 )
)������Ϸ����ں����ɿ��ٹ�ע��
�������룺�������� - ��С��
����2017��1��31�գ����ǵ����߷��� GitLab.com ���������ص��¹ʡ�����¹�����ɾ���𣬵��������ǵ������ݿ����ݶ�ʧ��
����
��������¹ʵ�����GitLab����ʱ���жϡ����ǻ�������ʧ�˲����������ݣ����ָ��������ص��ǣ����ǻ���ʧ�����ݿ����ؼ�¼���ݣ�������Ŀ��ע�͡��û��˻�������ʹ���Σ���Щ���鶼����2017��1��31��17:20��00:00�����ġ���ʹ���ֹ۵ع��ƣ������¹�ҲӰ�쵽��Լ5000����Ŀ��5000�����ۺ�700�����û��˻������¹ʷ���֮��GitLab.com�ϵĴ���ֿ��wiki����ʹ�ã�������Щ����û�ж�ʧ���ݡ�GitLab.com����ҵ���û���GitHost�û��Լ����йܵ�GitLab CE�û���û���յ��˴��¹ʵ�Ӱ�죬Ҳû�����ݶ�ʧ��
������ʧ���������Dz��ɽ��ܵġ�Ϊ��ȷ���Ժ��ٷ��������¹ʣ����Ƕ�GitLab.com�ϵIJ��������ݻָ��������˶���������ڱ����У����ǻ���������¹ʵ�����������������β��ȣ��Լ�����Ҫ��β������Ժ��ʱ��ž������¹��ٴη�����
�����������ڴ˴�GitLab.com�¹����ܵ�Ӱ���ʧ���ݵ��û���������ֱ�Ǹ���ұ�����ΪGitLab��CEO������GitLab��ÿһ���ˣ�������ϵ�Ǹ��
�������ݿ�����
����GitLab.comĿǰʹ�õ���һ̨����������һ̨���÷�������˫���ȱ�ģʽ�����÷�����ֻ������ʧЧʱʵ��Ԯ���������������£����еĸ���ƽʱ�����������ݿ����������ɵģ��Ⲣ����һ������ļܹ��������ݿ��������������db1.cluster.gitlab.com���������ݿ��������������db2.cluster.gitlab.com��
������ʵ������ǰ����Ϊ����db1.cluster.gitlab.comһ̨��������Ϊ���ļܹ����������ģʽ�������Ǿ��������ܶ����⡣���磺
2016��11��28�գ���project_authorizations��������͵������ݿ�崻�
CI��ʱ���ڷ����������ѯ��������������GitLab.com�ٶ�
�ֲ������ݿ⸺�ط�ֵ�ֲ�
�����¼�����
����1��31�գ�һ������ʦ�����ǵĹ��������жԶ�̨PostgreSQL���������������á�ԭ���ļƻ���ʹ�� pgpool-II �����Կ��ܲ���ͨ���Ѳ�ѯ���������������������ؾ��⣩���Ӷ��������ݿ�����ĸ��ء��������Ҫ�����������������ʾ��Infrastructure#259��
����± 17:20 UTC: �ڿ�ʼ����֮ǰ�����ǵĹ���ʦ����һ���������ݿ��LVM���գ�Ȼ��������뵽�˹����������ô����Ŀ����Ϊ��ȷ���������ݿⱸ�����£��Ӷ��ܵõ����Ӿ�ȷ�ĸ��ز��Խ���������������ÿ24Сʱ��Ҫִ��һ�Σ�����ÿ��01:00 UTC����������ʦû�����Զ������İ汾����Ϊ����Ҫ���������ݿ���ӽ��ı��ݡ�
����± 19:00 UTC: GitLabs.com��ʼ�������ݿ⸺����������������ǻ�����spam��ɵġ����������ڱ����¼�֮ǰҲ��������ֻ��û����ô���ء���θ���������ɵ������ǣ�һЩ�û���������������ۣ�����������merge request�����ǻ��˼���Сʱ���ø������µõ����ơ�
�����������Ƿ��֣������θ��������ԭ���ǣ���̨�и���ҵ���Ƴ�һ��GitLibԱ��������ص��û����ݡ���Щ�˻����ݱ������ǣ�Ȼ�����ر��ƻ�ɾ�������Ǹ��������ĵ��������������ľ�����Ϣ����������鵽�����Ƴ�spam�û�ʱ��Ӧ��ʹ��Ӳɾ����.
