makefile再学习
前几篇文章中,我们一起分析了字符设备驱动。假如我们已经编写好了驱动代码,那么接下来该如何做?
我们首先要进行make,编译成功后会生成一个globalmem.ko文件。接下来要将这个内核模块插入到内核当中,然后还要利用mknod命令生成一个设备文件节点。接下来我们再利用测试程序,对我们写好的驱动程序进行测试。
那么以上的工作都可以通过下面这个Makefile文件完成,直接在shell终端输入make就可编译这个内核模块,输入make clean就可以清除一些中间文件,输入make install就可以将编译好的内核模块插入到内核当中。更重要的是,这个Makefile文件具有很好的移植性。本文通过分析下面给出的Makefile文件,与大家一起更深入的学习Makefile文件的相关语法以及一些shell编程。
前几篇文章中,我们一起分析了字符设备驱动。假如我们已经编写好了驱动代码,那么接下来该如何做?
我们首先要进行make,编译成功后会生成一个globalmem.ko文件。接下来要将这个内核模块插入到内核当中,然后还要利用mknod命令生成一个设备文件节点。接下来我们再利用测试程序,对我们写好的驱动程序进行测试。
那么以上的工作都可以通过下面这个Makefile文件完成,直接在shell终端输入make就可编译这个内核模块,输入make clean就可以清除一些中间文件,输入make install就可以将编译好的内核模块插入到内核当中。更重要的是,这个Makefile文件具有很好的移植性。本文通过分析下面给出的Makefile文件,与大家一起更深入的学习Makefile文件的相关语法以及一些shell编程。

这个Makefile文件(新Makefile)比这里的Makefile文件(旧Makefile)强大了很多。
1.条件语句
首先注意这个新的Makefile文件在逻辑结构上发生了很大的变化,采用了条件语句:ifneq-else-endif。这个条件语句是用来判断括号中逗号前后的两个变量是否不相等。ifneq之后为符合条件时所要执行的语句,相应的else之后为不符合条件时要执行的语句。上述Makefile文件中的ifneq ($(KERNELRELEASE),)是用来判断KERNELRELEASE变量是否为空,不为空则符合条件。
类似的还有下面的条件语句,只不过条件判断的类型不同。
ifeq-else-endif:如果两个变量相等,则满足条件。
下面两种条件语句中,条件判断处为变量名,是用来判断此变量是否被定义过。
ifdef-else-endif:如果变量被定义,满足条件。
ifndef-else-endif:如果变量未被定义,满足条件。
不过,上述两个条件语句所判断的变量定义没有递归性,比如下面例子:
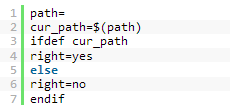
这个例子中最终执行的是right=yes。虽然path为空,但是cur_path=$(path)却被认为是定义了cur_path变量。正如上面所说定义没有递归行。
2.变量赋值
在Makefile文件中定义一个变量的格式为:变量名 赋值符 变量值
赋值符通常有以下四种类型:=,:=,?=,+=。对于赋值符=与我们平日里使用的等号差不多,但是这里我们需要清除一个概念,那就是递归展开变量。为了更清除的说明上面的概念,请看下面的例子:
这个例子中最终执行的是right=yes。虽然path为空,但是cur_path=$(path)却被认为是定义了cur_path变量。正如上面所说定义没有递归行。
2.变量赋值
在Makefile文件中定义一个变量的格式为:变量名 赋值符 变量值
赋值符通常有以下四种类型:=,:=,?=,+=。对于赋值符=与我们平日里使用的等号差不多,但是这里我们需要清除一个概念,那就是递归展开变量。为了更清除的说明上面的概念,请看下面的例子:

很显然结果为yes。当执行make时,first首先展开为second,接着second又展开成为third,再后来引用third的值即yes。可以看到first是递归展开而得到最后的yes值的。这便是我们刚才所谓的递归展开变量。
而与上述变量赋值符号不同的是,:=赋值符号是立即展开变量的,同样的例子,只不过这次我们使用:=赋值符:
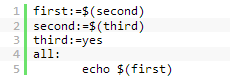
此时first为空。这是因为在定义first变量时就立即展开了second,因为second此时未定义。即便此句之后为second变量赋了值,但first的值为空。
另外两个赋值符号比较容易理解。首先+=赋值符是在变量原有值的基础上再增加新的值,而不是覆盖原有变量值。而?=赋值符首先会判断变量实现是否已经被赋值,只有之前未被赋值的变量此刻才能被赋值。
OK,了解了赋值符号的含义,那么再次看上述的Makefile文件,就会清晰很多。
3.伪目标
正如上述所言,直接在shell终端输入make就会执行目标all后的命令,这并不是all目标具有什么默认的效果。只不过在Makefile文件中,第一个目标总被认为是最终目标。因此可以想象到,当你交换一下all和clean的位置,直接执行make时会自动执行clean后面的命令。并且不一定总对第一个目标起名为all,你可以使用你喜欢的目标名(也许all是一种无声的约定 )。
通常在clean这样的目标后都没有依赖文件,因为我们的目的是想让make执行这些目标后的命令。但是当Makefile文件所在目录下有一个名为clean的文件时,此时make clean就会被认为是生成clean目标文件。而clean后是没有任何依赖文件的,所以每次make clean后clean目标文件都会被认为是最新,而不去执行下面的命令,这虽然符合语法规则,但并不能达到我们使用clean的目的。
因此我们必须将clean这种目标定义成伪目标。定义方法为:.PHONY:all。这样不管该目录下是否有同名的文件都会执行clean后的命令。现在你应该明被为什么MAKEFILE文件中有这么多以.PHONY开头的目标文件了吧。
4.为什么要用makefile
内核模块化简单实用,但是编译却成了问题:有时候我们只是改动了某个文件的一小部分就不得不编译整个内核,这是个很可怕的事情。但是GNU make引入后,这个问题就迎刃而解了:make只会编译已被改动代码的文件,而不是将所有文件都编译。但是make具体如何对源文件进行编译,怎么编译?这个时候就需要makefile文件了。在之前的文章当中,我们对Makefile文件下过“编译规则”这样的定义,下面通过分析上面的Makefile文件,我们具体感受一下这个“编译规则”。
整个Makefile文件根据KERNELRELEASE的值来划分不同的编译规则(方式),这里的KERNELRELEASE只会在内核源码目录下显示当前内核的版本号。
一般情况下,我们编写的内核模块源文件所在的目录并非位于内核源码根目录(或其子目录)下。那么此时就不符合ifueq条件,即执行else语句下的编译规则。这种情况下,当我们输入make后,就会执行make -C $(KDIR) M=$(PWD) modules这条命令。注意这条命令后的modules,它表示将会编译所有在配置菜单中被选作模块编译的那些内容(也就是赋值给obj-m的那些目标)。接下来由于-C $(KDIR)参数的原因,make会转向内核源码根目录下去执行。根据M后的目录,编译我们写的内核模块源码,生成.o文件。接着联合一些中间文件生成.ko文件。这便是make生成整个内核目标文件的过程。这个过程可以在make之后在终端产生的一系列描述文字得到。
上面这种情况会将我们编写的内核模块源码编译成内核模块目标文件,接下来就是我们熟悉的内核模块插入了。不过当我们所写的内核模块文件处于内核源码目录下时,KERNELRELEASE就会非空(此时为版本号),那么此时就满足ifueq条件了。什么时候我们编写的内核模块源码会处在内核源码目录下?此时的内核编译是那种方式?
在前面的文章中我们假设已经写好了驱动代码,然后在Kconfig文件中为这个驱动编写配置选项。在配置菜单中有了此驱动的相关配置选项后,接下来用户可以选择是否会将此驱动源码一起编译进内核。那么此时Makefile文件的作用就是将此内核模块源码编译进内核(obj-m := $(TARGET).o)。不过注意,只是通知内核下次编译“带上我”,并没有实际编译。
现在应该明白整个Makefile文件的逻辑结构了吧?
