编者语:
主持/巴曙松;主讲/胡本立(国际数据管理协会中国分会主席)本工作笔记是由巴曙松教授发起的“全球市场与中国连线”第255期内部会议纪要,不代表任何机构的意见。本期会议由巴曙松教授主持,胡本立先生主讲。近年来人工智能通过机器对大量数据的各种“学习”来模拟人的智能方面取得了不少进展。数据的各种讨论和解决方案不断,但很少能从根本上解决“信息孤岛”问题,这与我们没能从更深层次上来理解人与数据的互动是否有关?本期报告由巴曙松教授和居珊博士共同整理,仅供内部参阅,请勿对外提供,未经书面同意,不得以任何形式摘录和发表。本纪要未经主讲嘉宾本人审阅。敬请阅读。
主讲人介绍:
胡本立先生是国际数据管理协会(DAMA)中国分会(DAMA China)的创始和现任主席。曾任世界银行首席信息技术官,香港证券及期货事务监察委员首席信息官,中国证监会战略及规划委员会委员, 中国社保基金理事会资深顾问等。近年来专注数据管理,特别是那些在数据,人和机之间复杂的认知和治理过程。
会议纪要
一、背景
近年来人工智能通过机器对大量数据的各种“学习”来模拟人的智能方面取得了不少进展。尽管还有很长的路要走,但通过机器学习,机器的能力、处理速度各方面产生了原先未预料到的结果,这使我们反思自己对人与数据的互动过程和规律是否已讨论和认识清楚。另外,每当看到一个比较大的业务或行业面临的困难时总会联想到它后面相关的数据原因、挑战或机会。虽然数据的各种讨论和解决方案不断,很少看到真能从根本上解决“信息孤岛”、“打不通”,无法“穿透”等这些数据管理难点的方案,这与我们没能从更深层次上来理解人与数据的互动是否有关?我们需要对这方面有更多的研讨。
二、一些与数据有关的历史
“数据”这个词在欧美国家大约产生于16世纪,在中国“数”和“字”拼起来大约有几千年的历史。数字化(Digitized)原先的意思是把模拟信号转变为数字信号,而数据化(Dataization/Datamation)中文都冠以‘数’,中文和英文对“数字化”和“数据化”的不同在使用时常不加区别,实际上两者是有很大差别的。数据可以模拟信号的形式存在,数字计算机主要解决了传输距离远、可纠差、信号不受损失的问题。
机器语言与人工智能、脑科学都是紧密联系在一起的,机器语言从早先的芯片微语言逐步过渡到汇编语言、程序语言、高级程序化语言,有了数据库以后,转变为结构化查询语言、图谱语言、数据挖掘,业务智能,至此开始与AI有衔接,数据挖掘里的一些算法和AI的算法有很多重叠的地方,因此这也是一个很自然的进展。
数据里经常遇到两个比较大的问题:元数据和语义模型。元数据是由发明HTML和语义互联网的专家Tim Berners-Lee提出来的,他指出元数据和数据之间是描述和被描述的关系。语义模型更加复杂,涉及到人工智能要把数据的含义表达出来。最近人工智能的进展给人的印象还是在处理模式识别、脸部识别、汽车的自动驾驶等,近两天看到模式识别不单是识别目标,而且对其后的含义也开始学习,这样的进步是很大的,也能与人更好地合作。
