雷锋网 AI 研习社按: Kaggle 是全世界首屈一指的数据科学、机器学习开发者社区和竞赛平台,来看看 Kaggle 亚马逊雨林比赛金牌团队的经验分享吧。
日前,雷锋网 AI 研习社组织的学术青年分享会中,中山大学CIS实验室的研二学生刘思聪为我们带来了一场精彩的分享。他所在的队伍在 Kaggle 上的亚马逊比赛中获得了金牌,在这次的分享上,他为我们详述了比赛过程中所获得的经验以及图像比赛中的一些通用套路。
下面是他的分享内容,雷锋网 AI 研习社做了不改变原意的编辑整理:
大家好,我叫刘思聪,来自中山大学CIS实验室。我们前段时间参加了Kaggle上面一个亚马逊雨林的卫星图像比赛,取得了不错的成绩,然后也得到了一些经验,今天就给大家分享一些我们总结的图像比赛经常用到的套路。
我会对比赛做一个简单的介绍,讲一些通用的方法,比如模型的构建、分析、改善,以及比赛中我们的一些数据增强案例。另外,K折交叉验证在Kaggle比赛中,不管是图像比赛还是文本比赛都是比较常用的一个方法,我会讲一下为什么我们要做K折交叉验证以及我们在划分K折的时候有哪些要注意的点。然后我会讲在Kaggle比赛中模型集成上涉及到的技巧,最后会介绍一下我们队伍的基本情况。

先大致的说一下这个比赛,很多人看到名字后会误以为这是亚马逊公司办的比赛,其实这两者完全没有关系。它之所以被叫亚马逊是因为它的卫星图像来自亚马逊雨林,我们要做的任务是在给出的一些卫星图片上打上标签分类,一共有17个不同的标签。

我们取得的成绩如PPT所示。

另外还有我们的结果分析图。

接下来讲怎么构建单模型。
这是分享最重点的一部分,涉及到究竟是使用框架提供的预训练模型还是自己随机初始化模型去搭建一个模型,另外还涉及到如果要用预训练模型,有哪些可以用。在明白这个之后我就会大致介绍一下怎么去训练一个Baseline模型,进行结果分析与改进。

首先讲一下是用预训练模型还是使用随机初始化参数模型,这个选择对于不同比赛来说是不同的。预训练模型的好处是,我们可以利用ImageNet上预训练的参数,ImageNet是一个非常大的数据集,可以在上面训练,让模型得到比较好的提升。但是如果我们使用预训练模型,也就意味着大体的模型框架都是保持和它预训练时候设置的一样,那样能做的调整就比较少。如果我们使用随机初始化参数,对于模型,好处是几乎可以说想怎么搭就怎么搭,坏处就是我们没办法用到ImageNet上预训练的参数。
我们在比赛开始的时候就做了一些实验,自己搭建了一些随机初始化参数模型和预训练模型,发现我们任务中随机初始化参数模型的收敛速度等都远远比不上预训练模型,所以我们后面的比赛就几乎一直在用预训练模型,至少在单模型阶段是这样的。

确定了要使用预训练模型之后,会考虑具体选择哪种。其实几乎所有不同的框架都有提供自己的预训练模型,除了有一些共通的之外,还有一些不同的,有一些预训练模型只有某个框架有,有一些预训练模型大家可能都有比较分析,我们最后选择了一个PyTorch的框架。我们选择PyTorch的原因是因为首先它的代码比较轻量级,然后提供的预训练模型的种类比较多,我们用它写起来也很方便,很快就可以构建模型,大家基本上一学就会,它涵盖了绝大多数模型。

在选择了工具还有可以用的模型之后,就可以开始动手去训练一个模型。一般来说,我们最开始有做一个Baseline,这个是很正常的套路,一般只有训练一个模型,才可以对这个模型有大概的感觉。比如可以训练ResNet18,这比较简单。然后我们稍微划分一下训练集,比如说80%训练,20%验证,再比如用Adam做优化,调整一下学习率,试了这几个之后就大概可以去调整训练出比较好的模型。
一开始我们也不知道哪个范围的学习率是比较合适,我们用0.0001这个数值是比较好的,模型收敛比较快,也比较稳定,一般学习率过大的话训练会抖动,然后过小的话收敛比较慢,这个过程中我们也用到队员开发的一个工具Hyperboard,可以实时记录训练过程中那些训练曲线的变化,然后接口也比较简单,在这样一轮训练下来之后,我们一般就可以得到反馈,然后去做结果分析,分析完之后我们才能考虑下一步要怎么去改进训练或者是数据。

