 )
)������Դ | ����֮��

����Python �����������ݿ�ѧ��ҵ��������ǵļ���������������ԴҲ���������ݿ�ѧ���������˾ ActiveWizards ���ո��������Լ���Ӧ�ÿ������飬�ܽ������ݿ�ѧ�Һ���ʦ���� 2017 ���ʹ�õ� Python �⡣
���Ŀ�
����1��NumPy
������ַ��https://www.numpy.org
������ʹ�� Python ��ʼ������ѧ����ʱ�����ɱ������Ҫ���� Python �� SciPy Stack������ר��Ϊ Python �еĿ�ѧ�������Ƶ������ļ��ϣ���Ҫ�� SciPy ��������ֻ����� stack ��һ���֣��Լ�Χ����� stack ������������� stack �൱�Ӵ�������ʮ�����⣬����������۽��ں��İ��ϣ��ر�������Ҫ�ģ���
����NumPy������ Numerical Python���ǹ�����ѧ���� stack ��������İ�����Ϊ Python �е� n ά����;���IJ����ṩ�˴������õĹ��ܡ��ÿ�ṩ�� NumPy �������͵���ѧ�����������������������ܣ��Ӷ��ӿ�ִ���ٶȡ�
����2��SciPy
������ַ��https://www.scipy.org
����SciPy ��һ�����̺Ϳ�ѧ�����⡣�������⣬�㻹Ҫ�˽� SciPy Stack �� SciPy ��֮�������SciPy �������Դ������Ż������ɺ�ͳ�Ƶ�ģ�顣SciPy �����Ҫ���ܽ����� NumPy �Ļ���֮�ϣ���������������ʹ���� NumPy����ͨ�����ض�����ģ���ṩ��Ч����ֵ���̲�����������ֵ���֡��Ż��������������̡�SciPy ��������ģ���еĺ���������ϸ���ĵ�����Ҳ��һ�����ơ�
����3��Pandas
������ַ��https://pandas.pydata.org
����Pandas ��һ�� Python ����ּ��ͨ������ǣ�labeled�����͡���ϵ��relational�������ݽ��й�������ֱ�ۡ�Pandas �� data wrangling ���������ߡ���������ڿ��ټ����ݲ������ۺϺͿ��ӻ���������������Ҫ�����ݽṹ��

Series��һά

Data Frames����ά
�������磬����Ҫ�����������͵Ľṹ�н��յ�һ���µġ�Dataframe�����͵�����ʱ���㽫ͨ������һ����Series������һ�����ӵ���Dataframe���������������� Dataframe��
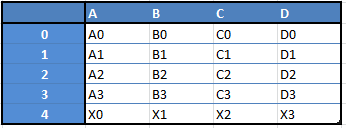
��������ֻ��һС��������� Pandas �������飺
����ɾ�������ӡ�Dataframe���е���
�����ݽṹת��Ϊ��Dataframe������
������ʧ���ݣ���ʾΪ NaN��Not a Number��
����ǿ��ķ���
���ӻ�
����4��Matplotlib
������ַ��https://matplotlib.org
����Matplotlib ����һ�� SciPy Stack ��������������һ�� Python �⣬רΪ�������ɼ�ǿ��Ŀ��ӻ����������ơ�����һ�������������ʹ�� Python���� NumPy��SciPy �� Pandas �İ����£���Ϊ MatLab �� Mathematica �ȿ�ѧ���ߵ������������֡�Ȼ���������Ƚϵײ㣬����ζ������Ҫ��д����Ĵ�����ܴﵽ���Ŀ��ӻ�Ч����ͨ�����ʹ�ø������߸�������Ŭ�������ܵ���˵ֵ��һ�ԡ���һ����������Ϳ��������κο��ӻ���
��ͼ
ɢ��ͼ
����ͼ��ֱ��ͼ
��״ͼ
��ͼ
����ͼ
��ͼ
Ƶ��ͼ
��������ʹ�� Matplotlib ������ǩ������ͼ��������������ʽ��ʵ��Ĺ��ܡ������ϣ�һ�ж��ǿɶ��Ƶġ�
�����ÿ�֧�ֲ�ͬ��ƽ̨������ʹ�ò�ͬ�� GUI ���������������õ��Ŀ��ӻ������ͬ�� IDE���� IPython����֧�� Matplotlib �Ĺ��ܡ�
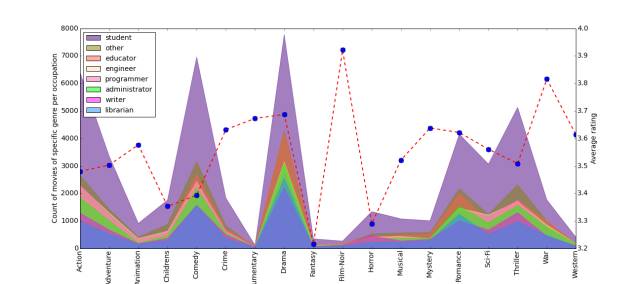
��������һЩ����Ŀ����ʹ���ӻ���ø������ס�
����5��Seaborn
������ַ��https://seaborn.pydata.org
����Seaborn ��Ҫ��עͳ��ģ�͵Ŀ��ӻ������ֿ��ӻ������ȶ�ͼ��heat map���������ܽ����ݵ�Ҳ�������ֲ���Seaborn ���� Matplotlib�����߶�����������
����
����6��Bokeh
������ַ��https://bokeh.pydata.org
����Bokeh Ҳ��һ���ܺõĿ��ӻ��⣬��Ŀ���ǽ���ʽ���ӻ�����֮ǰ�Ŀ��෴������������ Matplotlib�����������Ѿ��ᵽ��������Bokeh ���ص��ǽ����ԣ���ͨ���ִ�����������������ĵ���d3.js���ķ����֡�
����7��Plotly
������ַ��https://plot.ly
�������̸̸ Plotly������һ������ Web �Ĺ����䣬���ڹ������ӻ����� API ���ָ�ijЩ������ԣ����а��� Python������ plot.ly ��վ����һЩǿ��ġ����伴�õ�ͼ�Ρ�Ϊ��ʹ�� Plotly������Ҫ������� API ��Կ��ͼ�δ�������ڷ������ˣ����ڻ������Ϸ�������Ҳ��һ�ַ������Ա�����ô����
����ѧϰ
����8��SciKit-Learn
������ַ��https://scikit-learn.org
����Scikits �� SciPy Stack �ĸ�����������רΪ�ض����ܣ���ͼ������������ѧϰ������ơ��ں��߷��棬������ͻ����һ���� scikit-learn���������������� SciPy ֮�ϣ�������ʹ������ѧ������
����scikit-learn ��һ������һ�µĽӿڣ������ó����Ļ���ѧϰ�㷨�������ǿ��Լ���������Ӧ�û���ѧϰ���ÿ����������ܺõĴ�������õ��ĵ�������ʹ�������ŷdz��ߵ����ܣ���ʹ�� Python ���л���ѧϰ��ʵ���ϵ���ҵ����
���ѧϰ��Keras / TensorFlow / Theano
���������ѧϰ���棬Python ����ͻ�������Ŀ�֮һ�� Keras���������� TensorFlow ���� Theano ֮�����С�����������һ�����ǵ�һЩϸ�ڡ�
����9��Theano
������ַ��https://github.com/Theano
�������ȣ�������̸̸ Theano��Theano ��һ�� Python �������������� NumPy ���ƵĶ�ά���飬�Լ���ѧ����ͱ���ʽ���ÿ��Ǿ�������ģ�ʹ�������мܹ����ܹ���Ч���С���������������������ѧ����ѧϰ�鿪������Ҫ��Ϊ���������ѧϰ������
����Ҫע����ǣ�Theano �� NumPy �ڵײ�IJ����Ͻ��ܼ��ɡ��ÿ�Ż��� GPU �� CPU ��ʹ�ã�ʹ�����ܼ��ͼ�������ܸ��졣
����Ч�ʺ��ȶ��Ե�����������ȷ�Ľ������ʹ�Ƿdz�С��ֵҲ���ԣ����磬��ʹ x ��С��log(1+x) Ҳ�ܵõ��ܺõĽ����
����10��TensorFlow
������ַ��https://www.tensorflow.org
