 )
)����
�������ߣ�������
�����༭��С��
������������һ������Fintech��������Ȼ���𡣻������Ƽ��봫ͳ������ҵ�Ľ��Խ��Խ���룬��ΪͶ�н���ϵͳ����������г�����ƽ̨�����������ļ�����������ܹ�������������ģ�
Ͷ�е�Global Markets��Sales&Trading������Ҫ�����ڴ��ͻ����ͻ����������ڻ�������ҵ�������Լ�����Ͷ�ʻ���˽ļ���𣬶Գ����ȣ������°��������̣�Market Maker��, ��㣨FX��, �̶������ཻ�ף�Currencies, Interest Rates and Credit��, ��Ʊ���ף�Equity Securities��������Ʒ���ף�Derivatives�����ṹ����Ʒ��Structured Products��������������ͻ���Ͷ����Ӫ���ȸ��ֽ�������
������������
�������ڱ���
08�����Σ������Dodd-Frank������ǰ��Ͷ���ڲ��������õ����������͵ͳɱ����ƣ������Ÿ��ָ߸ܸ���Ӫҵ��ʵ�壨���ƶԳ���𣩴����������ף��Գ壬�����������ԶĵȽ��ף��������ĸ�ʢGlobal Alpha����Ħ��PDT��Proess Driven Trading�������ָ߶�����ײ����ɾ���Ͷ�б�����Ҳ�ɾ��˺ܶ��Trading Floorֱ���Ĵ��У��绨�����Ħ��ǰ��CEO��
08��֮�������������Ĺ涨Ͷ��ֹͣ��Ӫ���ף������������ű��ܴ����Ҫô���ѵ�ά�ּ�С��Ӫ��ģ��Ҫô�����伣�����ͬʱ��Ҳ��������չ����ʢ��Ͷ�е�ר�������̣�Designated Market Maker���Զ������ף�������ָ������Ȩ����㣬��ծ�ȣ�����B2B��Broker-to-Broker���г���B2C��Broker-to-Client���г���
������������
����Ҫ���ܵ�ϵͳƽ̨�����Խ�˴�֧����Ӫҵ����֧���������Զ������ס�
�����ִ���֮���Գ�֮Ϊ���У����������ҵ��ʵ��֮�⣬�似������Ҳ����С�꣬ʵ�������ڹ�Ȼ�������˾��Ŧ��������˹����г�70%�Ľ����������ڻ����Զ������ף����еĸ�Ƶ����ϵͳ���Ǵ��бر�֮�����߶������������ǵ�ij��ij��ij��ij��ijTrader�ĵ�ָ��(Fat Finger)��ʹ�õ���˹ָ���ַ�������1000��㣨��10%���ң�����ɲ�����ͷ���㹻���������ǻ���ϵͳ�㷨��������Ӧ���µ�ѩ��Ч�����������ŵĽ������������ֶ�������ITϵͳ֮�ϣ����IT����ϵͳ����bug������磬ȫ���г���Ҫ��һ�¡�
�������У�ITϵͳ�����Դ�Ħ��ǰ�����ֵܵĻ�����ʩ���ƣ���ʢ���Գ�һ�ɣ��ӿ������Ե����ݿⶼ���Դ����ܹ��������һ��ʼ�ʹ�ͳһ�����н������ݶ�����������ݿ��У����к����ķ�أ����㣬�Գ壬����ܣ������ȶ����֮�ǡ�����������������ʮ����������ϵͳ�����ֽ������ݴ�����ȥ�������쳣�����ɾʹ�����Щ������Ƶ�����ȫ����У�ľ�Ӣ�˲ţ��������Ը���ѧ���������������P.h.D����������ֱ��ƾ��ҵ���ʦ�����Ħ��Java֮���������´Ӷ�������������á�
����ƽ̨ҵ��
������ij���е�Global Market Data���г�����ƽ̨����̽�����ڲ�����ϵͳ�Ļ�ʯ���г�����ƽ̨��֮���Գ�֮Ϊ�������룬����Ϊ���еĽ����ٲ����г����ݣ����۵�֧�֣�����㣨FX����Rates, Credit, ��Ȼ��ϵͳ��Ҫ֧�̶ֹ������Լ���㽻�ף���Ʊ�г������ڸ�����һ���ж���ϵͳ֧�֣����̶����潻�����ռ��ȫ��������2/3���佻����֮��ɼ�һ�ߡ�ÿ��ȫ��������г����ݳ���ǧ����ʵʱTicker�����ۣ����ݵȡ�
����
