科学的目的是尽可能准确地建立事实。因此,分辨观察到的现象是否是真实的、还是纯属巧合的结果至关重要。如果你以为你发现了一些事实,而它其实只是随机的,这会被称为虚假的发现或假阳性。尤其是在医学的某些领域,假阳性这种情况是非常常见的。
△ 假阳性;许多微观的癌和非癌的人体组织样本。(图片来源:Wellcome Images)
7月22日,一篇发表在PsyArXiv的文章引发了一场激烈的大辩论。辩论的问题很简单,而且还正中所有科学研究的核心,即:什么样的结果才能算是可靠的?
这个问题非常重要,因为许多学科目前都面临着“可重复性危机”,即使是教科书里的内容,也未必能通过严格的重新测试。
此次辩论的中心是“统计显著性”这个概念,它是决定研究结果是否能发表在科学期刊中最有影响力的度量标准之一。若一个结果要能被算得上是“统计上显著的”,它需要通过一项简单的测试。测试的答案被称为“P值”。如果P值小于0.05——恭喜你!通过测试,你拥有了一个统计显着的研究结果。
但不久前,来自统计学、心理学、经济学、社会学、政治学、还有生物医学等学科的72名卓越的学者想要改变这种现状。他们在一篇即将刊登在《自然人类行为》杂志上的文章中表示,研究结果必须通过更高的门槛,才能被视为具有“统计显著性”。

△ 这篇题为《重新定义统计显著性》的文章即将发表在《自然:人类行为》杂志。合作者包括了两位研究可重复性的重量级人物:John Ioannidis和Brian Nosek.(图片来源:D.J.Benjamin)
作者写道:“我们建议将P值改为小于0.005,这个简单的步骤将即刻提高科学研究在许多领域的重复性。” 如果这一改变被接受,它就有可能大大减少科学文献中的假阳性。
斯坦福大学健康研究教授 John Ioannidis 是这篇文章的作者之一,他说:“我们使用P值的方式存在很大的问题,这导致了现在学术论文中出现了大量误导性的主张。” 同时 Ioannidis 也表示,这个建议并不能解决科学中的所有问题,他说:“我认为这就像是一个大坝,在我们找到永久性修复的方法前,它能帮我们遏制洪水。”
但并不是每个人都认同这种做法。
它能导致的最好结果是,通过这个简单的改变,学术文献中的错误得以显著减少。而最坏的结果,这种居高临下的命令,可能让科学中一些真正的问题丧失表达机会。
这也正是这场辩论的主要焦点。
什么是P值?
当研究人员计算一个P值时,他们测试的是“零假设”。要知道的是:这不是一个关于实验者最迫切想要回答的问题的测试。
什么是零假设呢?举个简单粗暴的例子,假设实验者想要知道每天吃一个巧克力棒是否能减肥,于是分配了50个参与者每天吃一个巧克力棒,安排另50人不许吃巧克力棒。在实验前和试验后分别测量两组参与者的体重,之后再比较两组的平均体重。
这时,零假设会倡导的论证则是:吃巧克力与不吃巧克力的参与者的体重减轻没有差别(即假设了要被试验的效应并不存在)。因此,驳回零假设是科学家在证明自己理论过程中的主要障碍。科学家会通过统计学来排除一些零假设。最基础的,他们会问自己:基于现有的结果,相信零假设是正确的这件事会有多荒谬呢?
驳回零假设与法庭上证明一个人有罪的原则有些类似。比如说,在法庭上,你先假定被告是无辜的,接着你看到证据,如:带血的刀子上有他的指纹,他有暴力倾向的记录,还有目击证人作证等等。根据这些证据,无罪定论开始显得幼稚。到了某一程度上,法官会感觉得到,这已超出了合理怀疑,被告并不是无辜的。
零假设检验遵循类似的逻辑:如果吃巧克力的人和不吃的人之间的体重差异不同,那么“没有重量差异”的零假设则看起来很愚蠢。就可以被驳回。
你可能会想:这种证明一个实验的方式岂不是很迂回?是的,就是很迂回!被驳回的零假设是实验的一个间接证据。它并不能说明你的科学结论是否正确。
就接着上面的例子来说,比如被驳回的零假设并不能告诉提供你任何关于巧克力引起减肥的机制。它也不能告诉你实验是否设计良好、控制得当,或者结果是否被择优挑选过等等。它只是帮你了解结果的罕见程度。
而P值量化了这个稀有度。它告诉你的是,在假设这个零假设是真的的前提下,在重复实验中,你能得到相同结果的次数是多少。如果P值非常小,也就是说得到相同结果的次数很少,则证明零假设的可能性很小,这意味着实验结果的数据是由随机运气导致的可能性就很小。
另外还有一个问题,研究者永远也无法完全排除零假设,所以科学家们就选择了一个让他们比较舒适的门槛,也就是现在设定的P值小于0.05。
在理想情况下,一个等于0.05的P值意味着如果你重复实验100次(强调:假设零假设为真),你能得到相同的结果的次数为5次。
最后一个超级棘手、几乎大多数人都弄错的概念是:P值小于0.05并不意味着你的实验结果是由随机运气产生的几率不到5%,也不意味着你只有小于5%的概率得到假阳性的结果。它能说明的只是:在零假设为真的情况下,你得到的结果是由于随机运气导致的概率不到5%。
这听起来很吹毛求疵,但却至关重要。因为这常导致人们对P值的理解产生误会,过度自信,因为P值为0.05的实验出现假阳性的概率可以远远高于5%。
反对P < 0.05的声音
通常,P值不能用来做结论,而是确定可能性,像一种取样测试。在很长一段时间以来,小于0.05的P值取样看上去很不错。但在最近过去的几年里,越来越多的研究者和统计学家已经意识到,P<0.05并不像想象中的那么有力。
最显而易见的证据是:许多P值低于0.05门槛的论文无法被更严谨的实验方法重复。
2015年《科学》杂志的一篇论文试图复制100篇发表在一本优秀的心理学杂志上的发现,只有39%通过了测试。其他学科要稍微好一点,经济学中类似的复制发现约有60%的结果是可重复的。生物医药也同样是“可重复性危机”的重灾区,但具体数字还并不清楚。
从2015年《科学》刊登的这篇论文提供的一些线索来看,发现P值低于0.01的心理学研究的可被重复的可能性要明显高于刚好在0.05水平的研究。
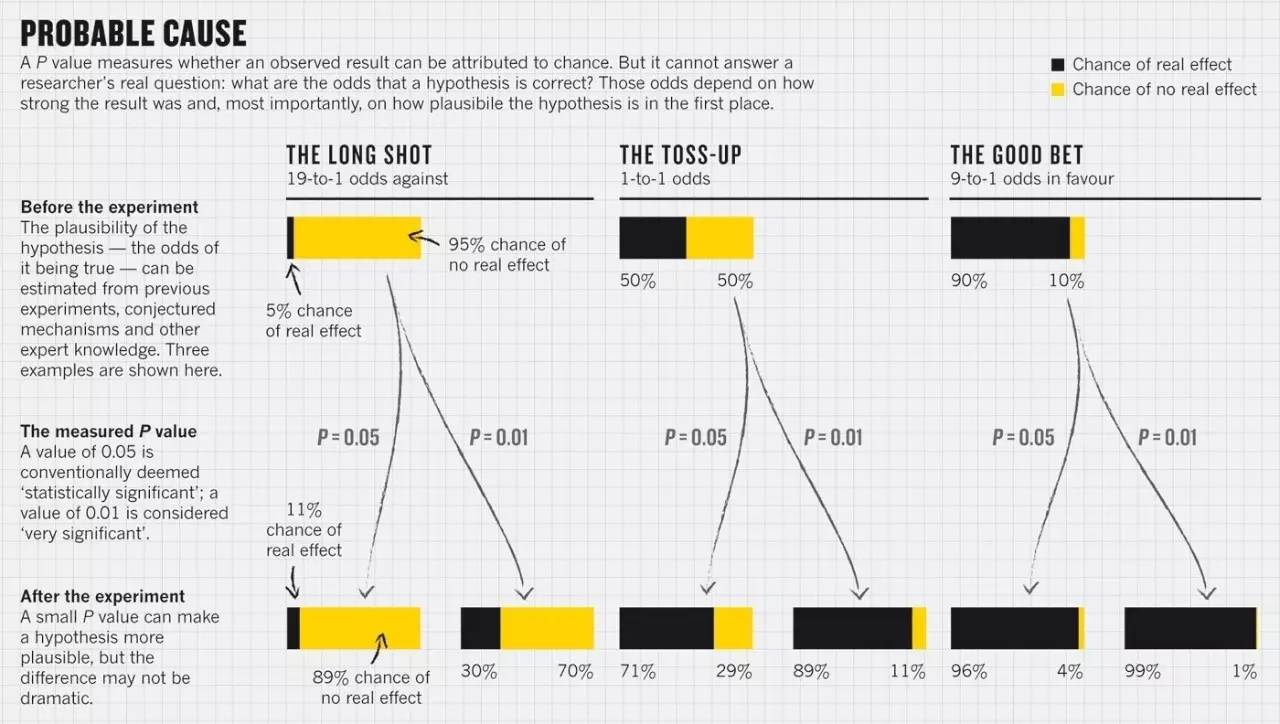
△ 通常P=0.05被视为“统计显著”,P=0.01为“非常显著”。低P值会使假设成立的可能性更大,但不会有非常明显的差异。(图片来源:R. NUZZO)
另外,还有研究人员还发现,我们能看到的所有已发表的论文都有一个名义上的“统计学上显著的”结果。 而实际上,这些P值小于0.05的绝大多数论文并不符合其真正的效果。