����TensorFlow ���� Google �Ŀ�����Ա����������������ͼ����Ŀ�Դ�⣬ר��Ϊ����ѧϰ��ơ�����Ϊ���� Google ��ѵ��������ĸ�Ҫ�����Ƶģ��ǻ���������Ļ���ѧϰϵͳ DistBelief �ļ����ߡ�Ȼ����TensorFlow �����ǹȸ�Ŀ�ѧר�õġ�����Ҳ����֧��������ʵ�����Ӧ�á�
����TensorFlow �Ĺؼ�����������ڵ�ϵͳ�������ڴ������ݼ��Ͽ���ѵ���˹������硣��Ϊ Google ������ʶ���ͼ��ʶ���ṩ��֧�֡�
����11��Keras
������ַ��https://keras.io
����������������� Keras������һ��ʹ�ø߲�ӿڹ���������Ŀ�Դ�⣬������ Python ��д�ġ������������и�����չ�ԡ���ʹ�� Theano �� TensorFlow ��Ϊ��ˣ��� Microsoft �����ѽ� CNTK��Microsoft ����֪���߰�������Ϊ�µĺ�ˡ�
�������Լ�����ּ��ͨ������������ϵͳ���п��ٺ�����ʵ�顣
����Keras �����������֣����ҿ��Խ��п��ٵ�ԭ����ơ�����ȫʹ�� Python ��д�ģ����Ա����Ϻܸ߲㡣���Ǹ߶�ģ�黯�Ϳ���չ�ġ�������������������߲㣬�� Keras Ҳ�dz���Ⱥ�ǿ��������������Ľ�ģ��
����Keras ��һ��˼���ǻ���������IJ㣬Ȼ��Χ�Ʋ㹹��һ�С���������������ʽ����������һ�㸺���������������һ�����������ģ����������֮�䡣
��Ȼ���Դ���
����12��NLTK
������ַ��https://www.nltk.org
��������������� Natural Language Toolkit����Ȼ���Թ��߰���������˼�壬�������ڷ��ź�ͳ����Ȼ���Դ����ij�������NLTK ּ�ڴٽ� NLP �������������ѧ����֪��ѧ���˹����ܵȣ��Ľ�ѧ���о���Ŀǰ�����ص��ע��
����NLTK ������������������ı���ǡ������ tokenizing������ʵ��ʶ�𡢽��������Ͽ�������ʾ���Ӽ�;����ڵ������ԣ����ʸ���ȡ���������������еĹ����鶼����Ϊ��ͬ���������ӵ��о�ϵͳ�����������������Զ�ժҪ��
����13��Gensim
������ַ��https://radimrehurek.com/gensim
��������һ������ Python �Ŀ�Դ�⣬ʵ�������������ռ佨ģ�����⽨ģ�Ĺ��ߡ������Ϊ���ı���������Ч����ƣ������������Դ����ڴ������ݡ���ͨ���㷺ʹ�� NumPy ���ݽṹ�� SciPy ������ʵ����Ч�ʡ����ȸ�Ч������ʹ�á�
����Gensim ��Ŀ���ǿ���Ӧ��ԭʼ�ĺͷǽṹ���������ı���Gensim ʵ��������ֲ� Dirichlet ���̣�HDP����DZ�����������LSA����DZ�� Dirichlet ���䣨LDA�����㷨������ tf-idf�����ͶӰ��word2vec �� document2vec���Ա��ڼ��һ���ĵ���ͨ����Ϊ���Ͽ⣩���ı����ظ�ģʽ��������Щ�㷨���ල�ġ�������Ҫ�κβ�����Ψһ�����������Ͽ⡣
�����ھ���ͳ��
����14��Scrapy
������ַ��https://scrapy.org
����Scrapy �����ڴ���������ṹ�����ݣ�����ϵ����Ϣ�� URL�����������Ҳ��Ϊ spider bots���Ŀ⡣���ǿ�Դ�ģ��� Python ��д���������Ϊ scraping ��Ƶģ�������������ʾ�����������������Ѿ���չ����һ�������Ŀ�ܣ����Դ� API �ռ����ݣ�Ҳ��������ͨ�õ����档
�����ÿ��ڽӿ��������ѭ������ Don��t Repeat Yourself ԭ�������û���дͨ�õĿɸ��õĴ��룬��˿���������������չ�������档
����Scrapy �ļܹ�Χ�� Spider ��������������һ����������ѭ��ָ�
����15��Statsmodels
������ַ��https://www.statsmodels.org
����statsmodels ��һ������ Python �Ŀ⣬��������ܴ������в³��������������û��ܹ�ͨ��ʹ�ø���ͳ��ģ���Ʒ����Լ�ִ��ͳ�ƶ��Ժͷ�������������̽����
�����������õ������������Եģ�����ͨ��ʹ�����Իع�ģ�͡���������ģ�͡���ɢѡ��ģ�͡��Ƚ�������ģ�͡�ʱ�����ģ�͡����ֹ���������ͳ�ơ�
�����ÿ�ṩ�˹㷺�Ļ�ͼ������ר������ͳ�Ʒ����͵���ʹ�ô�����ͳ�����ݵ��������ܡ�
����
��������б��еĿⱻ�ܶ����ݿ�ѧ�Һ���ʦ��Ϊ������ģ��˽����Ϥ�����Ǻ��м�ֵ�ġ���������Щ���� GitHub �ϻ����ϸͳ�ƣ�

������Ȼ���Ⲣ����һ����ȫ�꾡���б������������ܶ�ֵ�ù�ע�Ŀ⡢���߰��Ϳ�ܡ�����˵�����ض������ SciKit �������а�������ͼ��� SciKit-Image�������Ҳ�к��뷨�����������Ƿ�����































����˵�������а