我们当时在比较小的模型上观察到结果是这样的,模型一开始收敛的挺快,然后它开始过拟合,训练集上Loss下降,验证集Loss反增。我们当时分析了一下,觉得官方提供的训练数据集只有4万个样本,相对这个任务来说是比较小的,比较容易发生过拟合,然后我们就用人类的先验来对它做一个数据增强,这样可以把原来的样本用一些手段把他们变的更多,然后有了这些经过数据增强的样本,有更多的数据的话,训练出来模型就比较难过拟合。用数据增强解决过拟合的问题后,我们就开始可以对模型进行调整。

解决了数据不足之后我们就可以考虑使用更大模型了。最简单的提升模型方法是使用参数规模更大的预训练模型,另外一种就是对模型进行一些改动,用预训练模型很难对卷积层去做一些改动。
我们大部分的改动都是在卷积层之后的全连接层进行的,我们后面也可以改动卷积层最后的Global Pooling层的输出大小,还可以把两个小的模型的输出特征拼在一起,然后再进行分配,拼成一个大模型。然后还可以增加Batchnorm、dropout、L2等,但在比赛中没有观察到这些参数有非常大的影响,所以我们后面并没有对这些做仔细的调整。

确定了大体的框架还有使用的模型,接下来就是比较枯燥的调参阶段,在这里非常重要的一个参数是初始学习率,刚才讲到我们选择大概0.0001这样一个基准的学习率,只是大概确定的一个范围,我们可以再做一些仔细调整。调整这个初始学习率,对最后的收敛也是有影响的。
还有就是Batch size的选择,尽量把GPU占满,一般来说是32-128之间,有时会做一些微调。一般来说,在训练的过程中,下降到一定程度之后可能就完全收敛了,或者是开始出现过拟合,这时候经常会做的一个操作就是把整体的学习率降低,这样训练往往会提升整理的效果。在调参的过程中,也要不断对参数跑出来的结果做记录,去做分析和验证,看哪些参数会比较好。

我们几乎把十几个模型都跑了一遍,有的跑了好几遍,我们发现ResNet效果是最好的,DenseNet效果紧随其后。VGG,Inception v3效果差一点。最差的是AlexNet和SqueezeNet,因为前者确实比较老而且效果也不佳,后者做的是一些压缩工作,整体上参数不会很多,所以效果比较差一些。Inception v4和Inception Res v2效果非常糟糕,我们后来没有使用。另外有些模型虽然总体比较差,但他们之间具有多样性,Ensemble到一起可以提升性能。

接下来讲一下数据增强。
我会为大家介绍一下有哪些数据增强的方法,有一个就是调整亮度、饱和度、对比度。这些调整之后,我们可以认为它是一个新的样本。然后另外来说我们要通过人类的先验,我们可以看到,把一张河流的图调亮一点,它还是一条河流,但我们可以得到一个亮度和原来不同的样本。
然后此外还常用的有随机裁剪一幅图,可以把裁剪之后的图作为输入,但是在这个比赛中我们并没有用到这种技术,因为我们考虑到有一些图片,如果去做一些随机裁剪,可能会把图里面的一些特征剪掉。
然后还有随机缩放,水平/垂直翻转,旋转,把图片变得模糊,加高斯噪声等,这些都是很常见的方法,不过并不是每一种都适合。

对于任何任务来说,我们都应该根据实际情况来选择一个好的数据增强。好的数据增强应该是这样:增强过的图片应该尽量接近原分布。对于这个比赛,我们主要使用的就是翻转和旋转这两个手段,比如左右翻转。旋转的话我们把图像进行90度、180度、270度这样去转。翻转和旋转配合,我们可以获得八种角度的一张图,并且图像的标签不会发生变化。
这样的话我们就有了更多的训练样本,相当于把这个数据集扩充了八倍,这个方法是适用于这个比赛的数据增强,但是它并不适用于所有比赛。得根据实际情况去理解,就整体来说就是不要偏离原来分布太多,然后做完数据增强之后最好还是原来的level。

然后还有一个经常要用到的数据增强。这个增强不是为了在训练时防止过拟合,我们在测试的时候其实也可以用数据增强。在测试的时候我们也会对一张图的八个方向的样本进行预测,我们可以得到八个结果,然后利用这八个结果再去进行投票,或者是加权平均或直接平均,获得的这个结果一般都会比原来单个方向的稳定得多,这可以带来很明显的提升。