��������¥�㣨Trading Floor��
��ΪͶ����Ҫ�ĵײ����֧��֮һ����������Ҫ���ü��ɹ����ذ������£�
����ҵ������
֧�ָ߲����������£����ٷ��ʣ���ѯ�г����ݣ��������ݿ��Գ־û�����
֧��ȫ�����������ģ��ٽ����ʣ���������֮������һ����
֧�ֶ����������֮��߿���HA 7*24, �Զ�Failover
֧�ֵ��ӳ�ʵʱ�г����ݱ��۷���
֧����ʷ���ݷ��ʲ�ѯ
֧�ֿͻ��˶���Э����ʣ���RPC, REST, Web, .Net, Excel��
֧��ʵʱϵͳ״����أ��Զ���ά������ƽ̨
������������
��Ҫ������Դ��������·�磨Thomson Reuters��������(Bloomberg)�������ڻ���������CBOT��֥�Ӹ��ڻ����������ȡ�
ÿ�������г����ݴ��20g��
ÿ������Snapshot��EOD���20-40g��
ϵͳ��Ҫ�ڻ�����ά��1-2���µ�EOD Sanpshot�����100-150g���ң�
ÿ��ȫ���г�������������Ϊ20-100g����Ȼ�������Ticker, ���и�Ƶ��Ϊ100000�Σ��ָ��£����߸߷�ﵽ1500-10000�Σ�����£�Ticker���ݶ�Ϊ�������Խ����ṩ��������־û�������������������Ҫ֧�Ŵ��200g���ң����ǵ����ݰ�ȫ�Լ����࣬����Ҫ500g���ҡ�
������ÿ�������������Ȼ��������Ǽܹ�ʦ������������֣�����Ҳ���Ǵ�ϵͳԭʼ�ܹ�ʦ����ƽ̨Ҳ���Ѿ���������Ȼ�ݽ������ǽ��쳢���Ҷ���ţ�����������һ�����ƽ���ʵ���ࡣ�����漰������Ϣ��һЩ���ƣ��ܹ��Ƚ����������������������˼�롣
�����ܹ����
������Ʒѡ��
��������֮������ʵ���Ǵ�������뵽����Ӧ���Ƿֲ�ʽ �� ���� �� ���ݿ⣯�ļ������ݲֿ⣯�����ݷ����ȡ�
Ŀǰҵ��Ƚϳ��죬���еĴ��ͷֲ�ʽ������Oracle Coherence, GemFire, Redis, Memcached�Լ�Apache Ignite�ȣ������ñ������жԱȷ�������Ҫ���ԡ�
����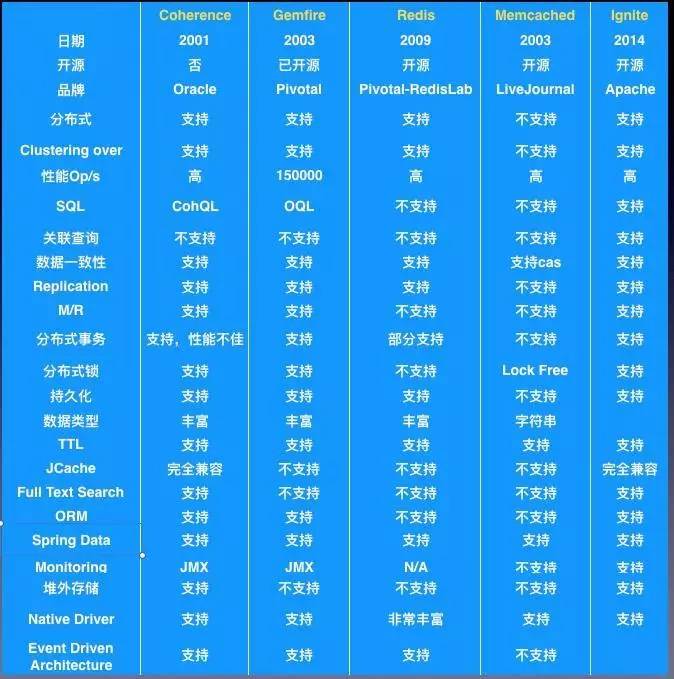
�����ֲ�ʽ����Ƚ�
��ʵ����������ҵ��������������������ų�Ignite, Ϊɶ��2014��ŵ�����������������ʱ�䲻̸��Ignite�����ڴ�����ʱ����������Hadoop, Spark�������õļ��ɣ�ȽȽ���ǡ�
����Redis��ѡ���ʿ��������������Ҫ��������������㣬��ϧ��3.0ǰ���ܺ�֧�ַ���˼�Ⱥ�Լ�ȫ��վ�㲿��Memcached֮������������ڻ��������棻
ʣ�µ�Coherence��Gemfire��������֮��ɣ����ѡ����ʵ��Gemfire������Щ���ٽ��������֣�ȫ��רעͶ��������ȫ��վ�㲿��ȣ�ͬʱ����ʱ������Ӳ��м��㵽MapReduce�������ܣ�2008����Σ�����Ǽ����½���¢�ϴ��л���ƽ̨����ͳ��ȫ��2/3���ϵ�Gemfire���������ڻ����֡�
Gemfireˮ�����ɣ������ڴ�˾��ʱ��ܶ��Ʒ�������Ѷ��ã����ڲ�Ʒ�ij����ԣ��������Լ���ά���ԣ����õIJ�Ʒ�dzɹ���ʯ�����ں�����֤���ڡ�ȫ��������߽���ϵͳ12306����Խ����Ҳ�ٴα�֤����Ȼ��һ���ò�ƷҲ�������ܿ�����Ӧ���г�����
����֧�����ݸ߲������ٷ��ʼ��־û�
�߲��������ٷ����Dz��û������ҪĿ��֮һ����Ҫ������Щ���������Ӧ�õ������˽⣬�����ǵ����ݽ������ƹ���������ν֪��֪�˲��ܰ�ս������
�������ݹ���
���ݹ�������Ҫ����������˽�Ӧ����Ҫ�����������ݣ� ��100g���������ͼ���С�����ı���500k�ļ���С������֮�������������ݵ��������ڣ����Ƿ���Ҫ�־û��ȡ���һ���棬����Ҳ��Ҫ�˽���Щ���ݻ���α�ʹ�ã�����ٲ����ͻ����û��������ݵ�ģʽ���������ѯ�����¼����ĵȡ�
��������һ��ͼ��������һ�£�
����
�����������ݷ���
��������
���������г����ݻ������Ҫ�����ķ��������Ҫ200g���ң����ǵ����ݰ�ȫ�Լ����࣬����Ҫ500g���ҡ�
���ڴ��������ݿ�־û�������������Ӧ�ò��Ǵ����⣬���ݿ���ÿ����������ʵʱ���ݿ���Ҫ500g��1T���ϣ���ʷ���ݿ���5T - 10T���ң�ʵʱ���ݿ���Ҫ��ʱ���ڹ鵵��
�������滮
����64λ��ƽ̨(Linux)�����ǵ�Ŀǰ����ϵͳʵ����֧�ֵ��ڴ�Ϊ���192G����(��������Ϊ16.8TB)���Լ�JVM GC��1.6/1.7�������Ƽ������ڴ��С�������趨һ��Data/Snapshot�ڵ��ڴ�Ϊ10-16g����һ��������һ����Ҫ30-50��nodes��3̨������������Ϊ���ݷ�������
ֵ��ע����ǣ�����������������Ϊ����ר�÷�����������������Ӧ�÷��룬������չͬʱҲ���ӱ����Ӱ�죬����ֲ�ʽ�и�������Ҫ�ͨ�š�
��������
��������棬������������ϸ��ݴ�Ҫ�������3�����ݣ���������3�Ǹ���������֣������������ݵij�ֱ��ݿɿ����ּ������Դ�������ݳ�����ʱ��һ��copy���������ָ����ݣ���һ�����Լ���ʵʱ�����������г�������Ҫ�Ա����Լ�EODΪ�������Dz���1���������༴�ɣ�ʡǮ������Ȼ������ˣ�����Ҳ�����˷dz����ѵ����ܼ��ȶ������⣬������������ʡ�
���ݷ���
�������ݵļ�Ⱥ���洢���ǡ�Ȼ����Ҫ����֧�ָ߲��������ӳٷ��ʣ����ݲ��ֵ��ڹ������١��ֲ�ʽ�����нϳ��õ����ݷ�����Partioned��Replicated��Replicated������������������Խ�С����Ƶ�������ݣ������ݻ��Զ��������м�Ⱥmember��Partioned��������ͨ������������д���Ҫ��ߣ��ڲ��ֳ�����ConcurrentHashMap��Bucket����Redis�е�Hash Slot���洢��
���մ�˼·�����ǽ�һЩ���õ�������Ϣ��ΪReplicated���洢���������г���������Partioned�ֲ��������ڵ��š�
�������ݳ־û�
���̳־û�
���ݳ־û���������Ҫ֧�ֻ����Overflow to Disk�Լ����ݿ�ij־û������̳־û�������ֲ�ʽ�����Ѿ�֧������LRU�㷨������֧�ִ���get/put�Ȳ�������Ҫ����һЩEviction�Ĵ�����ֵ����ֵ���������LRU�㷨����������������Ƴ��ڴ滺����õ����̡�
���ݿ�־û�
���ڻ������ݿ�ij־û���������㷨��ŷ�ΪWrite-Through��Write-Behind��
Write-Through��Ҫ��ָ�������껺�����ݺ�ϵͳ��ͬ���������ݿ⣬ֱ��ȫ����ɽ�����
����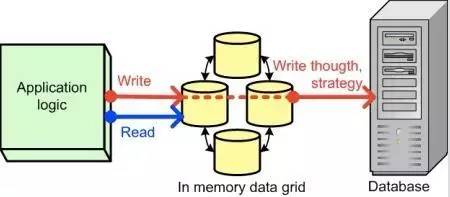
����Write-Through Cache
���Կ���Write-Through���Ծ�ȷ�������ݵ�һ���ԣ���Ȼ������ı��ǻ�Ӱ�����ܡ�
Write-Behind ��ָ�������껺�����ݺ�ϵͳ�Ѹ���д����Ϣ�м�����߶��У�����ȴ����ո��������ݿ⼴���أ��������Ϣ�м���ӳٸ��������ݿ⡣
����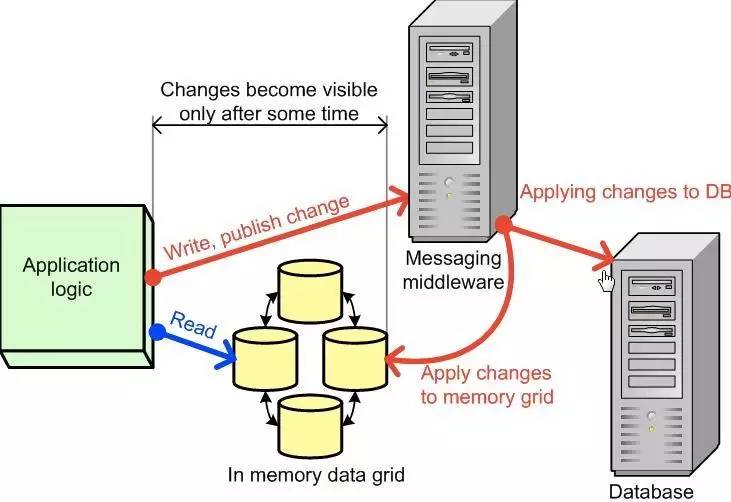
����Write-Behind Cache
Write-Behind�����õ����ݲ���Ϊ����һ���ԣ�Eventual Consistency��, �ڴ�������������ͬʱ����Ȼ��Ҫ�е�һ�����ݶ�ʧ�Լ��ӳٵijɱ���
�����ֲ�ʽ����ϵͳҲͬʱ�ṩ�˻������ݵļ�������Listener�����ڶ��ƻ�ʵ�����ݸ���֪ͨ���Լ�������Write-Behind���²��ԡ���ͼΪGemfire/Geode������������ṩ��before/after�¼���ͨ������ʹ��Cache Writer��ʵ��Write-Through���ԣ�ʹ��Cache Listeners��ʵ��Write-Behind���ԡ�
����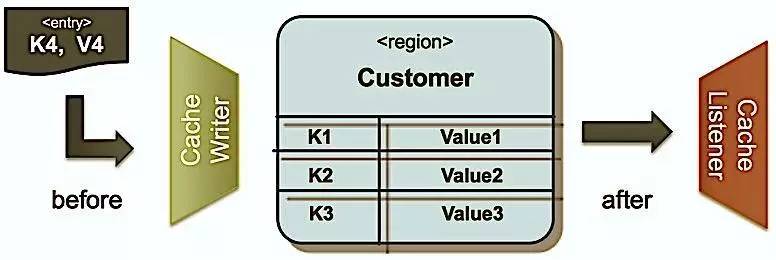
����Cache Listener
���ǵ��г����ݵ����м�ʱЧ�ԣ��Լ��־û���Ҫ�Ա������������鵵Ϊ�����������ǵIJ���EMS��Ϣ�м����ʵ��Write-Behind������²��ԡ�
����֧��ȫ�����������ģ��ٽ����ʣ���������֮������һ����
�����Ĵ�����
��������Ǵ��е����ż������зֲ�ȫ��ͨ����Ҫ�ŦԼ���أ���������ۣ��¼��µ�4����Ϊ�������ģ�����4�ؽԿɷ��ʵ���Ӧ�ã���������֮����������Ҫ����ݣ����ij���������ij����⣬�Զ��л������������������ģ�����ȫ��24Сʱ����Ͻ��ף���ʵ������ȫ���г�һ�������ޣ��������翪�У������ۣ��¼��£������ޱ��к��ؿ��У����ŦԼ��ʼֱ���ڶ��졣
����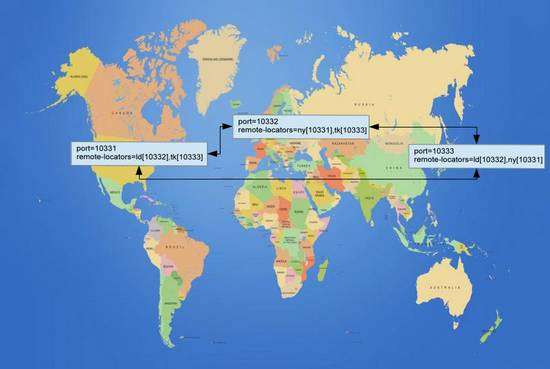
����ȫ����������ģ�WAN��
��ͼΪȫ����������ĵ�����������ϵͳ��Ҫ����֧��4���������ģ��أ�ŦԼ����������ۣ���
���ֲַ�ʽ�����Ʒ��֧��ȫ����������ģ�WAN���ṹ���������Ķ��Site֮���ͨ��Э�����ã�Gemfire/Geode�Ķ��������ļ�����������ͼ��
����
����WAN Site XML������Ϣ
����ÿ�����������Գɷֲ�ʽ��Ⱥ����������֮����ͨ�������������������ӹ�����
��������ͨ��
������������֮����ͨ��Locator��Sender, Receiver��ʵ��TCP/IP���֣��첽ͨ�ţ�Replication�ȣ�ÿ���������Ļ���Ⱥ����Sender��Ϊ���Ͷ�Ҳ��Receiver��Ϊ���ܶˡ�
Senderͨ��Locator��λ��Զ�˼�Ⱥ��Locator��Զ��Receiver�����������Զ��host��port��Ϣ��Ҳ�����ö������Sender��Parallel Gateway Sender����
����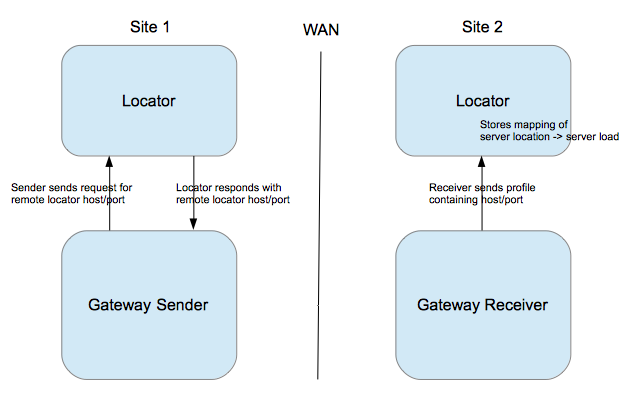
����WAN Sender / Receiver
�����ڲ���ʹ��Queue��Ϊ�����첽ͨ��������ͨ��Ack���ƣ������������ı�֤�����ݵ������ԣ�ͬʱQueue��ͬ��Ϊ�첽������Ч��ͬʱ����ϣ�һ���������ij����ⲻ��Ӱ�������������ġ�����������Ŀ���ͨ����·����ȫ�������������ӡ�
ͨ�������������ģ��Ƚϼ��ֵ�������Ҫ������ڲ����±�֤����һ�����Լ��������ڿ�WAN���µ������ӳ��ԡ�
��������һ����
���������IJ�������һ���Բ�������֤�������������ݵ�ͳһ��Ĭ��������ڶ���������IJ�������ijһEntry������£�ϵͳ������¼���ʱ���ѡ����µĸ�����Ϊ�������ݣ���������£������ȫ��ͬʱ�������Ĭ�ϻ����ѡ��Զ�˵ĸ��£��п��ܵ������ݲ�һ�£���ϵͳҲ�����Լ����������ѡ����¡�
�����г����ݵľ���Ҫ�����Ǵ�ҵ���Ϲ涨ijһ��������ijһ����������Ϊ���������Ƴ�ͻ���ȼ������������
���������ӳ���
��ȫ���������ĵ����ݴ��䣬Replication���������ڶ������أ������磬�����Լ����������С�ȣ��Ӻ��뵽���벻�ȣ������ӳ������ٺܴ���ս�Ͳ��ɿء�
Ȼ����������ο���ǣ�ҵ������ÿ���������Ĵ��ֻ��Ҫ���Σ��綫������ʱ����Ҫ���ʶ����������Ļ�ȡ�г�����Ϊ����ÿ����������ֻҪ��ÿ�ձ��кѵ��յ�EOD����ͬ��Replicated��ȫ�������������ļ��ɣ��ӳ��Է��滹�á�
Ȼ�����ǵ�ȫ������г���Ҫ����Ϊ����������ģ����������¼��ºܶ�FXϵͳ��Ҫʵʱ�г����ۣ�Ŀǰ���������֣�
��һ�������ӳ���Ҫ������һЩ��ϵͳ��ֱ���������������ġ�
���������ʵʱ���۵ȵ��ӳ�������ͨ��TIBCO RV��Rendezvous�� Routingͨ��UDPЭ�飬�����ɿ��ԴӶ��ﵽ��ʵʱ������ֱ�Ӵ���·�ɶ��������������֮��ġ�TIBCO��˾�������콢��ƷEMS��RVר����Ϣ�м����RV�����UDPЭ���ʺ�С��Ϣ����ʵʱ�Գ�����ʹ��TIBCO RV Reliableģʽ�Ѿ�����������Ϣ����150��/�룬50��/����ܵ����ܡ�
����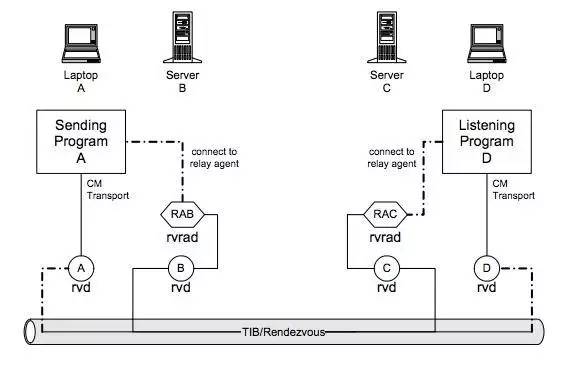
����TIBCO RVRD��Rendezvous Routing Daemon��
�����������ֽ��������Ŀǰ��ʱ����Ӧ��ҵ������
���������£����ӳ�ʵʱ�г����ݱ���
����������
������
ϵͳ����Ϊ������Ҫϵͳ���ʣ�����������ͻ���10-20+����Ƶϵͳ������������10-20+�����ͨϵͳ���籨�����������ȣ����ʣ��Լ�����м�ǧ�������û�ͨ����������������ʡ����и�Ƶϵͳ������Ƶ����д�����������û���Ҫֻ����ѯΪ����������Ϊ���ݸ�����Ҫ��������·�磬�����Լ�ȫ���ڻ������������������ڲ�ϵͳҲ���к������ݷ������ģ�������������Ҫ���ڲ��������������������ݰ汾, ����һ���������൱������������
�¼������ܹ���Event-Driven Architecture��
��ϵͳƽ̨����ܹ����棬���Dz������¼������ܹ�������TIBCO EMS��Ϣ�м������Ϊ��ϵͳͨ�ţ��ڽ���ͬʱ������ϵͳ���ϡ�
����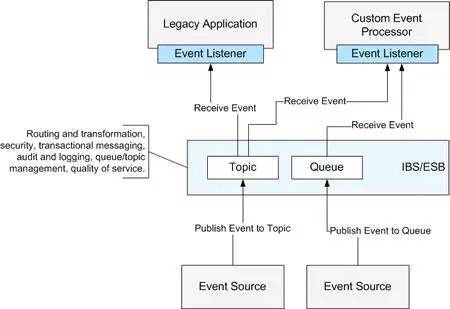
����Event-Driven Architecutre
�����Ϊ��ѡ��EMS������MQ��RabbitMQ, �Լ�����֮��Apache Kafka���������ô���ڹ�˾���������Լ�TIBCO˫�۱���Ҳ�����Ӳ��
�ڸ����´��£�EMS Queueͬ�����Դ�����Ϊ��ϵͳ����˼�ʮ��Queue���ֱ��������ݲ�ѯ�����ݸ��£����ģ�������EOD��������������������Replication,�Լ�����JDB Queue����Write-Behindͬ�����ݿ⡣���Կ�����ϵͳʹ�ø�Ϊǿ������м����Ʒ����֤ƽ̨�ȶ��ԣ����¡�
�������ӳ�
�����ʱ�䣬ϵͳ��Ҫ֧��QPS�����ڼ�������ǧ�������߷�������Щ�����ڴ�����In Memory Grid����������ơ���ijͳ����վ����������Gemfire 8��4���ڵ���Ƕģʽ�£�4G Heap, 1G������10��Threads10���ӵ�ƽ���������ɴ�70000/�룬дƽ��Ϊ23000/�롣
�г����ݶ������������Խϸߣ���ѯһ�㶼�Ǻ��뼶��ģ�������������г����ݵ��Զ�����ϵͳ����FX�ȡ���������һ�����ӣ�һͶ�и߹�˵�����һ�������˻���Traderʹ�õ��Զ�����ƽ̨�ȶ�����5���룬���������棨Revenue�����ܻ���ʧ1%�����߰�������ÿ�루����������ӳɱ������е㾪�˿��ţ������Լ������ݵ��ӳٵ���Ҫ�ԣ�ͬ�����ںཻܶ��ϵͳ�����������г�����ƽ̨�����ӳٶ����г�ƽ̨�ijɹ�������Ҫ��
��ʵ�У�����Ҳ��ѭī�ƶ���ȷʵ�����������ʱ���������ӣ����ô�����ʱ��15�������Ҷ�λ���ָ�����Ҳ����˴�������¹ʣ�ʱ����ǽ�Ǯ�������ڹ�ȥ�ı��ۣ�����ϵͳ������С�
���ݷ���
����һЩ��Ƶ���ݵIJ�ѯ��������ϵͳ���ݷ�������ܹ��õ�����Ⱥ��������ΪReplicated, ��Ⱥ���κ�һ�����ݽڵ㶼�����û������ݣ����ڼ�ȺClient�ˣ����ն˿ͻ���ϵͳ��Ҳ������һ�ݿͻ��˻��棬���������������졣
�����Ż�
����������������ֲ�ʽ�������ݣ���Ϊ�����洢������Ǽ�get(Key)����ô�������綼�ǹٷ����ݡ���ʵ�еIJ�ѯ��ԶԶҪ��get���ӣ�����Ȩ��У�飬����У�飬�������ݹ����������������ݲ�ѯ�����ݹ��˵ȣ�������KV���湦�ܣ�����Щ�߽����Ѿ�֧��OQL��SQL������������Index��, ��Ȼ���������������ֻ�����ߵ�Ƶ����������һ�ѣ�����Ҫ�е����¶��⸺����
Map��Reduce
����֮�⣬�ֲ�ʽ���˷ֲ�ʽ�洢��ȻҲҪ�����䲢�м��㣬MapReduce֮������
����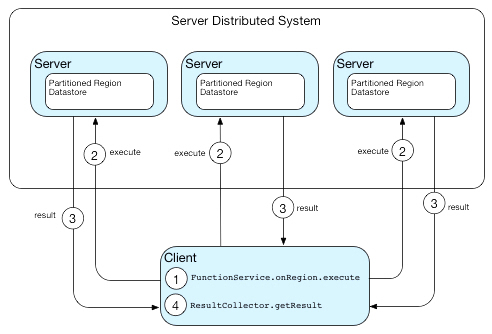
����MapReduce Execution
���ֲ�ʽ���涼֧�ֲַ�ʽ���㣯��ѯ��ͨ�����Ѹ��Ӽ��㣬��ѯ��װ�ɺ�����������߶�̬�ַ�����Ⱥִ�м��㡣Ч�ʷ��棬�ֱ����������ڵ����Ч�ʸ��ߣ�����̬�ַ����˸��õĸ���������Ȼ������Ҫ���л��������˲������ܣ������ֲ�ʽϵͳ������ʵ���Լ����л�����ʹ����Apache Thrfit֮��Ŀ�ܱ���Java���������л��ϵ�Ч�ʣ���
������ѯ������
������ѯ���߶��ģ�Subscribe������ʵʱ������Ϣ������ϵͳ�û�Ҳ����һ�ֱ�����ٲ�ѯ�ӳٰɡ�
�㲥���ಥ����
����һ�ֶ������ӳ��Եļ��������������Ч�㲥���ಥ���磬�����������ἰ��TIBCO RV��ע���䷢������ʵ�ַ�ʽ��������Ϥ��MQ��JMSģʽ���䴴�µĴ�������Ϣ��������ߣ�TIB����
RV��û�в��ô�ͳ�Ļ��ڶ���Queue�ķ���˻�����ƣ�ֱ����IP��㲥���ಥ��ʽ����Ϣ���͵�RV�����ϣ���ͨ��UDPЭ��·�ɹ㲥���͵�RV�������нڵ㣬���ն���ͨ��Subject��ƥ�������Ϣ���������ͻ��˶��С��봫ͳMQ��JMS�ڷ����ͨ��Topic����������Ϣ���е������ȣ��ٶȿ���ˣ���Ȼ�����ܷ���ͬʱҲ��Ҫ�е���Ϣ��ʧ�ķ��ա��������г�ʵʱ������˵���ǿ������̵ġ�
����RVҲ�ṩ��RV Reliable ģʽ��ͨ���Զ���ʵ��������UDPЭ�飬������Ϣ��������ش����ƣ���֤��һ���̶ȵĴ���ɿ��ԡ�����RVCMģʽ�������һ����������Ϣȷ�ϻ��ƣ���֤����ɿ��ԡ���Ȼ������ģʽ��������Ȼ�½�������ν������Ʋ��ɼ��Ҳ��
������Ƶд
ϵͳ�����˹��ڸ�Ƶд���µ����Ѱ�������⡣�����ᵽ��ʹ��TIBCO RV��ʵ�ֵĹ㲥�����辶��Ȼ�����ͬʱ��Щ��Ƶ����Ҳ��Ҫд��ֲ�ʽ���湩����ʹ�á�
Ȼ��ʼ��δ�����Ǵ�ཻ�ף�����ϵͳϰ�߲���ͬʱ����ʮ���ϰٸ��߳�ͬʱ��������Ҫ�����Ǻܶ༸������ϵͳ�趨��ÿ�ܣ�ÿ�쿪��ǰ��7�����㷢��д����ѯ�������˲����ɱ�Ĺ�Ч����ͼ��ϵͳij��3���ӵ�д������ͳ�ƣ����Կ����ӵڶ����ӿ�ʼ��Ƶд��top 3��������171000�ʣ�����ϵͳͳ���ǰ��շ�����ͳ�ƣ����Դ��Թ���ÿ��д�����ӽ�2800-17000+��ע���������д�������ǵ�����д�������ڲ������˶ಽ���ҵ�������������ںڿ����������ָ�Ƶд��ѹ������ʱ��ֱ��Ӱ��������Ⱥ���ȶ��ԡ�
���ⶼ��һ��ǿ��ϵͳ����Ҫ������ʹ����̣�����Ҳ����һ��ʼ����ƿ��ǵ���
����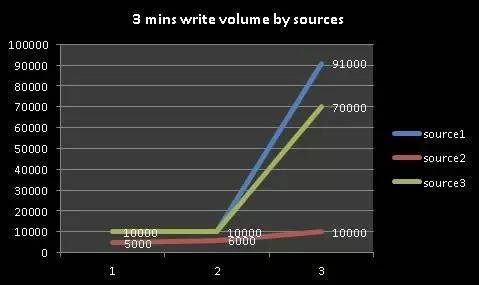
������ƵдTOP-3 In 3����
������һ��Ѫ���ܵ���ʵ������Ŀǰ��ʵ���ڷܶ�����С���ͨ������Thread Dump, GC log, �ֲ�ʽ����Debug Level��־�����¶�λ�������ڸ�Ƶд��ͬʱ��������Ҫ��ͬ�����౸���������ڵ�ͨ�ţ���������Ⱥ�����нڵ㶼���ڸ�Ƶͨ�ţ�����ʱ�����нڵ��쳣��æ���ܶ�ڵ㴦�ڵȴ�Ack״̬����������Ӧ����������ʹ�ܶ�ڵ㿴������Ӧ�ٶ�����Hung�����ﵼ�´Ӽ�Ⱥ�б�ǿ��Depature��
����
Ŀǰ����ʱ����ʱ���ڵ�ȴ�ACK��ʱǿ���׳��쳣���ͷ���Դ������������Ⱥѹ����
�������������¹滮���ݷ�������Ը�Ƶд��������������Redundancy Copy�Լ��ٽڵ���ͨ�ţ��Լ����������г��õ�����©Ͱ�㷨(Leaky Bucket)���߸��ʺϷֲ�ʽKV�����㷨Conflation�鲢�㷨��
����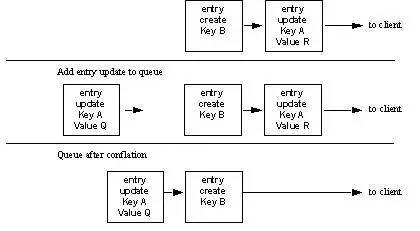
����Conflation�㷨ʾ��
�ֲ�ʽ�����ڻ�ú����洢����Ч���м������ܵ�ͬʱ��ͬʱҲ�����ֲ�ʽ��������Ų���쳣���ӡ�
�����߿���HA, �Զ�Failover
�߿��ã�HA High Avaiablity��ͨ������ϵͳ����߿����Լ����ݸ߿��ã�ͨ�����������ǿռ任ʱ��-���࣬���ܻ������ݣ��������ڱ������ݿ⣬�����������ġ�
�����߿�������
���ݵĸ߿����ڷֲ�ʽ�е�ͨ���������������ࣨRedundancy Copy���ˣ���������1-3������ֱ��ݡ���������1������ͨ���Ѿ��㹻����������������������ϸ�Ҫ����3�����ӣ�ͬʱ�������ݳ�����ʱ������1��������ʹ��ͬʱ����2�������ݻָ���Ȼ�����ݱϾ�����Դ�������ʽ��Լ����ܶ������Ӱ�졣
�����߿��÷���
����һ����������ͨ������Ҳ�ǿ��������ͬ����ͨ�������������Nginx����˫���ȱ���Keepalived��DR�����߸��ؾ��⣨F5��LVS����ʵ�ָ����Լ��߿��ã���Ⱥ�ڲ��ڵ���ͨ��ͬʱ�������Locator���ⵥ�㣬����ѡ���㷨�ȡ�
����Failover
����Failover��ͨ����Ⱥ�ڲ����и��ԵĻָ���ʽ����ͬ�����첽���ݱ��ݻָ�������ѡ�����ڵ����ȡ�
��Ⱥ֮��Ҫ��ȽϸߵĻ�ͨ���������ȱ��ݼ�Ⱥ�����ݿ⣬����ƽ̨��ÿ���������Ķ�������DR���ֱ�����Ⱥ��
����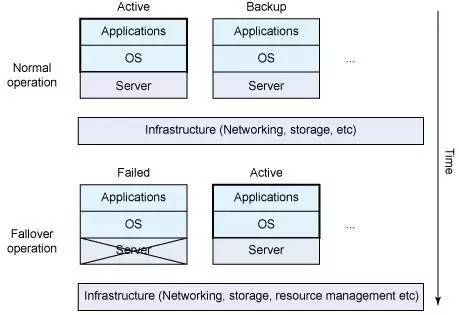
����ϵͳFailover
����ϵͳ����ȺFailover�����˹���Ԥ����ԭ���������Զ�failover��������ǻ�û�����ܵ�ʶ�𣬿��٣�ƽ���л���
ͨ��˫����˫��Ⱥ���ֱ���Ȼ��Դ���Ľϴ��Ҵ����ʱ�䴦����Դ�˷�״̬��Ȼ�����ڽ��ڽ������������DZ���ͱ�Ҫ��Ͷ�롣
���������ĵ�Failover��������ܣ��ֿ����գ�Ŀǰ�Ѿ�����δ��Ŀ��֮һ��
������Ϣ�м��
��Ϣ�м���ڸ߿�����ͬ�����ݾ������صĽ�ɫ����ijЩ�������ݿⲻ����ʱ����Ϣ�м���䵱��ʱ�����壬������Ϣ���¼������ݵĶ�ʧ����Ҳ��Ϊʲô��Ϣ�м���ڽ��ڻ������㷺���õ�ԭ��֮һ��
����֧����ʷ���ݷ��ʲ�ѯ
�г�����ʷ������Ȼ����ʵʱ����ϵͳ���岻���Ƕ��ںཻܶ�ײ��ԣ�����ϵͳ������Ƿ���������Ҫ��ȡ����ʱ��ε���ʷ����������Ϣ��
���ں�����ʷ���ݵĹ�������ѯ��ʹ�����Ϊ����ϵͳ��һ����ս����ͳ�Ĺ�ϵ�����ݿ����ܺ�֧��֧�ź������ݣ����������ݲֿ����CubeҲ����Ԥ�ȶ��ƣ���������ʵʱʹ�á�
���ǵķ�����Ȼ�ǽ����ڴ�����ƽ̨���ֵ� HBase + HDFS��Hadoop + ZooKeeper��
����
����ZK + HBase + Hadoop/HDFS
