自从虚拟化(类似KVM/Xen等)出现后,计算节点(起虚拟机的服务器节点)中虚拟机报文为了和数据中心服务器的物理网络解耦,出现了Vxlan/NvGre等overlay网络技术,而计算节点内部虚拟机的流量报文在计算节点上要经过一些虚拟网元的处理,来实现端口安全、安全组、防火墙、L2转发、L3路由(包括分布式路由)、策略路由、NAT等转发面路径的处理。从业界已有的技术实现来看,包括内核态转发、用户态转发、智能网卡等几种主要形式。

下面详细介绍下
NAPI轮询、中断,DPDK还是耗CPU,属于X86思维,性能还是要靠硬件;
Linux内核态转发的网元通常所见包括tap/tun设备、linuxbridge(通常关联LinuxIptables、vethpair等)、内核OpenvSwitch、namespace、bond等形式,拿OpenStack开源网络组件Neutron的主干前几个版本实现来说,通过tap设备作为VM的虚拟网卡,然后再Linuxbridge上通过Iptables过滤实现安全组和防火墙,在OpenvSwitch上实现L2处理,然后通过namespace的协议栈实现路由和NAT特性,最后封装报文underlay头部后,通常通过bond口选择物理网卡出主机。
内核态转发的主要主要问题除了内核模块较多、处理流程复杂,导致许多无需的模块处理增加了延迟降低了传输带宽外,还有大量因素影响性能:Linux内核网卡通常是中断式收发报文,数据从网卡到内核再经过传输到VM,内部,要经过多次数据拷贝,并且其中锁的机制较多,而且从内核态到用户态涉及进程的上下文切换,这些因素都很难在内核态全面优化。
从根本上分析,物理网卡这层的收包方式就是要根据计算节点还是网络节点来做不同设置的,只是现在计算节点和网络节点的融合导致了中断方式的懵逼;虽然Linux的部分网卡驱动也提供了NAPI这种方式,但是轮询方式和中断方式切换必然也会导致一定开销,而且没有后续报文在内核态协议栈的配合优化,性能提升还是有限。
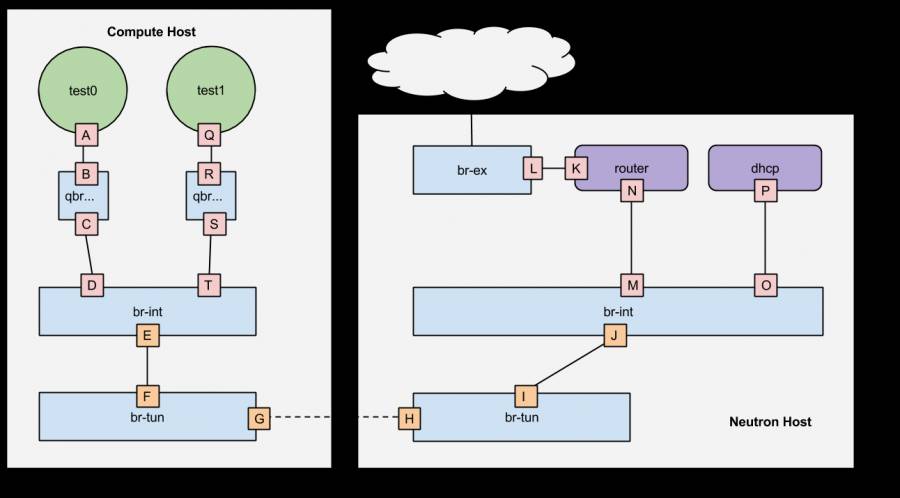
图一 RDONeutron拓扑示意图
(http://rdoproject.org/networking/networking-in-too-much-detail/)
后来Intel借着云计算的兴起推出了基于DPDK的(http://dpdk.org/)用户态收发包理念,来解决内核态转发的瓶颈,所用技术包括轮询式收发包、无锁队列、大页内存使用、用户态数据拷贝控制和多核协同处理等手段来提升性能,OpenvSwitch也有基于Dpdk的用户态版本;除了DPDK还有FD.io等多种开源用户态转发实现,Google的负载均衡器Maglev(https://www.infoq.com/news/2016/03/google-maglev)和美团的基于LVS+DPDK的负载均衡器(https://zhuanlan.zhihu.com/p/24826649)均表现出了强劲的性能。
但是用户态转发需要占用单独的网卡驱动支持DPDK(虽然有多种网卡支持DPDK并且DPDK已经被移植到多种处理器比如ARM/PowerPC等),而用户态协议栈相比Linux的内核协议栈还极其不完整(业界里闭源的产品中6Wind声称有完整的,腾讯有基于BSD的开源的fstack用途);这点使得Linux内核协议栈无法被用户态转发完全替代,虽然VM的网络仅是L2/L3/ACL/NAT等四层以下处理,但毕竟有大量的各种管理网协议要使用;而且在容器场景下宿主机如果是用户态转发,容器里的业务对用户态协议栈就有了一定的诉求。
进一步讲,DPDK仍然是使用服务器CPU的转发能力,需要占用特定的CPU,而且随着物理网络25G/100G的发展,需要占用的核会越来越多,随之还带来了同型号服务器被用户态转发占用核后虚拟机所能使用核数的问题,因为VM所能用资源的改变,很可能导致原来规划的虚拟机规格无法占用完服务器的CPU资源而浪费,但是调整flavor又会带来系列规划和用户界面呈现的问题。
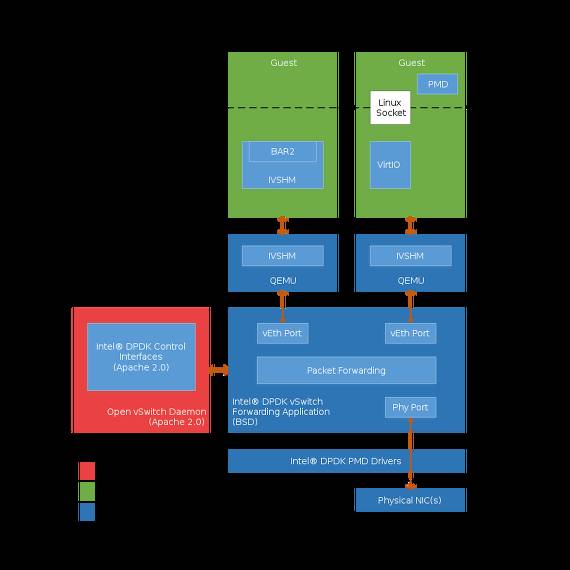
图二 VM在用户态转发的拓扑示意图每个(http://cfile30.uf.tistory.com/image/27603B42544EFF4507D853)
上面两种方式考虑的仍然是服务器物理网络不做调整的两种方案,如果物理网络可以调整,那么可以通过将网卡SR-IOV配置出多个VF,然后每个VF配置不同的Vlan并作为VM的虚拟端口,这种方案服务器内部网络简单,转发面性能非常高,并能够将服务器的CPU最大化的用于计算;但这个对物理网络设备(主要是TOR设备)有很高的要求:需要交换机端口支持hair-pin否则同主机的同租户虚拟机无法L2/L3转发,交换机需要支持L2/L3/路由/NAT等特性(博通芯片已经有对应NAT支持),所以需要新型的服务器和交换机设备来重建数据中心组网,这个无疑无法利旧已有服务器和交换机,导致已有设备浪费和新设备购买的具大投资。并且交换机通常对contrack支持无法支持,而且交换机随租户发放虚拟机要调整网络,造成虚拟网络和物理网络耦合,控制面云平台来对接SDN控制实现自动化网络配置调整,这些对云平台产品对接SDN控制器特性和SDN控制器对物理设备在控制面性能等都有很大诉求。
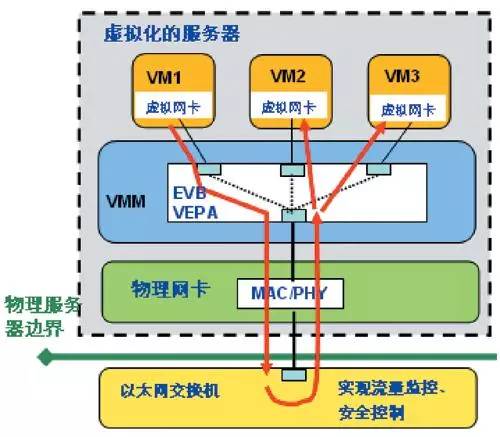
图三SRIOV+交换机Hair-pin方式拓扑示意图(http://www.edu.cn/jie_ru_ji_shu_1644/20120518/t20120518_778604_3.shtml)
为了实现基于硬件速度的高性能和虚拟网络/物理网络的解耦,智能网卡的出现成为了兼具虚拟网元灵活性和避免硬件交换机物理网络改造的融合点。AWS的HPC方案(其智能网卡ENA:https://aws.amazon.com/cn/hpc/)和微软Azure的公开论文中。
(SmartNIC: Accelerating Azure’s Network with FPGAs on OCS servers)都表示部分解决方案使用了智能网卡,另外Mellanox等厂商部分网卡也具备智能网卡流量硬件卸载功能。然后其控制面多是自研或基于Openflow等SDN的标准南向控制协议,对于Contrack等硬件实现不方便的特性则是结合Linux内核协议栈实现。

图四微软SmartNic资料图
(http://www.zdnet.com/article/linux-java-and-container-support-coming-for-microsofts-azure-microservice-platform/)
综合来看,DPDK等用户态转发仅适合于私有云/NFVI等软硬件采购解耦的方案和公有云的部分网络节点(公有云的计算节点是不太适合部署DPDK这类转发形态的),且业界AWS、Azure及国内的重要云计算厂商的发展历程都表明如此;Linux内核态协议栈是比较完善的,很难被舍弃,全新物理设备组网来使用SDN控制器下的无虚拟转发网元形态仅在少数场景存在;而硬件形态的智能网卡则在所有限制和诉求上获得了折中,并解决了绝大多数问题。
本文作者:
李俊武,sina微博北京-小武,著有《云计算网络珠玑》;三年多交换机研发经历(熟悉Broadcom、Marvell等公司交换芯片转发流程和网络协议),现在从事云计算网络架构设计方面的工作。