如果有一天人能够用自然语言与机器讲话、互相理解含义,从数据管理的角度来说,原先我们是用自然语言来描述数据,例如定义、文章都是用自然语言描写数据,而现在自然语言成了数据,这个变化是很大的,因为计算机里有compiler,将高级语言变为低级语言,然后用CPU去处理。当自然语言成了数据,整个处理方式都将不同,数据面要广的多,过程也要复杂的多。
三、几张图
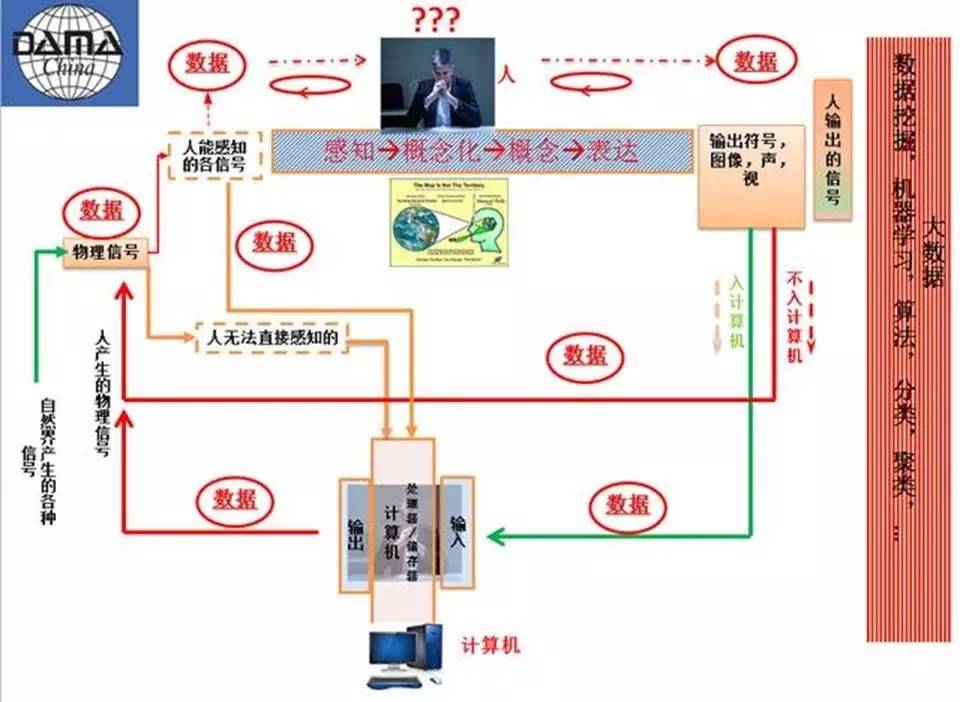
图 1
图1概括描述了数据是什么,个人认为数据就是信号,我们看到的、听到的对脑都有作用,这张图试图描述数据在人-机间,输入到输出、流动的各个阶段和全过程。对人的输入来讲,数据是物理信号(是生理刺激),人通过语音,图像,文字,表情输出数据,对他自己或别人,也是信号。在整个过程中赋予数据含义的是人。

图 2
图2讲了对人来讲与数据有关的三个“世界”:实体客观世界,概念世界和概念的表示世界。在哪个“世界”里讨论的问题不应与另一世界的混淆(比喻例外),但它们间(通过人)有复杂的映射和联系。人与数据的互动建立了这三个不同“世界”间的桥梁,包括“虚”与“实”;“主观”与“客观”等重要基本概念。有不少分类把“表示世界”认为是虚拟的,实际上它也是物理的,虚拟的还是在人的脑中。“表示世界”与“客观世界”的不同是前者是由人产生的,而后者不是。举例来说,人通过学习知道狗的发音、狗的概念,我们通常认为“狗”就是数据,实际上人工智能开始的时候不论中文英文,都不单单是个符号,而是图像化的东西,抽象后成为“狗”的概念。而男孩和女孩脑中对狗的概念又和他(她)以前的经历以及不断收集的信息有关,两种概念不完全一致。

图 3
图3描述了对同一对象,不同人会有不同理解和解读(不对称)这一现实。成年以后,通过学习、经历等因素,再来看两个同样世界中的事物,如一堆标签和一篇文章,从物理上来看,这些都是视觉上的信号,看过之后结合自身的知识经验,再回到概念层,两个人的表达可能一样也可能不一致。数据管理中一个很大的问题就是怎么达成共识,尤其是一个团队要达成共识的话是怎样一个过程,这个过程是效率很低或是很难根本做不成,理解了这个过程,不管是在数据层次还是概念层次,对我们达成共识都会有帮助。以后我们也会有很多这方面的挑战,例如国内金融改革后,监管机构之间的对话,一些交叉性领域如何达成共识,这里面有很多技巧。如何从人和数据的角度理解清楚,对达成共识可能会有所帮助。
图4-6介绍了一些相关的脑科学方面的进展,中国、美国、欧洲等都希望建立关于大脑的图谱,这项工作本身比较困难,基本上还是模式识别。《Nature》上有篇文章希望搞清词在脑中的反应是在哪一块或哪一点,有些称为概念神经细胞元,这方面的进展很快,会对人与数据的处理认识不断深化。
