 )
)������Ϸ����ں����ɿ��ٹ�ע��
������Դ��hengyunabc
�������ӣ�https://blog.csdn.net/hengyunabc/article/details/33336795
�������ķ�������llvm libc++��ʵ�֣�https://libcxx.llvm.org/
����C++11�еĸ���mutex, lock����ʵ���϶��Ƕ�posix��mutex��condition�ķ�װ����������Ҳ�кܶ�ϸ��ֵ��ѧϰ��
����std::mutex
������������std::mutex��
����������һ��pthread_mutex_t __m_���ܼ�ÿ�������ø�����

����������״̬��std::defer_lock, std::try_to_lock, std::adopt_lock
���������������ڱ�ʶ���ڴ��ݵ�һЩ��װ��ʱ������״̬��
std::defer_lock����û�л�ȡ����
std::try_to_lock���ڰ�װ���ʱ������ȥ��ȡ��
std::adopt_lock���������Ѿ��������
����������������ʵ����������ƫ�ػ��ģ��������յ�struct��
����
����������Ĵ�����Ϳ��Կ�����������������ô�õ��ˡ�
����std::lock_guard
���������Ƚ���Ҫ����Ϊ��������ʹ��lock��ʱ�ֶ���Ҫ�������
�����������ʵ�ܼ�
�����ڹ��캯������� mutext.lock()��
�������������������mutex.unlock() ������
������ΪC++���ں����׳��쳣ʱ���Զ������������ڵı�������������������ʹ��std::lock_guard�������쳣ʱ�Զ��ͷ����������ΪʲôҪ����ֱ��ʹ��mutex�ĺ���������Ҫ��std::lock_guard��ԭ���ˡ�
����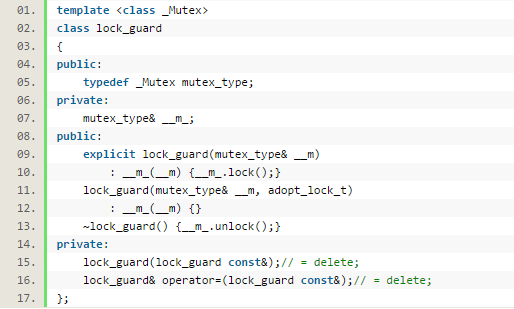
����ע�⣬std::lock_guard���������캯������ֻ����mutexʱ�����ڹ��캯��ʱ����mutext.lock()���������
������������adopt_lock_tʱ��˵���������Ѿ��õ����������Բ��ٳ���ȥ�������
����std::unique_lock
����unique_lockʵ����Ҳ��һ����װ�࣬����Ϊunique�����Ǻ�std::lock���������õġ�
����ע�⣬����һ��owns_lock������release()��������������std::lock�������õ���
����owns_lock���������ж��Ƿ�ӵ������
����release()����������˶����Ĺ�����������ʱ������ȥunlock����
�����ٿ���unique_lock��ʵ�֣����Է��֣�������������;���������ƫ�ػ��õģ�
����
����
����std::lock �� std::try_lock ����
��������Ķ���������������Ǻ�����
����std::lock��std::try_lock����������ͬʱʹ�ö����ʱ����ֹ���������ʵ���Ϻ���Ҫ�ģ���Ϊ��д�����������������ͬ�����⣬�����׳�����
����Ҫע�����std::try_lock�����ķ���ֵ��
�������ɹ�ʱ������-1��
������ʧ��ʱ�����صڼ�����û�л�ȡ�ɹ�����0��ʼ������
��������������ֻ���������������������Ȼ�������Ƚϼ�������ȴ�д����£�
����template<class_L0, class_L1>
����void lock(_L0& __l0,_L1& __l1)
����{
����while(true)
����{
����{
����unique_lock __u0(__l0);
����if(__l1.try_lock())//�ѻ����l0���ٳ��Ի�ȡl1
����{
����__u0.release();//l0��l1���ѻ�ȡ������Ϊunique_lock����ʱ���ͷ�l0������Ҫ����release()�������������ͷ�l0����
����break;
����}
����}//���ͬʱ��ȡl0,l1ʧ�ܣ�������ͷ�l0��
����sched_yield();//���̷߳ŵ�ͬһ���ȼ��ĵ��ȶ��е�β����CPU�л��������߳�ִ��
����{
����unique_lock __u1(__l1);//��Ϊ���波���Ȼ�ȡl1ʧ�ܣ�˵���б���߳��ڳ���l1����ô����ȳ��Ի�ȡ��l1��ֻ��ǰ����߳��ͷ��ˣ��ſ��ܻ�ȡ����
����if(__l0.try_lock())
����{
����__u1.release();
����break;
����}
����}
����sched_yield();
����}
����}
����template<class_L0, class_L1>
����int try_lock(_L0& __l0,_L1& __l1)
����{
����unique_lock __u0(__l0,try_to_lock);
����if(__u0.owns_lock())
����{
����if(__l1.try_lock())//ע��try_lock����ֵ�Ķ��壬��������������
����{
����__u0.release();
����return-1;
����}
����else
����return1;
����}
����return0;
����}
���������lock�����ó��Եİ취��ֹ��������
�������������������������ô�ڶ��������������أ�
������������std::try_lock������ʵ�֣�
��������ݹ�ص�����try_lock�������������ȫ��������ȡ�ɹ��������ΰ����е�unique_lock��release����
���������ʧ�ܣ������ʧ�ܵĴ��������շ��ء�
����template<class_L0, class_L1, class_L2, class... _L3>
����int try_lock(_L0& __l0,_L1& __l1,_L2& __l2,_L3&...__l3)
����{
����int__r= 0;
����unique_lock __u0(__l0,try_to_lock);
����if(__u0.owns_lock())
����{
����__r= try_lock(__l1,__l2,__l3...);
����if(__r== -1)
����__u0.release();
����else
����++__r;
����}
����return__r;
����}
�����������������std::lock��ʵ�֣�
����template<class_L0, class_L1, class_L2, class..._L3>
����void __lock_first(int__i,_L0& __l0,_L1& __l1,_L2& __l2,_L3& ...__l3)
����{
����while(true)
����{
����switch(__i)//__i���������һ�λ�ȡ������ĵڼ�����ʧ�ܣ���0��ʼ����
����{
����case0: //��һ��ִ��ʱ��__i��0
����{
����unique_lock __u0(__l0);
����__i= try_lock(__l1,__l2,__l3...);
����if(__i== -1)//��ȡ��l0֮��������Ի�ȡ�������Ҳ�ɹ��ˣ���ȫ��������ȡ���ˣ�������unique_lockΪrelease��������
����{
����__u0.release();
����return;
����}
����}
����++__i;//��Ϊ__i��ʾ�ǻ�ȡ�ڼ�����ʧ�ܣ��������try_lock(__l1,__l2__l3,...)�Ǵ�l1��ʼ�ģ��������Ҫ+1��������û�л�ȡ�ɹ������ϣ��´��ȴ�����ʼ��ȡ��
����sched_yield();
����break;
����case1: //˵���ϴλ�ȡl1ʧ�ܣ�����Ȼ�ȡ��l1��
����{
����unique_lock __u1(__l1);
����__i= try_lock(__l2,__l3...,__l0);//��ǰһ�ε�l0�ŵ��������Ȼ�ȡ����l1���ٳ��Ի�ȡ���������
����if(__i== -1)
����{
����__u1.release();
����return;
����}
����}
����if(__i== sizeof...(_L3)+ 1)//˵����l0�ŵ������ʱ������ȡl0ʱʧ���ˡ���ô˵�������������̳߳���l0����ô��һ��Ҫ��l0��ʼ��ȡ��
����__i= 0;
����else
����__i+= 2;//��Ϊ__i��ʾ�ǻ�ȡ�ڼ�����ʧ�ܣ��������try_lock(__l2,__l3..., __l0)�Ǵ�l2��ʼ�ģ��������Ҫ+2
����sched_yield();
����break;
����default:
����__lock_first(__i- 2,__l2,__l3...,__l0,__l1);//��Ϊ�����Ǵ�l2��ʼ�ģ����__iҪ��2��
����return;
����}
����}
����}
����template<class_L0, class_L1, class_L2, class..._L3>
����inline_LIBCPP_INLINE_VISIBILITY
����void lock(_L0& __l0,_L1& __l1,_L2& __l2,_L3& ...__l3)
����{
����__lock_first(0,__l0,__l1,__l2,__l3...);
����}
�������Կ����������std::lock��ʵ���ǣ�
�����Ȼ�ȡһ������Ȼ���ٵ���std::try_lockȥ��ȡʣ�µ��������ʧ���ˣ����´��Ȼ�ȡ�ϴ�ʧ�ܵ�����
�����ظ�����Ĺ��̣�ֱ���ɹ���ȡ�����е�����
����������㷨�ñȽ�����ķ�ʽʵ���˲�������ת��
����std::timed_mutex
����std::timed_mutex �������װ��mutex��condition���������������������ã�
����try_lock_for
����try_lock_until
����ʵ������posix��mutex��condition�İ�װ��
����classtimed_mutex
����{
����mutex __m_;
����condition_variable __cv_;
����bool__locked_;
����public:
����timed_mutex();
����~timed_mutex();
����private:
����timed_mutex(consttimed_mutex&);// = delete;
����timed_mutex& operator=(consttimed_mutex&);// = delete;
����public:
����voidlock();
����booltry_lock()_NOEXCEPT;
����template<class_Rep, class_Period>
����_LIBCPP_INLINE_VISIBILITY
����booltry_lock_for(constchrono::duration& __d)
����{returntry_lock_until(chrono::steady_clock::now()+ __d);}
����template<class_Clock, class_Duration>
����booltry_lock_until(constchrono::time_point& __t);
����voidunlock()_NOEXCEPT;
����};
����template<class_Clock, class_Duration>
����bool timed_mutex::try_lock_until(constchrono::time_point& __t)
����{
����usingnamespacechrono;