很久以来,科学家都认为P < 0.05代表了事情的罕见,而新的统计学发现并不是这样的。
2013年在PNAS刊登的一篇论文中,华盛顿大学的统计学家 Johnson 使用了更先进的统计技术来测试这个研究者通常所做的“一个0.05的P值意味着零假设为真的几率是5%”的假设。他的分析显示,事实上,当P值为0.05时,零假设为真的概率可达到25%到30%。
而25%和30%这样的数字,几乎很难被称得上“罕见”二字了。
更严谨的实验方法
这篇论文里所提倡的主要是在修辞上的改变:将达到0.05级别的结果称为具有“启示性”意义的结果,而达到更严格标准的0.005的结果才能被称为“统计显着”的结果。换句话说,期刊仍然可以像以前一样发表一些较弱、甚至可能无效的结果。这种语言上的调整将有希望降低媒体在发布新闻稿和新闻报道时,类似“重磅”、“大突破”、“大发现”等标题语的滥用。
统计显著的意义上的变化可能会迫使今后研究人员需采取严谨的实验方法。如果实验室确实想发表“统计显著”的结果,在将来可能会变得更加困难。例如,对一些需要参与者的实验,参与人数平均可能要增加70%,这样变化基本能将证据的力度提高六倍左右。
加重的举证责任将可能推动研究人员采用其他科学改革者一直呼吁的做法,如与其他实验室共享数据以达成共识,并对已有的科研工作进行更长远的思考。更高的门槛也将鼓励实验室在发表结果之前更多次的重复实验。
值得一提的是,在某些领域中,为了避免错误的结果,早已将P值的阈值设置的非常低。比如粒子物理学家在收集粒子对撞产生的数据中一直要求P值低于3 ×10^−7,遗传学家在进行全基因组关联研究时,也要求P值小于5×10^−8。但也有一些科学家已经放弃P值,转而使用更复杂的统计学工具,比如贝叶斯检验。
反对P < 0.005的声音
当然关于这个提案也有许多反对的声音,其中一个是心理学家 Daniel Lakens,目前他正与数十名作者联合组织反驳论文。他的主要观点是,这种改变“统计显著性”的建议可能减缓科学进步的步伐。
Lakens 举了一个例子:“我们将科学研究比喻成在公路上驾驶一辆汽车,公路会设定最高速度。你可以将你所在国家的最高速度设置为每小时20英里,这样的话没有人会因车祸而死,即便你撞倒了一个人,他们也不会死。这样很好,对吧?但在科学上我们不这样做,我们要将最高速度设置得高一点,因为那能让我们更快的抵达下一个地方。科学就是这样啊……”
Lakens 说,理想的情况下,证明一个假设所需的统计显著性的水平取决于这个假设的荒谬程度。
换句话说,如果你想要声称一个“心灵感应”这类发现是真的,你会需要一个很低的P值;但是,对一个已经很平常的概念,我们是否还需要一个如此极端的测试呢?高标准可能会阻碍只有较少科研资源的年轻博士检验他们的想法。
再者,0.05的P值也并不一定意味着实验将是假阳性。一个好的研究者会知道如何跟进和找出真相。
对这个提案的另一个批评是,它会使得科学界加剧对P值的关注。而正如上问讨论的那样,P值并不能真正告诉我们一个假设的优劣。
