新智元编译
来源: Science
编译:刘小芹
新智元启动 2017 最新一轮大招聘:COO、总编、主笔、运营总监、视觉总监等8大职位全面开放。
新智元为COO和执行总编提供最高超百万的年薪激励;为骨干员工提供最完整的培训体系、高于业界平均水平的工资和奖金。加盟新智元,与人工智能业界领袖携手改变世界。
简历投递:jobs@aiera.com.cn HR 微信:13552313024
【新智元导读】AlphaGo之后,又一人机大战被登上了Science 封面,这一次是德州扑克AI 程序DeepStack。来自加拿大和捷克的几位计算机科学研究者提出一种新算法 DeepStack,在一对一无限注德州扑克中打败了人类对手。这是AI 在不完美信息博弈中堪称里程碑式的突破。
计算机在象棋和围棋游戏中已经能击败人类。这些以及其他类似的游戏,对于当下的游戏状态,所有的玩家能够获得的确定性信息是相同的。但是,在扑克游戏中,由于无法看到对手的牌,教计算机玩好扑克是很棘手的。来自加拿大和捷克的几位计算机科学研究者提出一种新算法 DeepStack,在一对一无限注德州扑克中打败了人类对手。DeepStack 不是事先制定策略,而是考虑当前的游戏状态,在每一步重新计算策略。DeepStack 背后的原理有助于解决现实世界中涉及信息不对称的问题。

这项研究登上 Science 最新一期封面。

摘要
近年来,人工智能领域取得了很多突破,其中游戏方面取得的突破常常是里程碑式的。这些游戏的共同特征是所有玩家都能得到完美信息(perfect information)。扑克是典型的不完美信息(imperfect information)博弈,是人工智能领域长期的一个挑战性问题。在这篇论文中,我们介绍了 DeepStack,这是一种用于不完美信息环境的算法。它结合使用递归推理( recursive reasoning)来处理信息不对称,利用分解(decomposition)将计算集中在相关的决策上,以及一种有关扑克的任意状态的直觉形式,该直觉可以利用深度学习从单人玩牌过程中自动学习到。在一项有数十名参赛者进行的44000手扑克的比赛中,DeepStack 以显著差异在一对一无限注德州扑克中击败职业扑克玩家。这种方法在理论上是可靠的,而且已经证明它产生的策略比以前的方法的策略更难被利用。
引言:不完美信息博弈
游戏长久以来都被认为是用来测量人工智能进步的一个基准。在过去的20年间,我们见证了许多游戏程序在许多游戏上超越了人类,比如西洋双陆棋、跳棋、国际象棋、Jeopardy 、Atari 电子游戏和围棋。计算机程序在这些方面的成功涉及的都是信息的对称性,也就是对于当下的游戏状态,所有的玩家能够获得的确定性信息是相同的。这种完美信息的属性也是让这些程序取得成功的算法的核心,比如,在游戏中进行局部搜索。
现代博弈理论创建者、计算机先锋冯·诺依曼(von Neumann)曾对无完美信息的博弈中的推理行为进行过解释:“现实世界与此不同。现实世界有很多假象、骗术,需要你去思考别人对你的策略到底看穿了多少。这就是我提出的理论所涉及的博弈。”冯·诺依曼最痴迷的一个游戏是扑克,在扑克游戏中,玩家在得到自己的牌后,需要轮流下注,让对手跟注,他们或跟注或弃牌。扑克是一种不完美信息博弈,玩家只能根据自己手上的牌提供的非对称的信息来对游戏状态进行评估。
在一对一对战(也就是只有两位玩家)的有限下注德州扑克中,AI 曾经取得了一些成功。但是,一对一有限注的德州扑克,全部的决策点(decision points)只有不到10的14次方个。作为对比,计算机已经在围棋上完胜人类专业棋手,围棋是一个完美信息的游戏,约包含有10的170次方个决策点。
不完美信息博弈要求更复杂的推理能力。在特定时刻的正确决策依赖于对手所透露出来的个人信息的概率分布,这通常会在他们的行动中表现出来。但是, 对手的行为如何暗示他的信息,反过来也要取决于他对我们的私人信息有多少了解,我们的行为已经透露了多少信息。这种循环性的推理正是为什么一个人很难孤立地推理出游戏的状态的原因,不过在完美信息博弈中,这是局部搜索方法的核心。
在不完美信息博弈中,比较有竞争力的 AI 方法通常是对整个游戏进行推理,然后得出一个完整的优先策略。CFR ( Counterfactual regret minimization)是其中一种战术,使用自我博弈来进行循环推理,也就是在多次成功的循环中,通过采用自己的策略来对抗自己。如果游戏过大,难以直接解决,常见的方法是先解决更小的、浓缩型的游戏。最后,如果要玩最初的大型的游戏,需要把原始版本的游戏中设计的模拟和行为进行转移,到一个更“浓缩”的游戏中完成。
