 )
)����
�������������Ź��ںš�EAWorld��������ת���Ѿ�ȡ����Ȩ��
�������߰�
һƪ����Ȥ��˼�������Կ��Զ���չ��˼ά��AI/MLR��Ӧ���ʺ�Ŀ�������ȷ�������������������������ϵͳ��ά���棬��������ʱ���Ľ�����������Խ�������Ķ��壬Ӧ��AI������ʱ������������졣
����д��ǰ��
�����һ������˿��Դ������������� Review�����Զ���������ǰ������������ع��ܵ�Ӱ�죬�Ե�����ɵ�Ӱ�죬�����������ɱ���Ӱ�졣����ָ������Ա����Ĵ��룬����ȱ�ݼ��ʣ�������Ƹʱ����ѡ�˵ļ��������Ǽ�����������������ʵ�Ķ���ָ�꣬���Ҹ���ָ����Ժ���֯���еļ���ָ������ֺϣ���Ԥ�����ļ�����Ŷ���������Ӱ�죬�Ӷ�����һ���������Ƿ���ʡ���һ�лᵽ����
Ϊʲô��������ʼ�������������������Թ�ҵ����˵���������������еľ�̬���ݣ����뱾�������ԣ�����̬���ݣ��������̣��������Դ�ά�ȸ��ӡ�����Դ�������������Ԥ��ѧ�Ѿ��о���ʮ���꣬�Ծ�û�����á�
Ȼ�� AlphaGo �Ѿ�����˰���Ⱥ�۵Ŀ½࣬ƻ��Ҳ�� WWDC2017 �Ϲ���������֧�ֻ���ѧϰ��Ӧ�á���һ�ж��������̵ķ�չ����ʲô���Ļ���Ӱ�죿AIDevOps(���ܻ� DevOps) �����ǻ��ж�Զ��
����AIDevOps�������
�����������Ͽ���һ�������������� DevOps��
DevOps is software eats infrastructure
Ҳ����˵ DevOps �������������������ʩ������������ν�� Infrastructure as Code ��ȷһЩ��������ֹ�ڴ��뱾����Ŀǰ DevOps �Ƚ����е�����������Գ���Ŀ�����ϵ������ά��ϵ����������ά�Ĺ���ǰ�Ƶ������Σ������̸Ľ��ķ����ÿ�������άͳһ��������ά�Ϳ������ܽ�Ϊ����Ŀ������ߣ��淶����Ʒ������淶�Ŀ������̡�
�ҳ����룬Ϊʲô��������ά��ģʽ��ָ��˼�����Ͽ��������أ�

���˲������⣬��ά�Ĵ����������ڼ�ػ�����ʩ�����쳣��������¼��澯�����Ҳ�ȡ��Ԥ�ж���֤���������ȶ����������ɿ�����ά������������Դ�ǻ�����������������ӹ�����������������������˲��������ݾ����ԣ����Ӻܶࡣ�������ݵĽǶȿ�����ά�������Ӹ��ԣ����������Ƚ����ԡ�Ŀǰ���ÿ����ķ���ͳһ��ά���Եü����ҿɲ����ˡ����ǣ�DevOps ͳһ�Ĺ����в�֪�����γ���һ����ı仯��������ʲô�أ�
����
����Ŀǰ�Ѿ��в�����֯��ʼ����ά���������˹����ܵķ���ʹ��ͳ��ά������ܻ���Ŀǰ DevOps ��������ά�������ϵ���������ʣ�µĹ����������ܻ���ά�ķ�ʽ��������Ҳ����Ϊʲô����Ϊ�����ά�Ĺ�ģҪ�����ܶ��ԭ��

�������������̷�չ���������ǿ��Եó��������ƣ�����ɢ�����ϣ����Զ��������ܻ����ⱳ��Ķ�����ǣ�DevOps �ı��������������������������γɡ���������������һֱ����ά�ó��ġ�
������������������֮��Ϊ��ͳ��ά��ʶ��������¼��澯�ж��������������������ڽ�����ƽ�˵�·��Ҳ����˵���ֶ�����ʶ�Ǵ���ά�����������ġ��ڶ�����ʶ�����µ����ܻ���ά AIDevOps ����������ģʽ��
����
����������������������ڵIJ�ͬ��Ϊ���ж����㶨�壬���Ҷ��������Ķ���ָ�꣬�����������������ݽ��ж�����
���������������ݽ����ռ����ܣ���Բ�ͬҵ��Ŀ��ȷ��Ԥ��ģ�ͣ����߶�ԭ��ģ�ͽ��е�����
ѧϰ�������ݽ��н�ģ��ͨ���Բ�ͬģ��Ч�ܵ�������ȷ������ģ�͡�
Ԥ����ͨ�����ݶ�ҵ��Ŀ�����Ԥ�⡣