Ioannidis 也承认:“统计显著性本身并不能传递一个研究的意义、重要性、临床价值和实用性。”他说,在理想情况下,科学家们不需要依靠零假设测试来重新审视他们自己。但是我们不是生活在理想世界里,在现实世界中,P值仍是任何科学家都可以轻松使用来测试的一种快速简单的工具。而且在现在,P值仍在决定什么是可以被发表的这一问题上扮演很重要的角色。
值得一提的是,在某些领域中,为了避免错误的结果,早已要求非常低的P值。比如粒子物理学家在收集粒子对撞产生的数据中一直都要求P值低于3×10−7,遗传学家在进行全基因组关联研究时,要求P值小于5×10−8。而有些科学家则早已放弃P值,转而使用更复杂的统计学工具,比如贝叶斯检验。
真正的问题:科学文化氛围
或许改变统计显著性的定义并不能解决真正的问题,因为真正的问题可能是科学文化。
在2016年一项调查中采访了200多名美国知名高校的科学家,询问他们:“如果你能改变一件与现在科学圈有关的事,那将是什么?”答案中的一个清晰的回复便是:科学机构需要设置对待科研失败的更好的方式。
科学文化氛围的现状是,年轻的科学家需要一定的发表量才能获得工作,成功发表论文需要统计显着的结果,统计显著性本身并不导致可重复性危机。或许是这种科研氛围加剧了这种了使这个行业变得脆弱的情况。
但就目前而言,调整P值仍只是一个引发剧烈争辩的提案。各类期刊并不会急于在一夜之间改变编辑与审核的标准。这场辩论还将持续。
但是如果因此变成,修正了措辞的“启示性”的结果难以被发表,只得到“启示性”结果的研究无法留住科研经费,那么科学共同体或许还没有汲取足够的教训。
其实仔细想想,关于调整P值的这项提案似乎更多在说科学家需要更严谨的使用科学措辞,“启示性”或者“无效的”结果也是结果。Ioannidis说:“平均来看,'失败'的研究平比正面研究可能更有价值。”
科研机构和科学期刊其实都知道这一点,但他们只是常常忘记要这样做。
参考来源:
[1] https://osf.io/preprints/psyarxiv/mky9j/?_ga=2.29887741.370827084.1500902659-399963933.1500902659
[2] http://www.nature.com/news/big-names-in-statistics-want-to-shake-up-much-maligned-p-value-1.22375
[3] https://www.vox.com/science-and-health/2017/7/31/16021654/p-values-statistical-significance-redefine-0005
[4] http://science.sciencemag.org/content/349/6251/aac4716
[5] http://www.sciencemag.org/news/2016/03/about-40-economics-experiments-fail-replication-survey
编辑:yangfz
尊敬的畅言客户,您好。您所使用的网站评论功能已广告作弊被限制使用,如有疑问,请咨询客服电话400-780-9680。