虽然这一方法让计算机在一对一无限注德州扑克(Heads-up no-limit Texas Hold'em,HUNL)一类的游戏中进行推理变得可行,但是,它是通过把HUNL下的10的160次方个场景压缩到10的14次方个缩略场景来实现的。这种方法有很大的可能性会丢失信息,所有这类的程序离专业的人类玩家水平还差得很远。
2015年,计算机程序 Claudico 输给了一个专业扑克玩家团队,并且是以较大的劣势输掉的比赛。此外,最近,在年度计算机扑克竞赛中,人们发现,基于“浓缩”的计算机程序有很多缺点。其中4个使用了这一方法的计算机程序,其中包括从2016年来一直位列前茅的程序,被认为使用了一个局部最佳响应的技巧,使得在一个策略能输掉多少这一决策上,产生一个更加接近下限的答案。所有这四个基于“浓缩”方法的程序都可能会输得很惨,用量化来表示,是每局都弃牌输率的四倍。
DeepStack 采用了一个完全不同的方法。它持续地使用CFR中的循环推理来处理信息不对称的问题。但是,它并不会计算和存储一个完整的优先策略用于博弈,所以也不需要进行简要的提炼(浓缩)。反之,在游戏中,它会在每一个具体的场景出现时就进行考虑, 但是并不是独立的。
通过使用一个快速的近似估计来代替某一种深度的计算,它能避免对整个游戏的剩余部分进行推理。这种估计可以被看成是 DeepStack 的直觉:在任何可能的扑克情境下,持有任何可能的个人牌的牌面大小的直觉。
最后,从某种程度上来说与人类的很像的 DeepStack 的直觉,是需要被训练的。我们使用了随机生成的扑克情景用深度学习进行训练。最终,我们证明了,DeepStack从理论上来说是可行的,比起基于“浓缩”的方法,它能产生从实质上需要更少的探索的策略,同时,它也是世界上首个在HUNL游戏中击败人类专业玩家的计算机程序,平均赢率超过450 mbb/g。(mbb/g,milli-big-blinds per game ,是用于衡量扑克玩家表现的指数,50 mbb/g 可以就认为是一个较大的优势,750mbb/g 就是对手每局都弃牌的赢率。)
DeepStack 算法:让机器拥有“直觉”
DeepStack 是一大类的序列不完美信息博弈的通用算法。我们将解释 DeepStack 在 HUNL(heads-up no-limit,一对一无限注)德州扑克中的作用。扑克游戏的状态可以分为玩家的私人信息,即两张牌面朝下的手牌,以及公共状态,包括牌面朝上的公共牌和玩家的下注顺序。游戏中公共状态的可能序列形成公共树,每个公共状态有一个相关联的子公共树。见下图:

图1:HUNL公共树的一部分。红色和湖蓝色代表玩家的动作。绿色代表被翻开的公共牌。
DeepStack 算法试图计算玩游戏的低利用率策略,即,求解一个近似的纳什均衡(Nash equilibrium)。DeepStack在玩牌期间计算这个策略,公共树的状态如图2所示。这种本地的计算使得 DeepStack 在对现有算法来说规模太大的游戏中可推理,因为需要抽象出的游戏的10的160次方决策点下降到10的14次方,这让算法变得易处理。
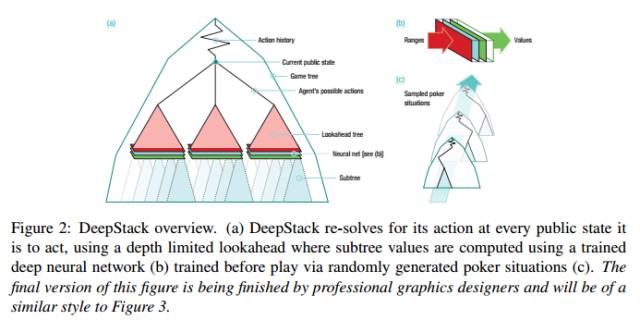
图2:DeepStack 概览图。(a)DeepStack 对在每个公共状态的动作进行 re-solves,使用 depth-limited lookahead,其中子树值的计算用训练好的深度神经网络(b)通过随机生成的扑克状态在玩牌前进行训练(c)最终状态如图3。
DeepStack 算法由三个部分组成:针对当前公共状态的本地策略计算(local strategy computation),使用任意扑克状态的学习价值函数的 depth-limited lookahead,以及预测动作的受限集合。
连续 Re-Solving
Own Action:将对手的反事实值替换为在为我们自己选择动作的解决策略中计算的值。使用计算策略和贝叶斯规则更新我们自己的动作范围。
Chance Action:用从最后一次分解为这个动作计算出的反事实值替换对手反事实值。通过清除在任何新公共牌不可能的手牌范围,更新我们自己的范围。