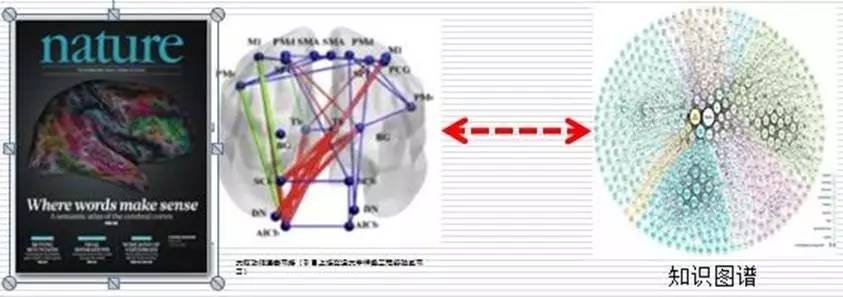
图4 自然: 语词含义的产生之处,与脑科学和数据模型结合的研讨
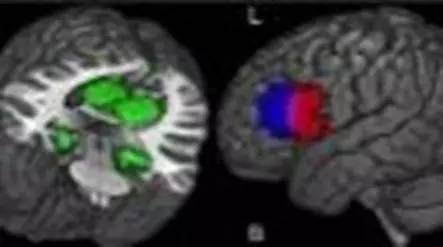
图5 人脑图
图5中约是一年前的发现,人脑中“居留地”和”食谱”在相同区域储存和处理,人脑具有储存、考虑语义等复杂功能。对于数据管理研究人员来说,哪些概念属性对人脑来说是更根本的,这些更根本的东西可能更容易达成共识。其他词包括法律文档里的用词,有些词不需要多加解释,有些则不同。图6展示了科学告诉我们人(可能)是如何处理语词的。

图 6
Tom M.Michell认为可能有些词在大脑中的反应是在同一区域,有些则散布在脑中各处,每个人反应都不一样。而Intel的人工智能专家在Amazon上做的数据分析时认为,一件事物叫什么没有它的属性重要,如果属性一致,不同的名称仍能匹配上。这些进展说明了为何尽管人的语言是不精确的,概念和用词也不一定完全一致,人之间仍能沟通,和可在一定程度上达成共识(标准),包括跨领域、跨学科的。
四、经过人(处理)的数据的一些特征问题
1、数据表示的主观与客观性
数据是概念的表示,概念有它的主、客观性,“让数据说话”不那么简单。如邓拓的《主观和虚心》中写道:“对客观事物的认识离不开主观的作用,只是主观主义才要不得。”“经验证明,有的时候对某个问题,如果有先入为主的观念,那末,在进行调查研究的过程中,就很容易发现许多符合自己口胃的材料;而对于不合自己口胃的材料和意见,就看不进去,也听不进去。这种情形所以会发生,其原因就在于调查研究的人在思想上有主观主义的成分,还没有做到真正虚心的地步。”这与数据处理很类似,当你收到一个刺激信号后,主观因素会起作用,不是完全客观的,整个过程会与原先的想法结合起来,需注意怎样避免过多的主观因素造成的数据质量等问题。
2、“实”与“虚”之分和辨
从数据的角度来看,哪些是属于“实”的数据,哪些是属于“虚”的数据,表示实体的数据与表示概念的数据的同与不同,怎么与实体经济、虚拟经济等一系列“实”与“虚”的讨论对应起来,这些需要建立在科学的基础上。
3、经验、知识与数据
“机器学习被广泛定义为‘利用经验来改善计算机系统的自身性能’。事实上,‘经验’在计算机中主要是以数据的形式存在的,因此数据是机器学习的前提和基础。”(《一文读懂特征工程》,姚易辰,数据派),但不是所有经验和知识都是显性和被表示了的,人有大量的隐性知识需要通过对话和沟通才会成为显性知识以被机器“理解”和处理。
4、在能否“整合”数据上人与机的本质区别
人大脑对数据(许多都是碎片化的)的组织和功能一直是整合的,恐怕要它孤立也不能。而机器正好相反,每个数据集,各数据库都是孤立的,仅把它们集中或连起来并不代表在任何情况下它们都是能打通的,整合的。那我们能做些什么来填补,或缩小这些鸿沟和消除信息孤岛?