接下来要讲的就是K折交叉验证。
首先说下我们为什么要做K折交叉验证。最直观的一个目的是要尽可能的用到全部的训练数据,因为我们在训练的时候,经常要划分80%的数据做训练集,20%的数据做测试集,确保当前的模型泛化性能是没有问题的。但是这样一来的话,我们就没办法拿验证集上的这部分数据来训练。
在K折交叉验证中,我们可以先把原来的数据化成K折,这儿有一个例子,把它化成5份,然后每次用其中四份来做训练集,把剩下一份做验证集,这样分别进行五遍,我们就可以在原来整个数据上一起训练一遍,然后获得了五个模型,然后再把它们的结果做一个平均,那这个平均结果其实就是在整个训练集上都训练过的结果。我们将训练结果拼接在一起,也可以为后面的集成提供out-of-fold数据。
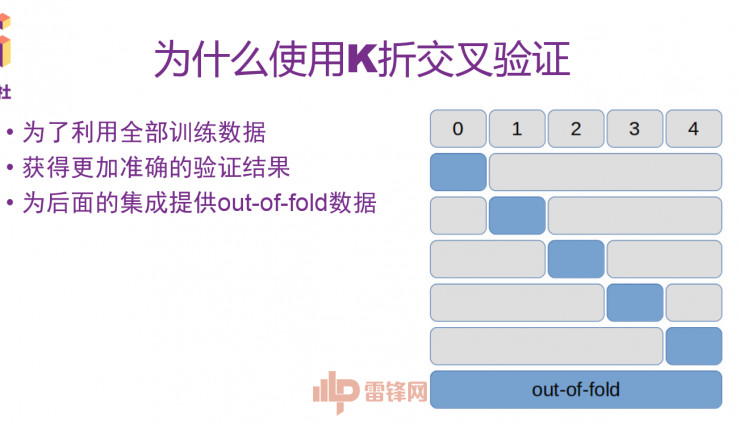
然后另外一个重点就是划分K折究竟要注意什么。主要是有这几点:一是队伍内部共享同一个划分;二是单模型阶段和模型集成阶段尽量使用同一个划分;三是训练集和验证集的划分要与训练集和测试集划分方式一致;四是折数划得越多,计算力消耗越大,需要看计算资源是否足够;五是数据量足够多时,可以不用使用K折划分。

最后的重头戏是模型集成。
模型集成在一般比赛中都会用到,它是很重要的一个环节。在图像比赛中的地位相对来说没有那些文本比赛那么重要,因为图像比赛中,我们主要用的都是卷积神经网络之类,这些模型之间并不会有特别大的不同。
Ensemble的提升主要还是要训练一些比较好的单模型,这样才能使最后的去集成比较好,然后在一些像文本的比赛的话,可能有的要用深度学习的方法,有的要用传统学习方法,有的需要手工加入一些特征,这些特征多样性很大,一般在比赛的模型集成阶段就可以带来很大的提升。
我们在比赛中不同阶段用了不同的模型集成手段,比如平均Bagging,Bagging Ensemble Selection,还有Attention Stacking,Attention Stacking是我们自己加入的一个东西,效果还不错。

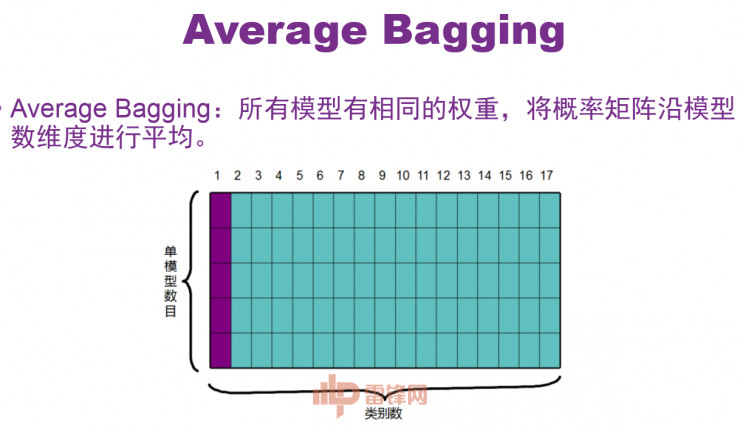
接下来讲一下模型集成阶段的单样本输入,如PPT所示,对于某一个样本来说,每个模型都可以预测17个类的结果,如果我们有五个模型,那我们就可以获得五份这样的结果,我们把他们拼到一起可以得到一个概率曲线。然后最简单粗暴的做法就是直接把结果取一个平均,当成最后的结果。这是我们在早期的方法,所有模型有相同的权重,将概率矩阵沿模型数维度进行平均。
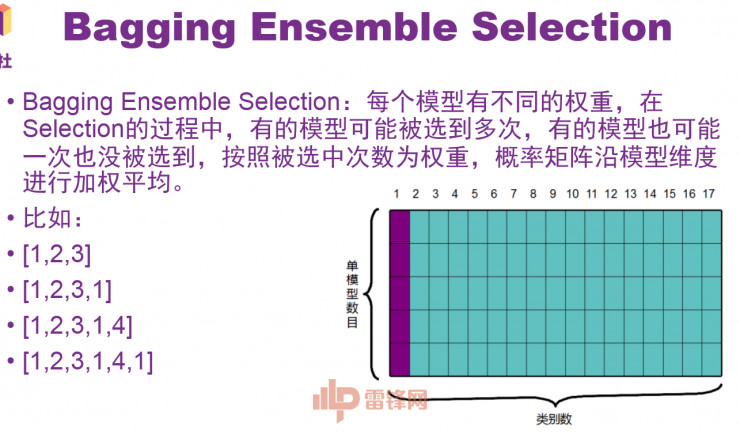
等到中期,我们用了一个稍微好一点的Bagging Ensemble Selection方法。它的好处是每个模型有不同的权重,在Selection过程中,有的模型可能被选到多次,有的模型也可能一次也没被选到,按照被选中次数为权重,概率矩阵沿模型维度进行加权平均。比如说我们最开始选择最好的三个模型,然后把12345都分别加进来,看哪个效果最好。这种方法也比较简单粗暴,这个过程中不涉及交叉验证。
到了后期我们采用Stacking,它的性能更强一点。每一个模型的每一个类都有自己的权重,这其实是比较好理解的,比如说某个模型在气象类上表现的比较好,但他在其他类上表现比较差,那样的话,他在气象类上应该有一个更高的权重,在其他类上的权重比较低。我们利用模型在不同类上的不同表现性能来做一个集成。
一般来说,在Stacking阶段,常用的一个做法就是,把每一个类都单独训练一个分类器,然后以它在之前所有模型的输入作为输入,然后去预测一个结果。我们有17个类,就训练17个单分类器,然后去预测出17个结果。在这里最简单的是直接过一个线性回归,但是我们发现在当时的验证集上容易过拟合。

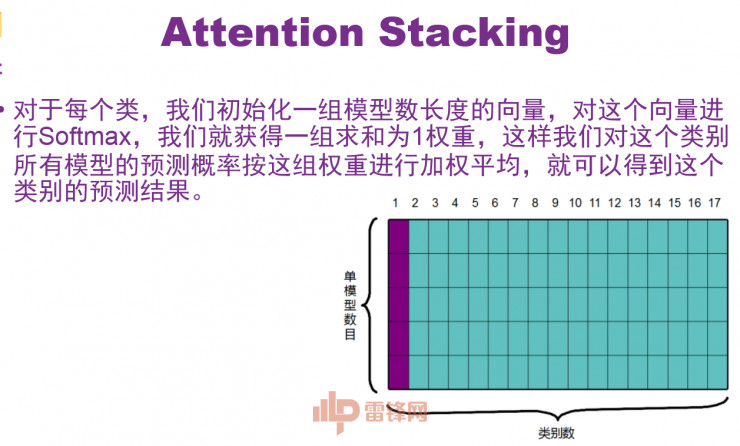
然后我们自己设置了一种比较简单的机制,即Attention Stacking。对于每一个类,我们去学一个和单模型数目一样多的参数,然后对它做Softmax,这样就使得这些参数加权为1,加权为1的话就是一个天然的权重,可以把原来的五个类按照这个权重直接加权平均。
后来我们还用Logistic Regression、Ridge Regression做stacking,我们发现Attention Stacking在验证集上效果比较好,但因为时间有限,并没有做足够量的对比实验。最后还是要提到,不管这些模型集成怎么做,在这种图像比赛中都要有比较好的单模型,而且得具有多样性,这样Ensemble才有意义。

比赛的套路讲得差不多了,最后介绍一下我们这个队伍的基本组成。我们队伍有6个人,都是中山大学潘嵘老师CIS实验室的研究生。这个比赛一共有三个月,因为之前在忙一些其他的项目,最后剩下大概20天左右才有时间全力参赛,然后我们大概用了5到6个Titan X跑了十多天,最后跑了64个模型。比赛本身的细节大家可以看我知乎专栏。

最后是问答环节。
Q:你们数据记录工具是什么?
A:我们使用的数据记录工具,比如记录曲线用的是Hyperboard,然后其他的一些统计数据只是简单地用excel表来记录。
Q:数据增强阶段为什么不是随机角度,而是用了四个固定角度?
A:这个是有对比的,我们之前做过一些随机角度的,但是发现它相比用四个固定角度,带来的提升并不高,而且会消耗更多的计算资源。
Q:Ensemble Selection用了多少个模型?
A:Ensemble Selection用了挺长一段时间,从十几个模型到六十几个模型我们都有试着用,但是后来发现这种方法没有划分验证集,想得到验证集我们只能去用Stacking。