����5. �ַ�������
����5.1 �ַ����� nchar
����nchar()�ܹ���ȡ�ַ����ij��ȣ�����length()�Ľ����������ġ�
����
����5.2 �����ַ� paste
����paste()�����������Ӷ���ַ����������Խ������Զ�ת��Ϊ�ַ��������������������ܴ������������Թ��ܸ�ǿ��
����
����pasteĬ�ϵķָ����ǿո���ָ��sep=""������һ��collapse������������Щ�ַ���ƴ��һ�����ַ����������Ƿ���һ�������С�
����5.3 �ָ��ַ� strsplit
����
����5.4 ��ȡ�ַ� substr��substring
����
����5.5 �滻�ַ� sub��gsub
����(1)sub ֻ��һ���滻�������м���ƥ�䣩
����(2)gsub ������������ƥ�䶼���滻
����
������Ȼsub��gsub�������ַ����滻�ĺ��������ϸ��˵R����û���ַ����滻�ĺ�������ΪR���Բ���ʲô�����Բ������Ǵ�ֵ����ַ������ԭ�ַ�����û�иı䣬Ҫ�ı�ԭ��������ֻ��ͨ���ٸ�ֵ�ķ�ʽ��
����
����sub��gsub��������ʹ����ȡ����ʽ��ת���ַ�+���֣��ò��ֱ��ȫ��
����
����5.6 �ַ���ѯƥ�� grep
����(1)grep ����ƥ������±�
����(2)grepl �������в�ѯ�����������
����(3)regexpr
����(4)gregexpr
����(5)regexecregexpr��gregexpr��regexec�������������صĽ��������ƥ��ľ���λ�ú��ַ���������Ϣ�����������ַ�������ȡ������
����
����5.7 ����
����(1)��Сдת�� tolower��toupper
����(2)�б�ת��Ϊ����unlist
����(3)unlist(x, recursive = TRUE, use.names = TRUE)
����(4)�ظ�����rep()
����































����˵�������а