ָ�������Ԥ�����Ͷ���Ŀ��ĶԱȣ���ʵ���߽������ʵ��ָ����
�ж�������ָ���ж�����Ϊ��һ�εĶ����������ݡ�
����������£�����ֻ��Ҫ����������ж����ڣ����������ڶ������ɻ����Զ�����ɡ����Ҷ�������ֻ��ϵͳ��ʼ����ʱ���趨������ҵ��Ŀ�������һ���Dz�����г����ı�ġ�ָ�������Ǻ��б�Ҫ�ģ������ڶ���Ŀ���Ѿ��ﵽ������¡����������������н������������������ͣ����̲����ͣ�Խ��Խ���ͣ��Լ�Խ��Խ���͡����Ե�Ŀ��ﵽʱ�������Ǽ�����߸��á��ٸ����ӣ�������Ŀ����ʱ�������Ǹ����з���Ա�����ѹ�����ã������ѹ������������������£��Լ�DZ�ڵ����������ࡣ���ԣ�AIDevOps �����ȫ��������������̵����ݣ��ھ�DZ�ڵ�Ӱ�����أ��������Ǹ��õ��������������
˵������Ԥ���о���ʵ������һ���µĻ��⣬��Щ�����д������о�����Χ�����Ԥ������ȱ�ݣ���������ά���ɱ�������չ���������������Ԥ�ⷽ������ģ���ᷢ�ַ������ڿ����ݵ� 2000 �����ң��ɼ�����Ԥ��ķ�չ��ʷ�Ѿ��ܾ��ˣ�����Ϊʲôû��һ�����õ�Ԥ�������أ�����ԭ�������¼��㣺
����������������Ȳ�ͬ��Ԥ��ļ�ֵ��ʱ���ڽ���������
Ԥ���о����õ����ݱȽϵ�һ�����ݿ����Բ�ǿ��
��ͬ��Ŀ����ͬ��Ʒ�Ĺ������̲�ͬ�����ͬһ�����ݻ��в�ͬ�����������ġ�
�����������������ƣ�����ʩ�Ĺ㷺�����Լ���������������������Ӷȣ��������Ӷ�������AIDevOps �ڼ�����ʩ����ҵ�������Ѿ����졣˵����ô�࣬��������������ν��˹��������õ�������������
����AIDevOps �ķ���
��ο�չһ������Ԥ�����о���Ŀǰ�Ĺ�ע����Ҫ�����¼������棺
�о�����ʲô����Ԥ��ģ�͡�
������ʲô���Ķ���ָ�����Ԥ�⡣
��ν�������Ԥ������
�������ģ�͵�Ԥ������
����ģ��
Ԥ�������Ҫ�����������㷨��ϵ��ͳ�Ʒ���������ѧϰ�ķ�����
ͳ�Ƶķ�����������������Ϊά���ҳ����ݼ�����һά�������ݷֲ��������ʵͳ�Ƶķ����Ѿ��ܳ����ˣ�������ʱ��ĽǶ�ȥ��ȱ����α仯��ȼ��ͼ����ʱ���ڱ仯���糤ʱ��ο�������ָ�����塣�������Ƶ�����ֻ��ijЩά���±Ƚ������塣���ά�ȹ��࣬���Ҷ����ķ�Χ�����û�������ˣ���Ϊ���������������Ƶġ�
Ŀǰ�о��Ĵ����ţ�����ѧϰ������Χ������λ��ھ���ķ����������ر�Ҷ˹�����ع飬�������ȣ���Ƴ��Լ���Ԥ���㷨��һ����˵���û���ѧϰ�ķ�������Ԥ�����·�������ģ�
ѡ������ָ�꣨��������
���������⣬��Ŀ�������ߣ����Թ��ߵ�ϵͳ�г�ȡ����ֵ��
�Զ���ֵ����Ԥ������
ʹ�����ݶ����ɸ�ģ�ͽ���ѵ��������ѡ��һ�����ŵ�ģ�͡�
������ʽԤ�⡣
����
AlphaGo �����ѧϰ������������ʵ���ѧϰҲ�ǻ���ѧϰ��һ��������ô���ѧϰ��֮֮ǰ�����ع飬���߲������ر�Ҷ˹�㷨��ʲô�ŵ��أ������ع�Ϊ������������ͬ���������ϲ������µ������������籴Ҷ˹Ҳ���������Լ��裬������� X Y Z ��Ϊ��ģ�Ķ���ָ�꣬���DZ����ز��У����������ʱ����������������Ա��ģ�ͽ����й����𣿵�Ȼ�й��������������������Ԥ����Զ�����Թ�ϵ����������ع�ͷ����������ر�Ҷ˹�����ͺ��Ѳ����õ�Ԥ������ʹ���߱���dz�С�ĵ���ѡ�����㡣�����ѧϰ�Ϳ��Խ��������Щ���ֵ����⡣
������������ôѡ��
�������ѡ����һ�������Ե����⡣�о�֤����û��һ����Ѷ�������Է�֮�ĺ���Ҳ����˵���ڲ�ͬ��Ԥ�������ģ�Ԥ��Ŀ�꣩����Ҫѡ��ͬ�Ķ����㣬����˵ȱ��Ԥ��Ķ����������ά���ɱ�Ԥ��Ķ�����Ͳ�һ�������������·��ʽ��Ŀǰ���еĶ�������з��ࡣ