Opponent Action:不用做什么。
Limited Lookahead 和 Sparse Trees
连续re-solving在理论上是可行的,但实际使用上不现实。它没有维持一个完整的策略,除非游戏接近结束,re-solving本身就很棘手。例如,对于第一次动作的re-solving需要为整个游戏临时计算近似解决方案。
Deep Counterfactual Value Networks
深度神经网络(DNN)已被证明在图像和语音识别、自动生成音乐以及玩游戏等任务上是强有力的模型。DeepStack 使用DNN和定制的架构作为它的 depth-limited lookahead其的价值函数。如图3。
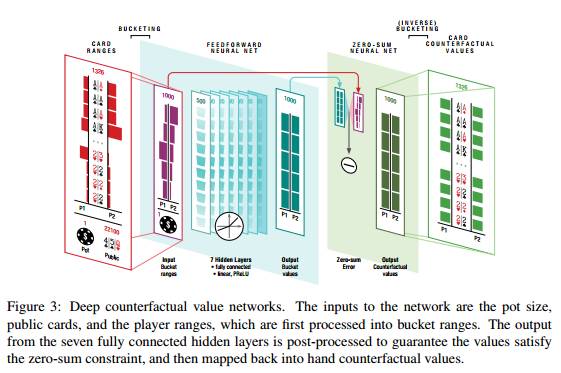
图3:Deep Counterfactual Value Networks。网络的输入是pot的大小,公共牌和玩家范围,玩家范围先被处理为bucket ranges。输出来自七个完全连接的隐藏层,被后处理以保证值满足零和限制(zero-sum constraint)。
训练两个独立的网络:一个在第一次三张公共牌被处理(flop网络)后估计反事实值,另一个在处理第四张公共牌(turn网络)后估计反事实值。一个辅助网络用于在发任意公共牌之前加速对前面的动作的re-solving。
DeepStack 表现
图4总结了用 AIVAT 衡量的每个参赛者的表现。在完成所要求的 3000手牌的玩家中,DeepStack 预估赢率是 394 mbb/g,与11名玩家对战赢了其中10名,差距显著。人类玩家中表现最好者估计赢率是 70 mbb/g,这个结果没有显著的统计学意义。
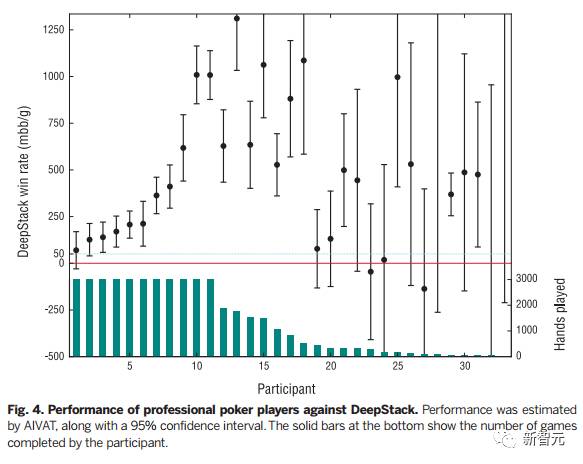
图4:人类专业扑克玩家和DeepStack的表现。用 AIVAT衡量,置信区间是95%。下方的柱形图表示参与者完成的手数。
DeepStack 在 HUNL 中以显著差异击败人类职业扑克玩家;HUNL 的计算规模与围棋相似,但不完美信息的性质增加了其复杂性。DeepStack 没有用专业人士的游戏经验来训练,只利用很少的领域知识实现了打败人类的目标。它的影响不仅仅是人工智能领域取得突破。DeepStack 代表了大规模、连续的不完美信息博弈近似解决方案的范式发生了改变。在过去20年中,对完全策略(complete strategies)进行抽象(abstraction)和离线计算(offline computation)是这类问题的主要方法。DeepStack 允许计算集中于进行决策时出现的特定情况,使用自动训练的值函数(value functions)。这些是在完美信息博弈中取得成功的两个核心原则,尽管在这些设置中从概念上来说更简单就能实现。因此,完美信息博弈和不完美信息博弈之间的差距已经消除。
由于包含信息不对称的许多现实世界的问题,DeepStack 也对不符合完美信息假设的环境有影响。处理不完美信息的 abstraction 范式可以用于保护战略资源以及在医疗中进行稳健的决策。DeepStack 的连续 re-solving 范式将能够开辟更多的可能性。
新智元招聘
职位:客户经理
职位年薪:12 - 25万(工资+奖金)
工作地点:北京-海淀区
所属部门:客户部
汇报对象:客户总监
工作年限:3 年
语 言:英语 + 普通话
学历要求:全日制统招本科
职位描述:
精准把握客户需求和公司品牌定位,策划撰写合作方案;
思维活跃、富有创意,文字驾驭能力强,熟练使用PPT,具有良好的视觉欣赏及表现能力,PS 能力优秀者最佳;
热情开朗,擅长人际交往,良好的沟通和协作能力,具有团队精神;
优秀的活动筹备与执行能力,较强的抗压能力和应变能力,适应高强度工作;
有4A、公关公司工作经历优先;
对高科技尤其是人工智能领域有强烈兴趣者加分。
岗位职责:
参与、管理、跟进上级指派的项目进展,确保计划落实。制定、参与或协助上层执行相关的政策和制度。定期向公司提供准确的市场资讯及所属客户信息,分析客户需求,维护与指定公司关键顾客的关系,积极寻求机会发展新的业务。建立并管理客户数据库,跟踪分析相关信息。
应聘邮箱:jobs@aiera.com.cn
HR微信:13552313024
新智元欢迎有志之士前来面试,更多招聘岗位请点击【新智元招聘】查看。