ֵ�������ǣ��������ǵ�ƽ̨�����칹�¼������ܹ�������ֻ��Ҫ�����ݱ���ģ������һ��HBase��Ϣ���У�ͨ��������ֱ�ӱ�����HBase���������Ŀǰƽ̨���ܼ�������ɳ����֮���������µ�API������ϵͳʹ�ü��ɡ�Ŀǰ��ƽ̨���ڿ��������С�
����֧�ֿͻ��˶���Э�����
�����¼������ܹ�
������ƽ̨�ļܹ��У��¼������ܹ�����Ϊƽ̨�칹������Ѿ��������������ƽ̨�����ԣ�ϵͳͨ�ţ��Խӡ�
����RPC-X
��Ͷ�е���Ϣ������ʩ���ţ��ְ������ǰ����һ���з����ڲ�RPC����SOAƽ̨��ܣ��������в��ŵ�ϵͳ֮���ͨ�ţ��������ҳ�֮ΪRPC-X���ˡ�
�似���ܹ������������ԭ��ϸ���ˡ������Ŀ�������Ϲ�˾�ڲ�ϵͳ֮���ͨ�ţ�������ƽ̨��Unix, Linx, Windows�ȣ��Լ�������C/C++, Java, .NET�ȡ�
�书�ܺ����ˣ�
-ϵͳ֮��RPCͨ��
��װ��˾�ڲ���Ϣ�м��ƽ̨ͨ��ϸ��
��װ��˾�ڲ�����Region, ��������ͨ��ϸ��
��װ������ʱ����Ϣ
�ṩ�������÷���Ŀ¼����������ÿ�����ͻ�������
��ƽ̨��������ͨ��
ϵͳ֮��߿��ü�Failover
�ṩEvent Bus����
����OSGi
�ṩRPC, EMS, RV, REST, Broadcast, On-demand, Monitor, Subject
����ʵʱϵͳ״����أ���ά������
ϵͳ��أ��Զ���ά�Ǵ���һ��������ϵͳƽ̨����ȵ�ָ��֮һ��
����ϵͳ���
�г�����ƽ̨������Ĭ�Ϸֲ�ʽ��Ⱥ��ƷGemfire/Geode�Դ��ļ�Ⱥ��أ��������ܼ�صȹ���Ϊ��Ҳ�����з����壨Dashboard��ʵʱ��������������ļ�Ⱥ�еĽڵ����״����EMS��Ϣ���У��ڴ�ʹ�ã�CPUʹ�ã�Heartbeats�����̣����ݿ��ÿ������Ľ���״����
����ϵͳ��ά
ϵͳ��ά���ڹ���ƽ̨��������ʩ����Ҳ�������з��Զ�������ƽ̨������ʵʱ��̬���ջ���������ȫ������������ģ������ÿ���������״�����������ù���ÿ�����������ʱ����Sheduler��
���⣬����ƽ̨ϵͳ���棬Ҳ��������¶һЩJMX�ӿ��Ա����϶�̬������Ӫ���Լ�Ӧ�Ը���ͻ���¼���
Ŀǰ��������ά�����Զ���ά��DevOps���о��롣
��������
���� ������ģ���������ܹ��˷ֲ�ʽ�г�����ƽ̨����ͳ����ϵͳƽ̨��������������Ȼ���������븴���ԣ�����ȫ�ԱȻ�����ƽ̨��Ȼ���ڼ����ĺ�������ͨ���������Ž��ڼ�ܷ��ɵ�Ԥ�ڼ��������£������뻥�������������������ݣ��Ƽ��㣬��������������AI�����ѧϰ�ȼ����������������ϡ�
�������߽���
����
�����Erix�����־�ְ��Nomura���μ���VPְ��2004����2015������ְ��Citi�����뼼���з������μ���VP��ְ��ע����ϵͳ�����ܹ���ǰ�ؼ�����������������գ��������գ����÷��գ��Ŵ�ϵͳ������ѹ�����Լ��̶����������ϵͳƽ̨��Ƽ��з������˼������ںš���������TechBooster����
������������������ʧ֮���ۡ�������Huawei LiteOS��ͬİ·��������ı�������µµ��Ϊ��������ĺô������ڶ�����Ǿ͵����ĩ �� �Ķ�ԭ�� ���������μ�1��7��-8���ڱ����ɻ�Ϊ���졢InfoQЭ���Huawei LiteOS�ڿ��ɴ����ɡ��������С��飬��һ��2��1ҹ�ķ�� ������ʶ�����¶�ά��ֱ�ӱ�������
�������ռ���
��������·�ͼƬ�����Ķ�
����
�����ǡ����������ǡ�ҵ����������˾�ķ�չ�����������ôվ��































����˵�������а