����
����һ����Ҫ���ĵ�������ǣ���������������Ϊ���أ�һ���������صĶ�����Խ��ϸ����ô�������Ⲷ��ȷ��Խ�ߡ�������������������ǣ���������������ߣ�������Ԥ�����ô�죿��һƪ��How Many Software Metrics Should be Selected for Defect Prediction?��������������Ҫ���������㡣
�����������Ԥ����
һ����ԣ���õ�����һ����Ϊ���飺
��һ�飬ѵ�����ݼ�������ѵ���ͽ���ģ�ͣ�
�ڶ��飬��֤���ݼ������Ѿ�������ģ���϶Բ�ͬģ�ͣ����������ڲ�ͬ�����½��в��ԣ�ѡ���ʺϵ�ģ�͡�
�ڿ�ʼ���н�ģ֮ǰ����������ݼ�����һ����������ϴ���ܶ��㷨�������������ȽϿ��̡��Ƚ�����������о������ǣ�������ĺ�û������ĸ�ռһ�룬����ģ�Ͳ��г����������ѧϰ�����˵һ��ģ���ȱ������ 0.3%�������ͻ����һ�����ݲ�ƽ������⣨Data imbalance�����Լ�������������������ԣ����յ�ģ��Ҳ���������ϵ����⣬��Ҳ�����ģ�͵IJ�ȷ�����һ������һЩ����������ݽ�����ϴ������ѡ��Feature Selection��������Normalization��������������Noise Handling����
������������㷨��Ч�ԣ�
��������ɸ���ѡģ�ͣ����߱�ѡ�����㣬������۸ò�����һ�����ף��أ����㷨�����۷����ϣ�ѧ�绹���й�ʶ�ġ��������ռ�һ���⼸��ָ�꣺
����
������ļ�������ָ�������������磬���ܶȣ�Precision, TP/(TP+FP)������ȫ�ʣ�Recall, TP/(TP+FN)�����Լ����ߵ��ۺ� F ��������ֵԽ��֤���㷨����Ԥ�������о������ֱȽ��ȶ�����ϸ�ĸ���������ﲻ�����ˡ�
����ѧ������о���ʾ
��һƪ�Ƚ�����������ġ�Researcher Bias: The Use of Machine Learning Software Defect Prediction�������� 2012 ����ǰ���ֵĻ���ѧϰ������Ԥ��ѧ���Ľ������о������ԡ������������ݼ��������㡢�о����塱�ĸ�ά�Ƚ����˻��ܷ�����Meta-analysis�������µĽ��ۻ��DZȽ��ģ��������ˡ�Striking������ʶ����Ľ������ܽ
�ܶ��������û�кܺõļ������ã���������֮ǰ�IJ��Ҳ�������ԣ���Ϊ����һЩδ֪�����ض�ģ��Ч�������˱Ƚϴ��Ӱ�졣
��֮������ģ�ͣ���ͬ�о�����֮����о��ɹ�������ԡ�Ҳ����˵�㷨������Ҫ��˭�����о�����Ҫ��
��ΪԤ����·�������Ѿ����ڵ����ݼ�֮�Ͻ�ģ����������֪�����ݽ��в��ԣ�����֪����������㷨��ģ�ͱ�ÿ��ã����������о�С�����Ƿ����Լ����㷨������㷨�ĸ��Ӷ�Խ��Խ�ߣ���һ�����ݼ�����ģ�;�û����ֲ�ԡ�
�о��ɹ���û������ʱ������Ƹ��ӳ������أ���û�У���Ϊ���ϵ�ԭ���о��ij����ԱȽϲҲ����˵������������֮ǰ���ĵĻ����Ͽ�չ��������Ĺ�����
�ѵ� AIDevOps ��ʵ�����𣿽�Щ���о����ڿɻ�ȡ�������������ݹ�ȣ������о������϶��������Եı仯���硰Deep Learning for Just-In-Time Defect Prediction������Automatically Learning Semantic Features for Defect Prediction������ƪ�Ѿ���ʼ�����ѧϰ�ķ��������и���ʱЧ�Ե�ȱ��Ԥ�⡣֮ǰҲ�������ѧϰģ�͵��ص㣬������ƪ�����ж������������������ DBN Ϊģ�ͽ���Ԥ�⣬DBN �ɶ�㲣�������� RBN ��ɡ����֮ǰֱ���ö����������Ϊ������н�ģ�ķ�ʽ��DBN ���÷��������н���ж�֮ǰ�������ɲ� RBN �����ݽ��д������Ӷ��ó�����ֵ�����ø�ֵ�����ж�������ֵ�ͽ��ֵ�����������Թ�ϵ����� DBN �ȼķ������������ӿ��š��������ġ�Automatically Learning Semantic Features for Defect Prediction�������Դ�ͳ�Ķ���ֵΪ���룬���ǶԴ����������н������γ����������������뵽 DBN �н���ģ��ѵ����
���⣬��Щ�����������������С�Լ���Ŀ�����Է����Ѿ�������ν�������ݡ����������о������и��ಢ�Ҹ����������ݿ���ʹ���о���������ɷɽ�����˵�����ݼ����ڸ��˹������о��������������Ҫ�Ľ�ɫ����ҲΪ����Ԥ��ķ�չ�춨�����õĻ�����
�������� AIDevOps ���ж�Զ��
����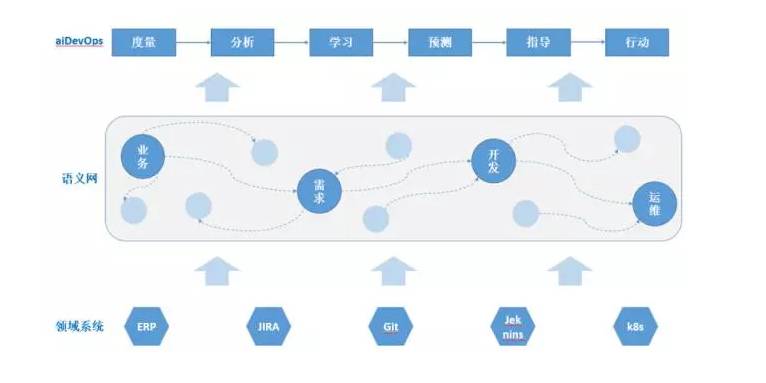
�����������ܹ�������Щ��Ҳ�ڷ�������Ȼ��Ϣ�ı仯���������������˻�����ʩ�������ṹ�����⡣API ����ѧ�����������������ݹ����Լ����ݹ�ϵ�����⡣GitHub ������������صĹ����ƽ���˹������ݿ����Ե����⡣�ǽ�����������һ�����������ʽȥ������Щ���ݣ������������������ˡ���Ȼ�Ѿ������� OSLC �ı�����������̽�����������������ݴ洢����ѯЧ�ʵȸ����������Լֹ����ǰ��������Ӧ�õĽǶȿ����Է��������ʹ�÷�ʽҲ�����������Ļ���ѧϰ�㷨��
������ʵ������ AIDevOps �ľ��벢����ôңԶ�ˣ����������̹����ĸ��Ӷ�Խ��Խ�����ܻ�����������Խ��Խ�ߣ�AIDevOps Ҳ����������һ�ŵ����顣��ˣ�����Ӧ���г�ֵ������ڴ��������������������� AlphaGo һ����о��ɹ���
�������߽���
��˧����Ԫ��Ϣ�������ܹ�ʦ�����������������˶ʿ������ְ�� IBM �й�����ʵ���ң����� Rational Team Concert, Rational Insight �Ȳ�Ʒ�з�����������������Դ BI ��Ʒ BIRT �������ʡ�Ϊ���У����У����У�����ͨ�õȴ�����ҵ�ṩ DevOps �Լ� BI ��Ʒ��ѯʵʩ������ DevOps �Լ� BI ��������˷ḻ���з���ʵʩ���顣
���������
Sarah Beecham��Tracy Hall, David Bowes. A Systematic Review of Fault Prediction approaches used in Software Engineering (2010).
Huanjing Wang, Taghi M. Khoshgoftaar, Naeem Seliya. How Many Software Metrics Should be Selected for Defect Prediction? (2010).
Javier Alonso, Llu´?s Belanche, Dimiter R. Avresky. Predicting Software Anomalies using Machine Learning Techniques (2011).
Martin Shepperd, David Bowes and Tracy Hall, Researcher Bias: The Use of Machine Learning in Software Defect Prediction (2012).
Jaechang Nam , Survey on Software Defect Prediction (2014).
Xinli Yang, David Lo, Xin Xia. Deep Learning for Just-In-Time Defect Prediction (2015).
Song Wang,Taiyue Liu and Lin Tan. Automatically Learning Semantic Features for Defect Prediction (2016).
���ķ����� EAii��Enterprise Architecture Innovation Institute����ҵ�ܹ������о�Ժ���¹ٷ��Ź��ںš�����ת���ѻ��ת����Ȩ��































����˵�������а