此时first为空。这是因为在定义first变量时就立即展开了second,因为second此时未定义。即便此句之后为second变量赋了值,但first的值为空。
另外两个赋值符号比较容易理解。首先+=赋值符是在变量原有值的基础上再增加新的值,而不是覆盖原有变量值。而?=赋值符首先会判断变量实现是否已经被赋值,只有之前未被赋值的变量此刻才能被赋值。
OK,了解了赋值符号的含义,那么再次看上述的Makefile文件,就会清晰很多。
3.伪目标
正如上述所言,直接在shell终端输入make就会执行目标all后的命令,这并不是all目标具有什么默认的效果。只不过在Makefile文件中,第一个目标总被认为是最终目标。因此可以想象到,当你交换一下all和clean的位置,直接执行make时会自动执行clean后面的命令。并且不一定总对第一个目标起名为all,你可以使用你喜欢的目标名(也许all是一种无声的约定 )。
通常在clean这样的目标后都没有依赖文件,因为我们的目的是想让make执行这些目标后的命令。但是当Makefile文件所在目录下有一个名为clean的文件时,此时make clean就会被认为是生成clean目标文件。而clean后是没有任何依赖文件的,所以每次make clean后clean目标文件都会被认为是最新,而不去执行下面的命令,这虽然符合语法规则,但并不能达到我们使用clean的目的。
因此我们必须将clean这种目标定义成伪目标。定义方法为:.PHONY:all。这样不管该目录下是否有同名的文件都会执行clean后的命令。现在你应该明被为什么MAKEFILE文件中有这么多以.PHONY开头的目标文件了吧。
4.为什么要用makefile
内核模块化简单实用,但是编译却成了问题:有时候我们只是改动了某个文件的一小部分就不得不编译整个内核,这是个很可怕的事情。但是GNU make引入后,这个问题就迎刃而解了:make只会编译已被改动代码的文件,而不是将所有文件都编译。但是make具体如何对源文件进行编译,怎么编译?这个时候就需要makefile文件了。在之前的文章当中,我们对Makefile文件下过“编译规则”这样的定义,下面通过分析上面的Makefile文件,我们具体感受一下这个“编译规则”。
整个Makefile文件根据KERNELRELEASE的值来划分不同的编译规则(方式),这里的KERNELRELEASE只会在内核源码目录下显示当前内核的版本号。
一般情况下,我们编写的内核模块源文件所在的目录并非位于内核源码根目录(或其子目录)下。那么此时就不符合ifueq条件,即执行else语句下的编译规则。这种情况下,当我们输入make后,就会执行make -C $(KDIR) M=$(PWD) modules这条命令。注意这条命令后的modules,它表示将会编译所有在配置菜单中被选作模块编译的那些内容(也就是赋值给obj-m的那些目标)。接下来由于-C $(KDIR)参数的原因,make会转向内核源码根目录下去执行。根据M后的目录,编译我们写的内核模块源码,生成.o文件。接着联合一些中间文件生成.ko文件。这便是make生成整个内核目标文件的过程。这个过程可以在make之后在终端产生的一系列描述文字得到。
上面这种情况会将我们编写的内核模块源码编译成内核模块目标文件,接下来就是我们熟悉的内核模块插入了。不过当我们所写的内核模块文件处于内核源码目录下时,KERNELRELEASE就会非空(此时为版本号),那么此时就满足ifueq条件了。什么时候我们编写的内核模块源码会处在内核源码目录下?此时的内核编译是那种方式?
在前面的文章中我们假设已经写好了驱动代码,然后在Kconfig文件中为这个驱动编写配置选项。在配置菜单中有了此驱动的相关配置选项后,接下来用户可以选择是否会将此驱动源码一起编译进内核。那么此时Makefile文件的作用就是将此内核模块源码编译进内核(obj-m := $(TARGET).o)。不过注意,只是通知内核下次编译“带上我”,并没有实际编译。
现在应该明白整个Makefile文件的逻辑结构了吧?返回搜狐,查看更多
责任编辑: