 )
)������������Barzan Mozafari����ԭ��վ��Ȩ����InfoQ����վ�����༭Ѧ�������벢������������Ķ�ԭ�ġ��鿴Ӣ�����ӡ�
��������ÿ���˶����������������ķ�ʽ��Թ���ݿ���������⣬���ݿ����Ա�ͳ���Աʱ��Ҫ���ٷ�������Դ�����û����ݿ��ѯһֱִ�в�����������Щ�����������˵̫���������ˡ�
��������취���ֶ���������͵�һ�־��ǰ�ǹ��ָ���ѯ��䣬��Ǵ�����Աû��д����Ч�IJ�ѯ�����DZ�����ʹ��ǡ�����������ﻯ��ͼ������д�����õIJ�ѯ������Ҫ���Ӹ���Ľڵ���������Щѹ������ijЩ����£���ķ�������ִ��̫���Ч�IJ�ѯ�����أ���ῼ��Ϊ��ͬ�IJ�ѯ���ò�ͬ�����ȼ���������Щ�����IJ�ѯ������CEOҪ��IJ�ѯ�����Եõ����ȴ����������ʹ�õ����ݿⲻ֧�����ȼ����У���ô���ݿ����Ա�п��ܻ�ȡ����һЩ��ѯ���Ա��ڳ���Դ���������IJ�ѯ��
����������������������һ��������㶼������࣬Ҫ�ȴ���Ч�IJ�ѯִ����ϣ����߹��������Ʒ���ʵ����������ķ�������������˶Դ�ͳ�����ݿ���źͲ�ѯ�Ż�����������Ϥ����Щ����������ȱ�㣬�������Dz������������������ǡ�����ƪ��������ǽ�������������ֵļ��������Dz�Ϊ������֪�����ڶ�����������ǻ�Ϊ���Ǵ������õ����ܣ��������ǰ���ס���ᡣ
�������ǽ�����̽�����ֳ�����
��������һ��̽���Է���������Ϊһ������ʦ����ͨ�������������ھ����еļ�ֵ�����߶�ҵ�ͻ�����������֤���ԡ�����Щ����£���һ�㲻֪���ù�ע��Щ��������⡣��������һ����ѯ���鿴�����Ȼ�����Ҫ��Ҫ����������һ����ѯ�����仰˵����������һϵ�е�̽���Բ�ѯ֮�У�ֱ���ҵ�����Ҫ�Ľ����
������Щ��ѯ��ֻ��һС���������õģ����ǿ��ܱ��������ɹ�˾�������������Ϊ�ͻ�����ͼ��������ÿ�����ύ��ѯ֮���������Ҫ���ϼ����Ӳ����õ�������ȴ�ʱ��ij���ȡ�����������Ĵ�С�Լ��������еIJ�ѯ�������ڵȴ�����ڼ䣬����������һ�����������IJ�ѯ����Ϊ��һ���IJ�ѯ������һ����ѯ�Ľ����
��������������ڵȴ�����ڼ䣬��������������������������Ľ��������ġ�����������ָ����ʲô����Ƚ����������ͼ����
����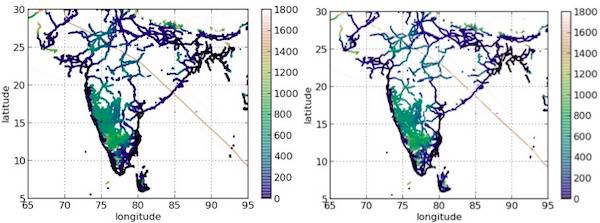
����������ͼ���ֱ���ͬһ��BI�������δӺ�����ݿ���ز�ѯ���ݵĽ�����ұߵIJ�ѯ����71������1B��������ó����������ߵIJ�ѯֻ����3���Ӵ�1M��������ó������ȷʵ�����ұߵĽ����ȣ���ߵĽ�����Ǻܾ�ȷ�������������Ƿ�ֵ���أ������Ϊ�˵õ������Ľ������71���ӣ������������ȣ���ô���������õ�һ��������ͬ�Ľ����������ߵ��Ǹ�ͼ�����������������Ϊ71���ӵĵȴ���ֵ�õģ�
������Ȼ���Ⲣ��ʲô�µ��ӣ�ʵ���ϣ����е����������ʹ������ģʽ������ʹ�����������һ�Ÿ߷ֱ���ͼƬʱ�����Կ�����������Ǽ���һ�Ŵֲڵ�ͼƬ��Ȼ��ͼƬ�������������������뵽�����ݿ��SQL��ѯ��ʹ������ģʽ���˲����ࡣ
����Ҳ������������ʣ���ʵ��Ӧ�õ������ʵ�����������أ�������ݲ�����̬�ֲ��Ŀ����𣿻��ܿ�����Щ����ֵ�����Ƿ���Ҫһ���ض������ݿ⣿��ϣ��������ƪ���½���֮ǰ�ش��������⣬���������ҽ����������ij���������Щ��������ῴ��һЩ������˼���뷨���Կ�200�����ٶȿ���99.9%ȷ�ȵĽ����
���������������صļ�Ⱥ�����ֽ��������ݿ��û�����ӵ���Լ���ר�����ݿ⼯Ⱥ��Ҳ����˵����ͨ��Ҫ���Ŷӹ�����Ⱥ�������������ı����BI���ߣ���������ͬ�����ݿ���Դ��ִ��SQL��ѯ������Щ��Ⱥ�������أ���ôֻ�����ֽ����
����A. ȫ��̱������ʲô���鶼�����ˣ�������Ҳһ����Ҳ����˵��һ�����ݿ�������б����𣬲���û�и����CPU��Դ���ã���ô��û���������������������ٶȵõ���ѯ�����
����B. ����̱����������ս�����һЩ�����ȼ��IJ�ѯ���ý����IJ�ѯ�����������˾Ҫ��ִ�еIJ�ѯ����ִ�С�Ҳ����˵������һС������Ҫ���˿��ģ������������˲����ˣ�
����C. ������������������������ܻṺ������ǿ��ķ����������߰�ϵͳǨ�Ƶ��ƶˣ�����ʵ�����ʹ�ø���Ľڵ㡣��Ȼ������ҪͶ������Ǯ�����һ�������㣬��������һ�����ڵķ�����
�����ܶ��˲�֪�����е��������������ǰ�����ָ��ã����Ҳ����������ô��Ǯ����ô����ʲô��
����Ϊ�����ȼ��IJ�ѯ����99.9%ȷ�ȵĽ������Ϊ�����ȼ��IJ�ѯ����100%ȷ�ȵĽ��������ͳ�Ʒ���ͨ��ʹ��0.1%�����ݾͿ��Եõ�99.9%ȷ�ȵĽ���������Ϊʲô����0.1%��ȷ��ȴ�ܻ���100��200�����ٶȡ���֪��û����Ը�����ֻ��99.9%ȷ�ȵĽ�������������������������ģ�Ҫô�жϲ�ѯ���źܳ��ĶӵȺ�Ҫô�յȲ�ѯ������
�����ڳ���һ���Ѿ��ᵽ�������������²���Ҫ�ܳ�ʱ�䶼�ܹ��õ�100%ȷ�ȵĽ������������Щ��Ҫ�ȴ��ܾõIJ�ѯ�����Գ���ʹ��99.9%ȷ�ԵĽ���������½��������һ�������ǡ���Ρ�������Щ������ֻҪ��ס��99.9%��ȷ�Բ��������ʧȥ0.1%�Ľ��������Ȼ���Կ������еĶ�����ֻ������0.1%�����ڴ����ʱ����������������𣬳�����dz����⡣�Ƚ���������ͼ����
����
����
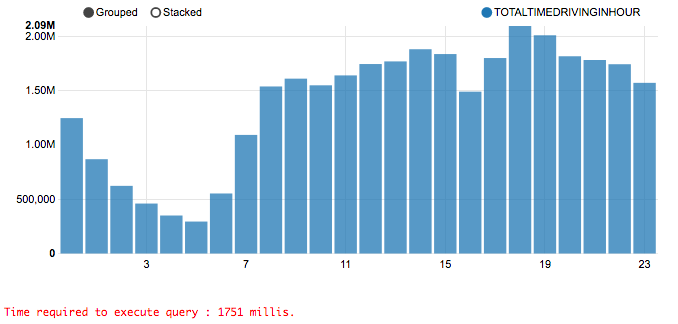
������Щ��ѯ�������������NYC������ݼ���������չʾ���ǵ���������Ҫ��ʱ�䡣
�������ֱܷ���ĸ���100%ȷ�Ľ�����ĸ���99.9%�Ľ���𣿶Դ��������˵��������û������ġ��������Ǹ���ѯֻ����1.7�룬�������Ǹ�����42.7����Ҳ����˵����Ȼ������0.1%��ȷ�ԣ�ȴ��ʡ��25����CPUʱ�䣡������������һ�ֳ�����Ȼ���һ�������ǡ���Ρ�������Щ��
����������������ѧϰ�����ݿ�ѧ�����������һ������ѧϰר�һ����ݿ�ѧ�ң���ᷢ���Լ�������һЩ����ѵ��ͳ��ģ�͡��������š�����ѡ�ͻ̷�������顣�����˸е�����������Ҫ������Դ����IJ��������ԣ����һ���ѧϰģ�͵�ѵ����ռ�úܳ���ʱ�䡣��Ⱥ����æ�����кͲ���ģ��ѵ�������ݿ�ѧ���������波�Ը����ģ�ͺͲ���������������������̡�
�������ڴ����Ӧ����˵������ȫ���Ի��ڷ������Ľ�����������ľ��ߡ����磬A/B���ԡ������Դ����������ѡ�͡����ӻ����������ݻ����ȱʧ���ݵ����ݼ���������������ڲ����Ź�������ô��Ӧ�ò��ῼ����ô���ģ�
����������дһƪ����ר�Ž������ͨ���������ź�����ѡ�������١�
������ô�����ǡ���Ρ�����ֻ����һ��ȷ�ԾͿ��Ի���200����ѯ�ٶȵ�������
��������ʹ�ý��Ʋ�ѯ����������AQP����ʵ��AQP�кܶ��ַ�ʽ�����������ʹ�����ȡ�����ݡ���ʵ�����������������Ƿ���̬�ģ���ôʹ�����ȡ�����ݻᵼ�´�����ֵ��ʧ����ֻ��������������������ԭʼ������Ը����õ���һ�ֽ������ֲ�ȡ�����ļ�����ΪʲôҪ�ֲ�ȡ�����������������
����
�������������������������������IJ�ѯ��
SELECT avg(salary)FROM table WHERE city =��AnnArbor��
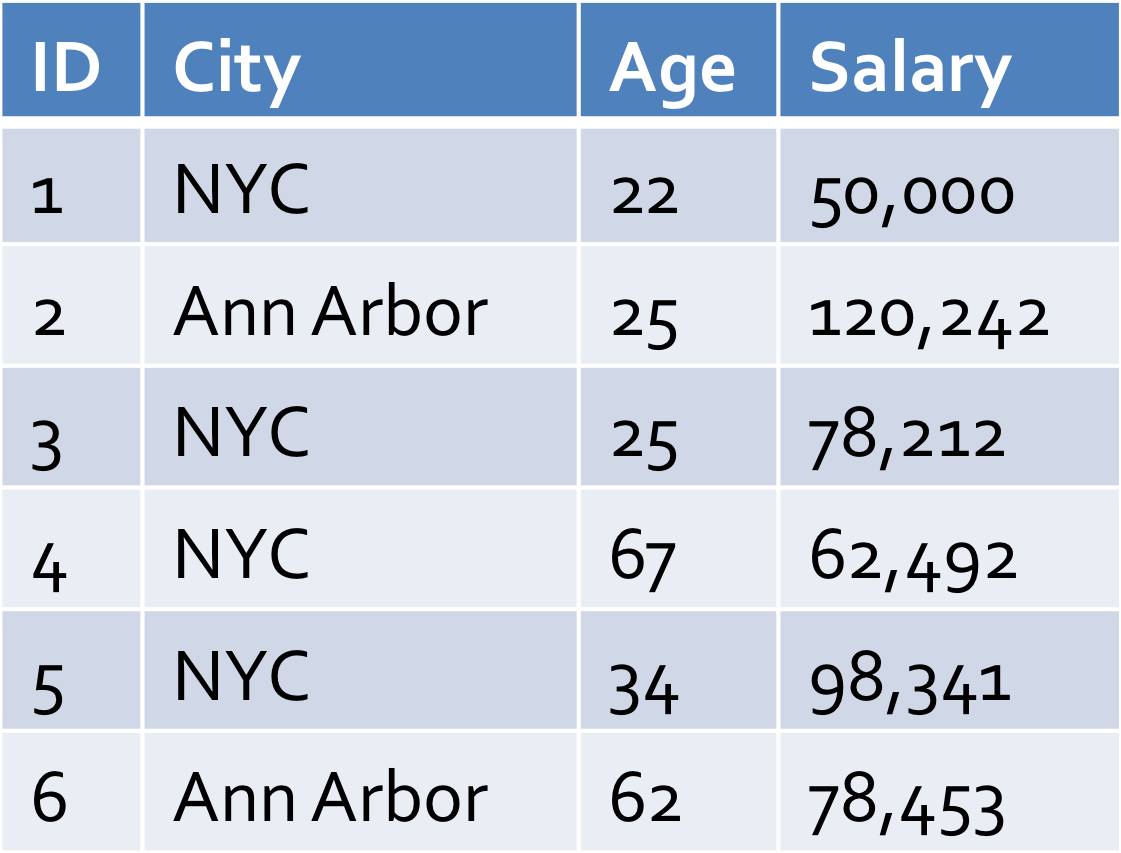
�������������ѯ��û������ģ���������������һ�������ݻ�����Щ���ݷֲ��ڶ�������ϣ���ô�����ѯ������Ҫ���м����Ӳ��ܵõ������������������ȡ�����������������ѯ�����磺
����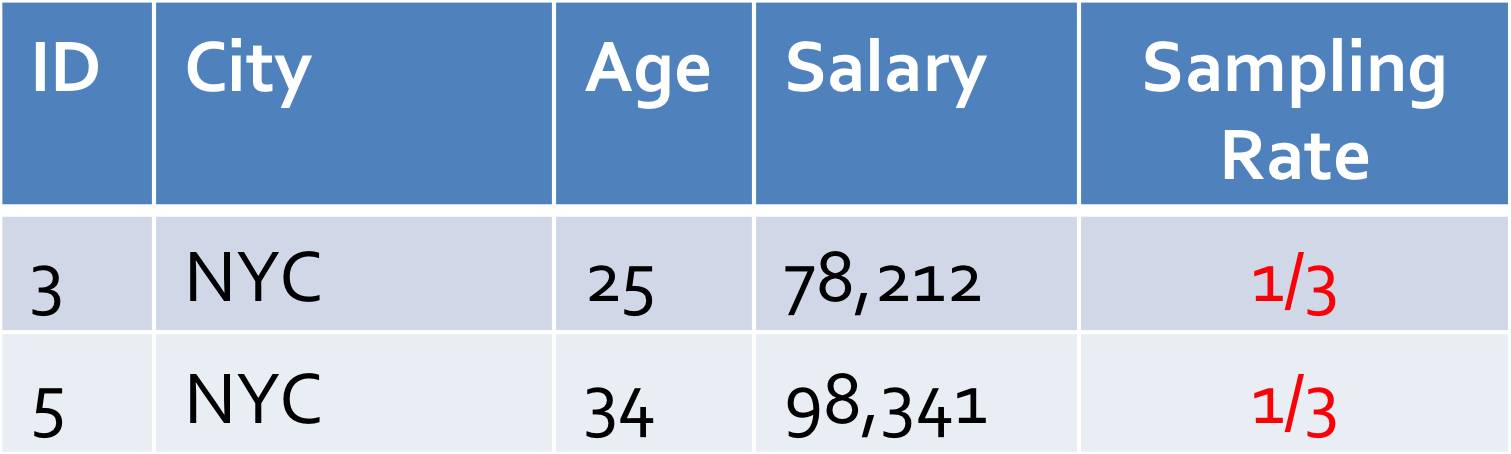
������ΪAnn ArborԪ�����ԭʼ����������NYCԪ����ٺܶ࣬�������ȡ�����������ֻ�ܿ��������ļ��������߸��������������ֲ�ȡ�����ȶ����ݱ�����City���зֲ㣨���磬��������Ȼ�����ÿ��City�����ݽ���ȡ����
| ID | City | Age | Salary | Sampling Rate |
|---|---|---|---|---|
| 3 | NYC | 67 | 62,492 | 1/4 |
| 5 | Ann Arbor | 25 | 120,242 | 1/2 |
��������Ҫ̫���ͳ�����ݣ����ǿ��Կ��������ķֲ�ȡ�����Ա�֤�õ��dz���ȷ�Ľ����������ֻʹ����ԭʼ���ݵ�һС���֡�
�����������������������ô�����ݽ��зֲ�ȡ���Լ���κ��������ȷ�ԡ�����һ������д��һ���½ڽ����ⷽ������ݡ��������ǿ��Խ���һЩ�����Զ������Щ��������һЩ�ֳɵIJ�Ʒ����ʹ�ã���ֻ��Ҫ���°�ť�����ǻ��Զ��������ʣ�µĹ��������ܿ�ط��ؽ������ʱ������Щ���������ȫ���Ծ��������ȷ�Ժ��ٶ�֮������Ȩ�⡣
����BlinkDB/G-OLA
���������кܶ��AQP������ѡ����BlinkDB��Ȼ�������ǵ�һ����Դ�ķֲ�ʽ���߲��У�AQP���档�Ҳ����������Ŀ�������ҿ��ܻ�ƫ̻�����Һ�ϲ��BlinkDB�Ľ������������Ϊ�����������ֵ�ѧԺ�ɻ���ҵ�Ľ��������������С�Databricks��˾������BlinkDB�����Ŀ��������������˾��Apache Spark��ҵ���ˣ�������ǰ��Databricks������BlinkDB��һ����������������������û��Խ����������ĵ�����ֱ������Ϊֹ������������G-OLA����������û�б���������������BlinkDBҲ�ܾ�û�и����ˡ�
����SnappyData
����SnappyData��һ����Դ���ڴ��Ϸ���ƽ̨����������ͬʱ֧��OLTP��OLAP������������ݿ�����ֱ�Ӷ�Apache Spark��������չ��������Spark��ȫ���ݣ������ṩ�˿ɿصķֲ�ȡ�������Խṹ��֧��AQP�����IJ�ѯ���BlinkDB���ƣ������û�ָ��ȷ�ȣ�Ҳ����˵ȷ���ǿ��Ե����ġ����磬�������Ҫ�����Ľ������ô�����ָ��100%��ȷ�ȣ�Ĭ�Ͼ��������ģ����������������õ����������ʹ��99%��ȷ�ȣ�����������һ�����ھͿ��Եõ���������ҿ�����SnappyData��һ����������ʹ���˿ɿصķֲ�ȡ����Ҳ����˵��������ڼ�����������һ����ѯ�������ѯ���Ǽ�T�����ݣ����߲�ѯ�������ڱʼDZ��ϻ���ͬʱ�����ż�����ѯ�ļ�Ⱥ�ϡ�SnappyData�������˶�����֧�֣������ʵʱ�ض�����������ȡ����
����SnappyData��һ���ŵ������ṩ�˺ܶ��ϲ���û����棬�㲻��Ҫ�߱���רҵ��ͳ��֪ʶҲ��ʹ��AQP���ԡ����磬���������ṩ��һ���Ʒ�����iSight�������ں�̨���в�ѯ��ͬʱʹ��Apache Zeppelin��Ϊǰ�������ӻ���ѯ�����
�������ϣ�����SnappyData���Ƴ��ߡ�
����Presto
����Facebook��Presto��һЩʵ���Ե����Կ�����������Ľ��ƾۺϲ�ѯ���Ҳ�֪����Щ�����Ƿ������µģ��������IJ���֮����������Ҫʹ�ò�һ���IJ�ѯ�����Ҫ��SQL������ʹ����Щ���ԡ������е�BI���ߺ�Ӧ�ó�����˵���������е��鷳����Ϊ������������DZ�ڵ����ټ�ֵ����������ʹ���µ����ԭ�еIJ�ѯ������д��
����InfoBright
����InfoBright�ṩ�˽��Ʋ�ѯ���ԣ�IAQ����������ϵͳ��һ�����ǣ�IAQ��ȫ��ʹ����������ϧ���ǣ�����IAQ�Ĺ���ԭ��������Ҳ֪֮���٣�Ҳ��֪����������ṩȷ�Ա�֤�ġ�����ͨ���Ķ����ǵIJ��ͣ�����Ϊ������Եײ����ݽ����˽�ģ��Ȼ��ʹ����Щ�������������IAQ���ǿ�Դ�ģ������ǵ���վҲ�Ҳ��������ϸ����Ϣ���������ǵĽ������������ͦ����˼��
����ABS
����Analytical Bootstrap System��ABS������һ����Ʋ�ѯ���棬��ʹ��������Ч��ͳ�Ƽ����������������Ĵ����е���ˣ�����ֻ֧�����ڰ汾��Apache Hive�������ĿĿǰ���ڲ���Ծ״̬��
����Verdict
����Verdict��һ���м�������Ŀͻ��˶���Ӧ�ó����BI���ߣ������SQL���ݿ⡣�����������һ�����������ݿ������в�ѯ���������õ����ƽ����ԭ���ϣ��������κ�SQL���ݿ���ʹ��Verdict��Ҳ����˵��������������ʹ���ض��Ĺ�ϵ�����ݿ⡣����Ŀǰ��ֻ�ṩ��Spark SQL��Hive��Impala�������������ŵ����ڣ�������ͨ�����κ�SQL���ݿ⣬�������ǿ�Դ�ġ����IJ���֮�����ڣ���Ϊ����һ���м�������������ܲ���InfroBright��SnappyData��ô��Ч��
�������ϣ�����Verdict������ߡ�
����Oracle 12C
����Oracle 12C֧�ֽ���count distinct�ͽ��ưٷ��ʡ���Щ���ƾۺϲ����Ľ������ܶ���ʹ�ø��ٵ��ڴ档Oracle 12C��֧���ﻯ��ͼ�������û��Ϳ��ԶԽ��ƾۺϽ���Ԥ��������������Ȼ����count distinct�ͽ��ưٷ��ʺ����ã�Ҳ�ܳ��ã�����Oracle 12C��û���ṩ���������Ͳ�ѯ��֧�֣�������Щ�����Ѿ����û������ܴ�ĺô��ˡ�����������֪���кܶ����ݿ⳧��һֱ������֧��count distinct�����磬ʹ��HyperLogLog�㷨����������һƪ���ģ�������Oracle 12C����Щ�����Ը���Ȥ�����Զ�һ����
����ÿһ���������Ǿñ��طꡣʱ��һ�꣬QCon����վ����������20+�ȵ�ר���¯��������������VR��TensorFlow�����ѧϰ�ȳ������������з���ȫ���ƶ�ר�������ά��ҵ��ܹ���һ��ʵ���������⼼��ר�ҹ���ʢ�٣����̱���������7���ػݡ�
��������̸
ID��BigdataTina2016
������������ά��ʶ���ע
רע�����ݺͻ���ѧϰ��
����ǰ�ؼ������������˼����
��ӭͶ�壬��ӭ����������































����˵�������а