����± 23:00 UTC: ��Ϊ���������ˣ����ǵı���PostgreSQL���ݿ�ı��ݽ��̾ͱ��ϵ÷dz���������Ϊ���ݷ�������ҪWAL�β�����ɱ��ݹ��̣�����WAL���Ѿ��������������Ƴ��ˣ����Ա���ʧ�ܡ�GitLab.comû��ʹ��WAL�浵�����Ա��÷�����ֻ���ֶ�����ͬ������������Ҫ�ӱ��÷��������Ƴ����е����ݺ�Ŀ¼�������� pg_basebackup������ʵ�ֽ����ݿ�������������������÷�������
�������ǵ�һ������ʦ���ǰѱ��÷������ϵ�����Ŀ¼ȫ��ɾ���ˣ�Ȼ��������pg_basebackup���ܲ��ҵ���pg_basebackup�����Ժ�����ˣ������Ѿ����˨Cverbose ѡ�������û�в����κ������������������˼���pg_basebackup֮����Ϊû���㹻�ı���������������max_wal_senders���ƣ����������ӵ����������ˡ�
����Ϊ�˽��������⣬���ǵĹ���ʦ������ʱ���� max_wal_senders ����������Ĭ�������� 3 �������� 32������Ӧ����һ�ı�ʱ��PostgreSQL�ֲ��������ˣ�˵������̫�� semaphores����������ܿ��������� max_connection ��������̫�ߵ�ʱ�����������ǵİ������棬�����ֵ������8000�����ֵ��Ȼ���õ�̫���ˣ�����������һ��֮ǰ���õģ�����֮������Ҳһֱû���⡣Ϊ�˽��������⣬�����ְ�������õ�ֵ������2000�����PostgreSQL���ڿ������������ˡ�
�����ܲ��ң�֮ǰ�������鲢û�ܽ�� pg_basebackup������ִ�б��ݵ����⡣һ������ʦ��������һ��strace���������������strace��ʾ�� pg_basebackup��һ��poll call��������ˣ����dz���֮��Ҳ�ṩ����ʲô�����õ���Ϣ�ˡ�
����± 23:30 UTC: һ������ʦ��Ϊ�������� pg_basebackup����һ�����е�ʱ���ڱ��ݷ�����������Ŀ¼���ϴ�����һЩ�����ļ�������������Ӧ�������������������Ļ���pg_basebackupӦ�ûᱨ������ӡ��������Ϣ��Ȼ����û�У���������������ʦҲ���ҿ϶��Լ��ǶԵġ���������Ժ�ű�����һ������ʦ�����һ��ʼ��û����Χ����˵����������Ϊ�� pg_basebackup��ȴ������������ͱ�������ʱ�Ż��з�Ӧ������������ôһֱ�����صȴ������ź�����Щ�����ڹ���ʦ��ά�ֲ��ﶼûд�� pg_basebackup�ٷ��ĵ���Ҳû�С�
����Ϊ���ñ��ݽ����ܹ��ָ���һ������ʦ�����PostgreSQL�����ݿ�Ŀ¼�����������ĵ���Ϊ����������ڱ��ݷ����������ġ���Ҫ�����ǣ�ǡǡ������������������������еġ���������ʦ����һ�����ʱ�䷢���˴����������Ѿ���300G�����ݱ�ɾ���ˡ�
��������ʦ�Ǹ���Ѱ�������ݿⱸ�ݣ�������Slack���������ź����ǣ����е�Ѱ�ұ��ݵ�Ŭ��������ʧ���ˡ�
�����¹ʺ�Ļָ�����
�������־��棬����ֻ�ܳ��Իָ������ˡ�ͨ���������������飬����ֻ��Ҫ����������ݿⱸ�����ָ��ͺ��ˣ����ܲ����ܱ�֤100%û�����ݶ�ʧ������GitLab.com�����DZ������������ֶ���֧�����ݻָ��ģ�
ÿ24Сʱʹ��pg_dum����һ�α��ݣ��䱸�ϴ���Amazon S3���ɵı�������ijʱ�Զ�ɾ����
ÿ24Сʱ���������ݿ���һ��LVM���ա������յ��빤������������ʹ�������ܹ��ڲ�Ӱ����������������½��а�ȫ�IJ��ԡ�������ֱ�Ӳ����������ݿ���������ݿ⡣
������Զ�������������洢Git���ݵ�NFS��������Azure���̿��ա���Щ����ÿ24Сʱ��ȡһ�Ρ�
��PostgreSQL����֮������ݿ�������ҪĿ����ʧЧ��Ԯ���������ֱ���
��������¹ʵ��������Ϊ���ݹ���ʧ�ܣ����������Ѿ������������ͱ��ݷ������϶�ɾ���ˣ��������������κ�һ���������ָ������ˡ�
����Database Backups Using pg_dump ʹ��pg_dump�������ݿⱸ��
��������¹ʷ�����������ͨ��pg_dump�������ָ������Ǹ���û�ҵ��������ݡ�S3 bucket�ǿյģ�����û�п��������ָ��Ľ��ڱ��ݡ�ͨ������һ���ļ�飬���Ƿ����ڱ��ݹ�����ʹ�õ���pg_dump 9.2�汾����Ϊ�ֶ��ĵ����ݿ���PostgreSQL 9.6�汾������Postgres��˵��9.x�汾����Ŀǰ���е������汾������������汾�ŵ�С���������pg_dump���ݹ����в������Ӷ�Ҳ��ֹ�˱��ݹ��̡�
����֮���Ի������ݿ�汾�IJ��죬��Դ�������ǵ�Omnibus packages�Ĺ�����ʽ��Omnibus packagesĿǰͬʱ֧��PostgreSQL 9.2��9.6�����汾���������û�������ͬʱ֧���ֶ���������ͨ�����ṩ����������������Ϊ�������ȷ�����ݿ�汾�ţ�Omnibus package��Ҫȥ������ݿ⼯Ⱥ��Ӧ��PostgreSQL �汾��ͨ��$PGDIR/PG_VERSION���Լ�����Ŀ¼�µ�$PGDIR����ȡ������������PostgreSQL 9.6�汾ʱ��Omnibus�ͻ������ж����ƴ���ʹ��PostgreSQL 9.6��������� PostgreSQL 9.2��
����pg_dump���ݹ������ڳ���Ӧ�÷�������ִ�еģ����������ݿ����������ΪPostgreSQL���ݿ϶�����Ӧ�÷����������У�Omnibus��û�ҵ�PostgreSQL�汾�ţ������Զ����ó���PostgreSQL 9.2����һ��Ϊ������ˣ��汾���죩����pg_dump��������ֹ��
�������������������cronjob�ǿ���ͨ���ʼ��Ѵ���֪ͨ���ͳ����ġ�������GitLab.com��˵����Ϊ�����õ���DMARC���ܲ��ҵ���DMARC������cronjob���ʼ�������͵��������д�����Ϣ֪ͨ���ʼ����ܡ������ζ�����Ǵ�����û����ʶ�����ݹ���ʧ���ˣ�ֱ�����²��á�
����Azure ���̿���
����Azure���̿��շ������������������ɿ��յġ���ʵҪ����Щ�����лָ��ض������ݿ飨���綪ʧ���û��˻���Ϣ���Dz������ģ����������Ͽ��Իָ������յ���Ҫ�����ǵ����̻�����ʱ��ֱ�Ӷ����̽��лָ���
������Azure�У�������һ����Ӧ�Ĵ洢�˻���Ȼ��洢�˻��ֺ�һ�������������ζ�Ӧ��ÿ���洢�˻��д�Լ30T�Ŀռ����ơ����ӻָ����յ���Ӧ��ͬ�洢�˻�������ʱ�����Ǻܿ������ɵġ�����������ò�ͬ�洢�˻����������ָ����յ�ʱ��������̹���Ҫ��Сʱ����������ܸ㶨�ˡ����磬���Ǿ�����һ����������������һ�����ڲŻָ�����Ҳ�����Dz���̫�����ڿ������ַ�ʽ��
����NFS�����˿��չ��ܣ��������������ݿ��������û������Ϊ���Ǿ������ǵ����������ֶ�����������������еı��ݺͻָ������ˡ�
����LVM����
����LVM������Ҫ�����������������������ݵ����������ġ���ʽ��Ϊ����������Ŀ�ģ����Բ����Ŀ��մ����Ͳ����������ֱ��ָ��ġ���崻�������ʱ��������ͷ���������գ�
һ�����������ǵĹ�������ÿ24Сʱ�Զ������ģ����ǻ���������崻�����ǰ24Сʱ���Ҵ����ġ�
һ�����������ǵĹ���ʦ��崻�ǰ6Сʱ���Ҵ����ġ�
���������ɿ���ʱ�����ǻ��ȡ���²��裺
��������������һ������
�������������տ�������������
ʹ����������½�һ������
��Կ��ղ��������ݿ⣬�ϵ�һ���������ӣ���ֹ�����¼�������
�����ָ�GitLab.com
����Ϊ�˻ָ�GitLab.com�����Ǿ������¹�ǰ6Сʱ�������Ǹ�LVM���գ���ʵ��Ҳ�����Ǽ���������ʧΨһ��ѡ����Ϊ����һ���������¹�ǰ24Сʱ���Ҳ����ģ��ָ�Ч���϶�����6Сʱ����ã�������ָ��������Dz�ȡ�����²��裺
�����еĹ������ݿ⿽�����������������Ƕϵ������������ӡ�
ͬ���أ��������������������ݿ�Ŀ��գ�������������ջ���������������Ϣ����ʵ��������������Ҳ��ȷ�ϣ���
ʹ�ò���1�еĿ��������������ݿ⡣
ʹ�ò���2�еĿ������÷ֿ⡣
ʹ����һ���е����ݿ��������ָ��������ӡ�
���������ݿ������ϵ�100000��ȷ�����²������û�ID�����崻�ǰ���û�ID�ظ���
�ָ�GitLab.com��
�������ǵĹ�������ʹ�õ���Azure classic����û�п�ͨPremium Storage����ôѡ������ΪPremium Storageȷʵ�ܹ������Ľ�����ô��̲����dz�������������Ϊ�˻ָ����̵���Ҫƿ������ΪLVM���ձ����ʹ洢��������������ϣ����������������ָ����ݵ�ѡ��
��LVM���ջָ�
��PostgreSQL ����Ŀ¼�лָ�
��������������������漰�����������ݿ�����������ʵҲûʲô�����Ϊ��������Ŀ¼Ҫ��һЩ����������ѡ���˵ڶ��֡�
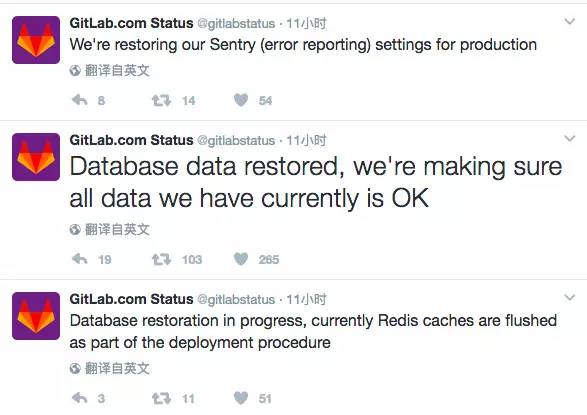
���������ݴӹ����������������������������˴�Լ18Сʱ����Ϊ��Щ�洢���̶������̵���ʽ������ͨ���ٶȷdz��ͣ���Լ60Mbps��������Ҳû������Щ���˵Ĵ洢������premium�ˣ����Ծ������ܵ����⡣���ǵ���������ʹ�����������ƿ�����������ô���ģ�ƿ�����ڴ洢�����ϡ�2017��1��31�� 17:20 UTC �������������Ժ����������ܿ�ʼ�������ݿ�ָ��������������ӣ��ˡ�
����2017��2��1�� 17:00 UTC �� ����Ŭ���ָ���Gitlab.com���ݿ⣬�����������ӻ�û��á������������ӵĻָ����ڵ��������Ĺ������ݿ������LVM������ʵ�ֵģ��������ᴥ�����������ӵ��Ƴ������ַ����ܲ���һ��������ݿ����SQL dump��Ȼ����������뵽���ǻָ���GitLab.com���ݿ��
������Լ��18:00 UTC���ң�������������յĻָ������������������Ӳ�����������ȷ��һ�ж���Ԥ��һ����
��������崻��¹ʵĹ���˵��
�������ſ��ϲ�����Ŀ�ģ����ǰ����еĹ��̶���¼���˹�����Google�ĵ�����ǻ��ѻָ��Ĺ�����Youtube�Ͻ�����ֱ������ߵ�ʱ����5000��ͬʱ�����տ����տ����������˵�ʱ�εڶ�������Ƶ�ķ�ʽ�ܺõظ������û������������ָ����̵����������������ǻ�������Twitter������Щ������ֱ�������ڴ�����Ϣ��
����
�����������ĵ�һ��ʼ��ֻ��GitLabԱ�����ŵ�˽���ļ�����Ϊ�������˵�����ɾ���ݵ����¹ʵĹ���ʦ�����֡������ǹ���ʦ�Լ�����ȥ�ģ���Ϊ���ܹ�ֱ�湫�ڣ����������ǻ��ǻ�������������˱༭��������������ʦ��Ϊ�����Լ������ֳ����ڹ�����Ұ���е����졣
�������ݶ�ʧ��ɵ�Ӱ��
�������ڷ�Χ��2017��1��31��17:20 UTC ��23:30 UTC ֮�䴴������Ŀ�����⡢����ε��������¹ʶ���ʧ��Git�ֿ��WiKi��Ϊ�ǵ�����ŵģ�����û���ܵ�Ӱ�졣
����Ŀǰ���ѹ��Ƶ����ݶ�ʧ�ľ�ȷֵ����������Ԥ�����ٶ�ʧ��5000����Ŀ��5000��ע�ͣ�Ԥ�ƴ�Լ700���û���������Ϣ�������¹�ֻӰ��GitLab.com���û����������йܵ�ʵ����GitHostʵ������Ӱ�졣
������GitLab������Ӱ��
������ΪGitLab����Ҳ��������GitLab.com�ڹ�����������������崻��¹ʴ�ij��������Ҳ�����ǵĹ������������ѡ����ֿ����߿����ñ��صĴ���ֿ�������������Ǵ����������Ϊȴ���ò��Ƴ١�����ʹ����˽��GitLabʵ��������һƪ���ġ�GitLab.com���ݿ��¼���������˽��ʵ��һ���������漰��˽��/���й�������ʱ�ͻ����ã������漰����ȫ�������ˣ�����������������GitLab.com������ʱ�����°汾��վ�Ŀ���������
�������ǻ���һ������ŵ�վ�� https://monitor.gitlab.net/ ������ء�Ŀǰ���վ�㲻�ܴ�����վ�ڷ���ͣ���ڼ����������û����ء������˵��ǣ����ǵ��ڲ����ϵͳ������վ��Ҳ�ǻ������ǵ��ڲ�ϵͳ�����ģ�û���յ��˴��¹ʵ�Ӱ�졣
������Դ����
����Ϊ�˶Բ����ĸ���������и�Դ���������Dz�����һ�ֽ�����5��Ϊʲô���ļ��������ǰ������¼��ֳ�������Ҫ���⣺��GitLab.com崻����͡����˺ܳ�ʱ��Żָ�GitLab.com����
��������1��GitLab.com崻�����18Сʱ
ΪʲôGitlab.com��崻���������Ϊ�������������ݿ�Ŀ¼�µ������ݿⱻ��Ϊ�����ɾ���ˡ�������Ҫɾ���ݷ������ϵ����ݿ�ģ������С��ɾ�������������ϵ����ݿ⡣
Ϊʲô���ݿ�Ŀ¼��ɾ���ˣ�������Ϊ���ݿⱸ�ݹ���ͣ���ˣ�Ҫ�����������¹������ݷ���������˾�Ҫ��PostgreSQL���ݿ�Ŀ¼����Ϊ�ա���һ��ղ���ϵͳ�����Զ���ɣ������ֶ�����������ά�ĵ���Ҳû����ȷ˵����
Ϊʲô���ݹ��̻�ֹͣ����������Ϊ���ݿ��һ���쳣���ط�ֵ��������ݿⱸ�ݽ���ֹͣ��������ܿ�������Ϊ����������WAL���ڱ���֮ǰ�ͱ�ɾ������ɵġ�
Ϊʲô���ݿ����ָ���ͻȻ�����������������һ���������������¼�ͬʱ������ɵģ�spam���������࣬�Լ���̨������ͼɾ��һ��GitLabԱ�������Լ���ص����ݡ�
ΪʲôGitLabԱ�����ݻᱻɾ����������ɾ����Ա���˺ű��ٱ����á����ǵ�ǰ������������ٱ���ϵͳ̫���ӱ����ϸ�ڣ���˶Ը�Ա����Ϣ��������ɾ��
��������2���ָ�GitLab.com����18��Сʱ��
Ϊʲô�ָ�GitLab��Ҫ����ô����ʱ�䣿����GitLab.com�Ļָ�ʹ�õ��ǹ������ݿ�Ŀ���������������й����ٶȽ�����Azure������ϵģ����һ��Dz�ͬ������˸�������
ΪʲôҪ�ӹ������ݿ���ȥ�ָ�GitLab.com �� ���� ��Ϊ���ݿ������û��Azure���̿��գ�ʹ��pg_dump�ӳ�������ݿⱸ���лָ��ֲ��ɹ���
Ϊʲô�������ӱ��ݷ��������ݿ���ʵ�ָֻ������� Ϊ���ñ��ݹ����������У��������ݿ�������ϵ��������ݱ�����ˡ��������������ӱ��ݷ�������ʵ���ֱ��ָ��ˡ�
Ϊʲô��ʹ�ñ��Ļָ����̣� ���� ���Ļָ�������Ҫʹ��pg_dump��ִ�����ݿ�������ݡ����������Ϊʹ����PostgreSQL 9.2�汾��ʧ�ܣ�����û�����κ���ʾ��GitLab.comʹ�õ���PostgreSQL 9.6�汾����9.2�а汾���죩��
Ϊʲô���ݹ���ʧ��ȴû���κ���ʾ�� ���� ����ʧ�ܺ�ϵͳ�Ƿ����˴�����Ϣ�ģ����������Ϣ��ͨ���ʼ������������ʼ������ն������û���յ�������ʾ���ʼ���ϵͳ�Զ����͵ģ����ҳ����ʼ�֮��û�б�ķ�ʽ�ܽӵ�������Ϣ�ˡ�
Ϊʲô�ʼ��ᱻ���գ� ���� �ʼ�����������Ϊ�����ʼ��ķ����������⣬��Щ�ʼ���������DMARC��ǩ��Ҫ��
ΪʲôAzure���̿��չ���û�У������ݿ⣩�� ���� ��Ϊ������Ϊ���������ı��ݷ�ʽ����Ӧ����������ˡ�����һ��ԭ���ǣ��ӿ����лָ����ݿ��dz���������Ҫ������ʱ�䣩��
Ϊʲô���ݹ��̣������⣩û�����ճ��IJ����з�Ӧ������ ���� ��Ϊ������Թ��̸�����û�����ˣ�Ҳ����˵���ճ��Ĺ�����û���˶Լ��鱸�ݹ����Ƿ���Ч����
�����Իָ����̵ĸĽ�
��������Ŀǰ����Ҫ������Ҫ�����ǵĸ��ָֻ����̽������Ľ�����������������¼������⣺
Update PS1 across all hosts to more clearly differentiate between hosts and environments (#1094) �����������ϸ���PS1��ʹ�������뻷��֮��IJ����������
Prometheus monitoring for backups (#1095) ʹ����������˹ϵͳ����ⱸ�ݹ��̣����̱��������Լ����DMARC�����ʼ�������ȥ�����⣩
Set PostgreSQL��s max_connections to a sane value (#1096) ��PostgreSQL��������������õ������ķ�Χ
Investigate Point in time recovery & continuous archiving for PostgreSQL (#1097) ����PostgreSQL����ָ��Լ������鵵����
Hourly LVM snapshots of the production databases (#1098) ���������ݿ������ΪһСʱ��LVM����
Azure disk snapshots of production databases (#1099) ���ϲ����ݿ��Azure���̿���
Move staging to the ARM environment (#1100) ��������������ARM��Azure Resource Manager ������
Recover production replica(s) (#1101) �ָ�������������
Automated testing of recovering PostgreSQL database backups (#1102) �Զ����Զ�PostgreSQL���ݿⱸ�ݵĻָ�
Improve PostgreSQL replication documentation/runbooks (#1103) �Ľ�PostgreSQL�����ĵ�/�����ֲ�
Investigate pgbarman for creating PostgreSQL backups (#1105) ��������ʹ��pgbarman������PostgreSQL���ݵķ�����崻������У����˽���GitLabʹ��pgbarman���������ݻָ������ǵ�ʱGitLab��û�����ù����ַ�����
Investigate using WAL-E as a means of Database Backup and Realtime Replication (#494) ����ʹ��WAL-E�������ݿⱸ�ݺ�ʵʱ���ݵķ���
Build Streaming Database Restore ������ʽ���ݿ�ָ�����
Assign an owner for data durability ָ��ר�˸������ݵij־���
��������Ŀǰ�����ִ������÷������Լ����ø��ؾ��⣬�������������б����ҵ�ϸ�ڣ�
Bundle pgpool-II 3.6.1 (!1251)
Connection pooling/load balancing for PostgreSQL (#259)
�������ǹ�ע���ص�������θĽ����ǵ��ֱ����ƣ������������Գ����ݻָ������á����ԣ����Dz�����ӡ���ֹ����ʦ����������������ij��������ֽǶ���ʵ�ְ�ȫ����Ϊ����ʹ���ǰѽ���rm���Ҳֻ������ֹ����ʦ��Ҫ������ rm -rf /important-data ����Ĵ��������ַ�ʽ��������ֹ��������������������ܵ������ݶ�ʧ�����������
����������Ϊ����Ļ�����Ӧ�������ּ�ʹ�㷸�˴���ɾ�����ݣ�Ҳ�����ָ�������֤��ϵͳӰ����С�Ļ��������Ҫ����Ҫ�ճ�ִ��һЩ���̣�����Ҫ���ײ��ԣ����ع������磬�������ھ������ֽ���һЩ���̣��ÿ����߿��Զ����ݿ�Ǩ�ƽ��в��ԡ�����ϸ�ڿɼ������ڹ���������ִ�кͳ���RialsǨ�ƵĹ��ߡ�.
�������ǻ���һ���о�Ŀ�꣬�����������GitLab.com������ʩ�������������ݿ⣩����ι���һ�����õĻָ����ơ�����֤�û�����ר�˸�����ϸ��Ϣ����������ֱ��ָ������ݿ������������Դ��.
����Ϊ���ñ��ݼ�ظ����ܣ����ǿ�ʼ��������DZ��壬�������https://monitor.gitlab.net/dashboard/db/backups��������ǰ���DZ�����������Ƕ�pg_dump���ݵļ�أ��������Ǵ���Ѹ�������ݼӽ�����
�������ǿ��ܻ�ע���Ŀǰ���ǵ�pg_dump���ݵ����ڻ���3��ǰ���������ڱ��÷�������ִ����Щpg_dump���ݵģ����Կ��ܻ�����ݿ���ɺܴ��ѹ������Ϊ����Ŀǰ���������ؽ����ǵı��÷�����������pg_dump�������ڻ�ͣ��һ��ʱ�䡣����Ҳ���ù��ڵ��ģ���Ϊ�������ڰ�LVM���յ�ʱ���ԭ����һ��һ����ߵ�һСʱһ�Ρ�����Azure���̿���Ҳ����������ڿ��ǵ����顣
����������ǻ��о�����θĽ����ǵľٱ�����Ӧϵͳ����ϸ��Ϣ�ɼ�������spam���û��Ƴ���Ӧ��ʹ��Ӳɾ����
��������㻹�й��������ֹ�����¼��ٷ����ĺð취���������������ԡ�
���ñ����а������������������
��ע�����ݿ�������������ݿ������
���������
������С�ǣ���ҵ�������ѧ�����ϵ���Ͽ���ѧ��������˶ʿ��SCJP�� Ŀǰ��һ�ҹ�����Ϣ������ְ������������ʦ����Ҫ������ȤΪJavaƽ̨��ؼ�����ϵͳ���ܡ�C/C++�������ͼ��ѧ�ȡ�����������@��С�ǣ�
�������߷�����������£�лл��






























����˵�������а