 )
)�������ܣ��� Cloudinsight���������ˣ�רע�����ݿ��������������������������������̹�����DevOps��Ŀǰ��Ҫ�о�����Ϊ���� Spring Boot �� Spring Cloud �����������������ȹ�����С��ҵ��˾�����˺ܶ������Ŀ�Լ���ҵ��Ŀ�ľ��飬�ó����� Ruby��Java��ϵͳ������ͬʱҲϲ���о�����С�ڼ�����
����
����������Խ��Խ��ij��̺ͻ������� OpenStack� IaaS ��Ȼ����ܹ�������Ʒ��Ӷ�ʹ�� OpenStack �ķ�չ����˾���ƶ���
��������������һ���Ӵ�ļܹ����ܹ������ȶ����ָ�Ч����ת����Ҳ����һ�����£�������ʵ��һ��ǿ��ȫ������չ�� OpenStack ���ϵͳ Ҳ��Ϊ���ºܶ��˹�ע OpenStack ʱ��Ҫ���ǵ���Ҫ���֡�
�������ͬʱ���� OpenStack �Ͻڵ���Ŀ�������ض�������������ӣ����ϵͳҲٲȻ��Ϊһ����ƽ̨�dz���Ҫ�����ԣ�Ҳ������һ�� OpenStack �Ŀ���ά�̶ȵIJο���
�����������������˽��µ���ʲô�� OpenStack �Լ�����ع��ɡ�
����ʲô�� OpenStack
����OpenStack ��һ���������Һ��պ���ֺ� Rackspace �����з��� IaaS ���������κ��˶��������н������ṩ�ƶ���������⣬OpenStack Ҳ������������ǽ�ڵ�˽���ƣ��ṩ��������ҵ�ڸ����Ź�����Դ������˵��OpenStack ����һ���ṩ˽�л������ Amazon Web Services������ 5 ������չ������ OpenStack ��Ӫ���Ѿ����� Google�����ա�IBM �� Intel��
�������� OpenStack ��˵�������ģ�� Nova ������ϵͳ����Ҫ����ɲ���
����OpenStack ģ�鹹��
������Ȼ�ᵽ Nova ����ô���б�Ҫ˵˵ OpenStack ��ģ�鹹�ɡ�OpenStack ������ 5 ����Ҫģ�鹹�ɣ�
Nova - �������
Keysyone - ��֤����
Glance - �������
Neutron - �����������
Cinder - �洢����
Horizon - UI ���
�����ܵ���˵��OpenStack ���� AWS �ṩ������㵥Ԫ EC2������洢 S3���������� VPC�ȡ�����Щ�������ģ�������һ���������Ƽ������ƽ̨����������������Ĵ洢 Swfit����Դ��� Ceilometer ����ϵͳ���� Heat����ô����Ƽ������ƽ̨�����������
����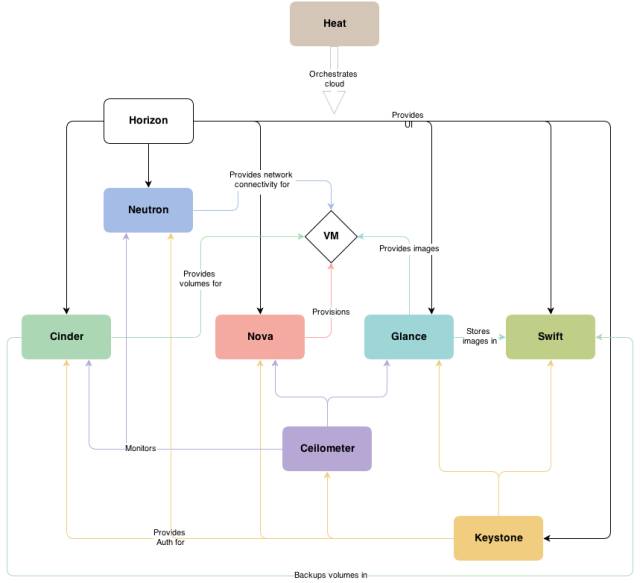
�������������������� OpenStack ��ع�ϵ����ܵ� 3 ��ģ�飺Nova��Keystone �� Neutron�������Ҹ��õ�����ʹ OpenStack ���ϵͳ��
����Nova
����Nova ���ܼ��ص㣺
ʵ���������ڹ���
������Դ����
��������Ȩ����
���� REST �� API
�첽����ͨ��
֧�ָ���������Xen��XenServer/XCP��KVM��UML��VMware vSphere �� Hyper-V
�������� Nova �Ĺ��ܣ��ڽ��� OpenStack ���ʱ���Թ�ע�������ݣ�
openstack.nova.current_workload����ǰ Nova �� Workload������ build, snapshot, migration, resize ���ֶ����ĸ��ء�
openstack.nova.running_vms����ǰ Nova �����е��������ʵ����instance����������
openstack.nova.hypervisor_load.1:hypervisor ���ָ�ꣻ����һ������ϵͳ�����⣬������ disk, ram, cpu �����ָ�ꡣ
openstack.nova.limits.max_personality���� project ���⻧��ص�ָ�ꣻ������ personality ��� image, security ���ָ�ꡣ
����OpenStack �ڲ�����ѭ AMQP������Ϣ����Э�飩�Ļ����ϣ����� Rabbit MQ ��Ϊ����Ϣ���н���ͨ�š�Nova ������Ӧ������첽���ã���������պ������������һ���ص�������ʹ�����첽ͨ�ţ��������û��Ķ����������ڵȴ�״̬�����磬����һ��ʵ�����ϴ�һ�ݾ���Ĺ��̽�Ϊ��ʱ��API���þͽ��ȴ����ؽ������Ӱ�������������ڴ��첽ͨ�����˺ܴ����ã�ʹ����ϵͳ��ø��Ӹ�Ч��
����Neutron & Keystone
����Neutron Ϊ OpenStack�ṩ�����������������ʹ���������ø�Ϊ��Keystone Ϊ���е� OpenStack����ṩ��֤�ͷ��ʲ��Է������������� REST������ Identity API��ϵͳ���й�������Ҫ�ԣ��������ڣ�Swift��Glance��Nova �Ƚ�����֤����Ȩ����ʵ�ϣ���Ȩͨ���Զ�����Ϣ��Դ������ĺϷ��Խ��м�����
������Щ OpenStack ָ��ֵ�ù�ע
����OpenStack ���ӳ̶��� Gartner�������ҵ��ѯ OpenStack �˽����ʱ����ѯ�� 3 �����⣺
���ҵ����Ҫ���һ�� IaaS ˽����ƽ̨����?
���м�������Դ��֧����ô���ӵ���Ŀ��?
�� OpenStack �����Ŀ�Դ��ܺ�����Ĺ���������?
�����ɼ� OpenStack ������һ�����������ֵĹ��̡����ڹ��ڳ����� OpenStack �й��������� Cloudinsight��������֯��������ҵ�Ϳ����߸��õ�ʹ�� OpenStack��
����
����Ϊ�˰��������õؼ��OpenStack������ͨ�������ȡ����ָ���ͼ������������Щָ��ֵ�ù�ע���Ӷ��������� OpenStack ��ء�
�������������������� OpenStack ��˵���¼���ָ��ļ������Ҫ��ע�ģ�
Hypervisor ָ�� - ���е������������hypervisor �������صȣ�
Nova Server ָ�� - ���̵Ķ�д���ʣ�RAM ���ָ��ȣ�
Tenant ָ�� - ��Դʹ�������CPU �����ȣ�
Message Queue ָ�� - MQ �Ĵ�С��
����
����Nova �Թ���ƽ̨�����ݵdz���������������Ƶļ�����Դ�����硢��Ȩ����ȡ���ԭ��֧�� KVM, QEMU ������Ҳ�ṩ Xen, VMware vSphere �� Hyper-V ��֧�֡�Nova ���� AWS �� EC2 �� S3 API������ AWS ͨ�� Nova ���ǿ��Է������ֲӦ�ã�����Ӧ�õIJ���ʱ�䡣
����
����Nova ָ��Ͱ����� Hypervisor, Nova Server, Tenant ָ�ꡣͨ�� Hypervisor ָ������˽ϵͳ����������������أ��� Nova Server ָ������˽�ij������������������Tenant ָ�����ǿ��Բ鿴����⻧����Դʹ�������
����Hypervisor ָ��
����
����Ϊ�˷�����ӷ������⣬�ڴ�������ȡ������ 7 ��ָ�꣬���鿴 Hypervisor �����ܡ�����ͼ��֪��Hypervisor ���� Nova ģ�����������صIJ��֡�
����
����hypervisor_load - ��ָ�����ϵͳ���أ��е����Ʋ���ϵͳ��system.load.1 ָ�꣬��ʶ��ȥ 1 ������ϵͳ���ء����ϵͳ����������һ����˵��ص��������ָ��Ҳ����������ʱ��Ҫ������ܽ����Ż���
����current_workload - һ����˵��hypervisor ���������build, snapshot, migrate, resize����ָ����ʾ��ǰ�������������� hypervisor ����������� IO ��Դ������ǰ���������������ߣ�һ����˵�ᵼ�� IO ƿ�����⡣
����running_vms - ��ǰ���е������������ͨ�����ݾۺϹ��ܣ��������˽�����ƽ̨�����������������ϵͳ���غ������������������˽ OpenStack ��������������
����
����vcpus_available- ��ǰ CPU ʹ�����������������һ���DZ��ֲ���ġ�������ͨ�����ø�ָ��ı���������ظ�ָ��ı仯���Ӷ�Ԥ���쳣�����ڿ��������У���ָ���������ļ�����塣Խ�ߵ� CPU ������������Խ�����Դ�ṩ�����ڼ��������������ָ����ֶ�Ȼ���͵�������Ǵ�������Ҫ��������ˡ�
����
����free_disk_gb - ���̵Ŀ��������ֱ��Ӱ���Ƿ�����½����������ע��ָ������˽��ʱ��Ҫ��ռ�ô��̿ռ�ϴ��ʵ������Ǩ�ơ�
����free_ram_mb - �ʹ��̵Ŀ���������ƣ�RAM �Ŀ������Ҳ��һ���dz�ֵ�ù�ע����������ڹؼ���Դ��
����Nova Server ָ��
������ע Nova Server ָ������˽���Ҫ�ڵ����Ϣ����ÿ���ڵ��� Nova ����������������Ӷ�Ԥ���Ƿ���� Noisy Neighbor Problem��
��������Ҫ�˽�ÿ��ʵ������������ľ���ָ�꣬�� CPU �����ʡ��ڴ桢�����ָ�꣬������ʹ�� Cloudinsight �� Zabbix��ļ�ع��߽��� Agent ��װ��ÿ��������ڲ���ͨ����ǩ���������ݾۺϺͷ��飬���Դﵽ��רҵ���ļ�س̶ȡ�
����
����hdd_read_req - ��������У�ÿ�����̵� RAM ʹ������ʮ�����ġ��鿴 HDD �Ķ���������������ζ�ż�� Nova �ڵ��������Ļ������ܡ�������˵������ָ����ַ�ֵ������ζ��������� RAM ̫С�ˣ��Ӷ����½�С�ķ�ҳ���̶�ʹ�ö� HDD �Ķ�����������������ʱ������Ҫ�� Nova ��Ⱥ���������Ų�����
����Tenant ָ��
����Tenant ���������һ��ǰ�����۵�����ģ��ر��ǹ��� SaaS�����������Ժ��⻧����˵������һ���û���������ͬ����û����䲻һ������Դ�����Դﵽ��Դ�ĺ������䣬�Ӷ��ﵽ��������
��������⻧���ָ�꣬Ҳ����ζ���ڼ����ҵ����ص�ָ�ꡣ
����
����total_cores_used & max_total_cores - Core ��Ϊ��Ҫ����Դ���˽���ʹ������������������Ƿ���Ҫ�ڼ���������£��������Դ���Ƿ���Ҫ�ڳ����ϵ�ʹ���ʵ�����£�������Դ���䡣
����total_instances_used & max_total_instances - Instance ����Ҳ����������������� core һ������Ҫ����Դ������⻧�ĵ�ǰʹ�����������������������������Ƿ���ҪΪ���⻧������Դ��
����RabbitMQָ��
����
����RabbitMQָ������ʲô�أ�����������˵��OpenStack �ڲ�����ѭ AMQP������Ϣ����Э�飩�Ļ����ϣ����� Rabbit MQ ��Ϊ����Ϣ���н���ͨ�š�
����Ҳ����˵����� RabbitMQ ָ����ζ�ż�� OpenStack ����������������Ͼ�ͨѶ���жϻ�������Ҫ��һ�����������
����
����consumer_utilisation - ��������£���ָ�걣���� 100% ��ֵ������õģ�����ζ��ÿ�����ж����Լ�ʱ�ش�������Ϣ������ӵ�º� Comsumer Prefetch ���ή��ָ�����ֵ��SO SAD��
����
����memory - �ʹ���� MQ һ����RabbitMQ �����ڴ治���õ�����µ��ô��̡����ϴ��̷�ҳ�����µ����������ӣ�������ʹ���ڴ�ʹ��������ϵͳ RAM �� 40%��Ĭ��ֵ����RabbitMQ �����ȶ���Ϣ�����߽��н�����Duang����������Ͳ����ˡ�
����count - ����Ϊ��ָ������ָ�걨�����ԣ�����ֵΪ 0 ʱ�������������Ͼ���Ч���е������� 0�������൱���µ������ء�
����consumers - �� count һ�������ø������ȽϺá���ָ��Ϊ 0 ��һ���������ħ���������顣������������������������Ƽ��������ַ�ʽ��Aliveness Testing ��StackTach ���ߡ�
����Cloudinsight ��Ϊ������֧�� OpenStack ��صļ�ع��ߣ��ڴˣ�����ϣ���Ѿ�ʹ�� OpenStack ����ҵ�Ϳ����ߣ������� Cloudinsight OpenStack ��� Beta �汾���� Cloudinsight �ܹ����õ��Ż� OpenStack ��صĹ��ܡ�
��������ϵ OneAPM����ʦ����������OneAPM�ǹ������ȵ����Ӧ�ó����һվʽӦ�����ܹ���ƽ̨��OneAPM Cloud Insight����ء����������㡢Э�������ӻ���һ������������ IT ��˾��������ϵͳ����ϵ�������ʱ��ɱ�Ͷ�룬����ά�������Ӹ�Ч�������Ķ����༼�����£������ OneAPM �ٷ�����������






























����˵�������а