五、国际、国内经济金融数据管理面临的困难和挑战
与所有学科一样,经济和金融学也离不开它们的数据。但与自然科学不同,经济和金融学是社会科学,这些数据的产生、理解和处理过程更为复杂;一个相关和根本的区别是大量的经济和金融数据是由人产生的、非自然界的,而这个过程中人不仅是产生和研究,这些数据的主体同时也是被研究的对象。尽管我们对这些复杂机制、关系和结果离“知其所以然”还远,我们至少应在对人与数据如何互动的基本理解下,对哪些经济、金融数据究竟是哪里来的,是更接近实体的还是更接近概念的,是被同一或不同群体用的等有个全过程的分析,以更好地解决所遇到的问题。
一些例子:
Mr. Greenspan 国会作证反思金融危机时讲“给金融系统的数据在不少情况下是‘垃圾进’‘垃圾出’”和“没有足够的数据”帮助造成了这次危机。许多国际机构也认同多方面的“数据缺口”是造成这次危机的主要原因之一。
G-20 DGI (Data Gap Initiative) 数据缺口项目巴塞尔关于风险数据汇总
这些和其它类似需要达成广泛共识的项目往往进展困难,花费了大量的时间和资源还不一定会成功,个人觉得注入对理解“人与数据”互动的一些规律会有帮助。
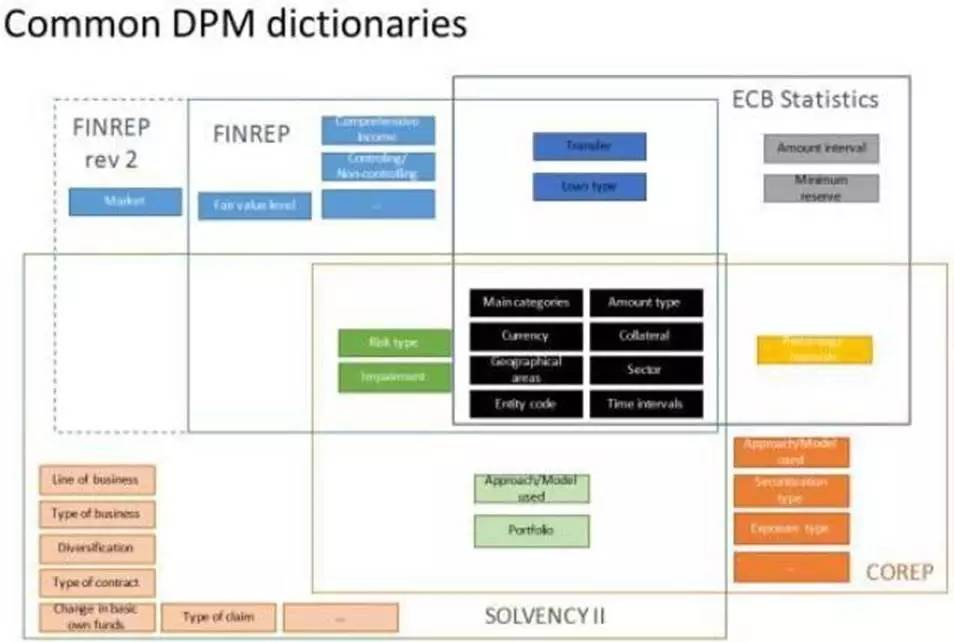
欧盟跨金融行业监管数据标准建设的研讨
欧盟能把所有金融领域,包括央行、银行、保险、资本市场的监管数据用“数据点”模型统一报告是个并不多见数据大规模汇总的成功例子。“数据点”是个更符合人思维方式来定义数据的模型,帮助人有序高效地发现各方一致或不一致的方面和原因。
人与数据的循环和回旋式互动过程远比我们目前认为的要复杂,希望通过对它的讨论能提出些科学的、更符合人与数据互动基本规律的数据管理方法、技术和工具。
问答环节:
Q1:请问国际上几大IT 如FB, Google, Amazon, 谁的大数据处理和运用能力最强?
A1:他们对数据了解和处理能力都很强;而G更注重基础性些,FB和AZ更注重他们各自的应用领域(社交和电商)。我找/买东西也往往先去G。对我个人来说,FB, AZ down 几天影响没有G down那么大,它要处理的数据量(clicks)可能比另二家要大不少。
文章来源:本文节选自巴曙松教授发起的“全球市场与中国连线”第255期内部会议纪要(本文仅代表作者观点,不代表任何机构的意见)
本篇编辑:王昌耀
尊敬的畅言客户,您好。您所使用的网站评论功能已广告作弊被限制使用,如有疑问,请咨询客服电话400-780-9680。