����unique_lock __lk(__m_);
����boolno_timeout= _Clock::now()��
������
����std::recursive_mutex��std::recursive_timed_mutex
����������ʵ������std::mutex��std::timed_mutex ��recursiveģʽ��ʵ�֣������û���߿����ظ���ε���lock()������
������posix mutex���recursive mutex��һ���ġ�
��������std::recursive_mutex�Ĺ��캯����֪���ˡ�
����recursive_mutex::recursive_mutex()
����{
����pthread_mutexattr_t attr;
����intec= pthread_mutexattr_init(&attr);
����if(ec)
����gotofail;
����ec= pthread_mutexattr_settype(&attr,PTHREAD_MUTEX_RECURSIVE);
����if(ec)
����{
����pthread_mutexattr_destroy(&attr);
����gotofail;
����}
����ec= pthread_mutex_init(&__m_,&attr);
����if(ec)
����{
����pthread_mutexattr_destroy(&attr);
����gotofail;
����}
����ec= pthread_mutexattr_destroy(&attr);
����if(ec)
����{
����pthread_mutex_destroy(&__m_);
����gotofail;
����}
����return;
����fail:
����__throw_system_error(ec,"recursive_mutex constructor failed");
����}
����std::cv_status
�������������ʾcondition�ȴ����ص�״̬�ģ��������������ʾlock��״̬����;��ࡣ
����enumcv_status
����{
����no_timeout,
����timeout
����};
����std::condition_variable
������װ��posix condition variable��
����classcondition_variable
����{
����pthread_cond_t __cv_;
����public:
����condition_variable(){__cv_= (pthread_cond_t)PTHREAD_COND_INITIALIZER;}
����~condition_variable();
����private:
����condition_variable(constcondition_variable&);// = delete;
����condition_variable& operator=(constcondition_variable&);// = delete;
����public:
����voidnotify_one()_NOEXCEPT;
����voidnotify_all()_NOEXCEPT;
����voidwait(unique_lock& __lk)_NOEXCEPT;
����template<class_Predicate>
����voidwait(unique_lock& __lk,_Predicate __pred);
����template<class_Clock, class_Duration>
����cv_status wait_until(unique_lock& __lk,
����constchrono::time_point& __t);
����template<class_Clock, class_Duration, class_Predicate>
����boolwait_until(unique_lock& __lk,
����constchrono::time_point& __t,
����_Predicate __pred);
����template<class_Rep, class_Period>
����cv_statuswait_for(unique_lock& __lk,
����constchrono::duration& __d);
����template<class_Rep, class_Period, class_Predicate>
����bool wait_for(unique_lock& __lk,
����constchrono::duration& __d,
����_Predicate __pred);
����typedefpthread_cond_t* native_handle_type;
����_LIBCPP_INLINE_VISIBILITY native_handle_type native_handle(){return&__cv_;}
����private:
����void__do_timed_wait(unique_lock& __lk,
����chrono::time_point)_NOEXCEPT;
����};
��������ĺ������Ƿ���ֱ����ʵ�֣�ֵ��ע����ǣ�
����cv_status��ͨ���ж�ʱ���ȷ���ģ������ʱ����cv_status::timeout�����û�г�ʱ����cv_status::no_timeout��
����condition_variable::wait_until�������Դ���һ��predicate����һ���û��Զ�����ж��Ƿ���������ĺ��������Ҳ�Ǻܳ�����ģ���̵ķ����ˡ�
����template<class_Clock, class_Duration>
����cv_status condition_variable::wait_until(unique_lock& __lk,
����constchrono::time_point& __t)
����{
����usingnamespacechrono;
����wait_for(__lk,__t- _Clock::now());
����return_Clock::now()
����bool condition_variable::wait_until(unique_lock& __lk,
����constchrono::time_point& __t,
����_Predicate __pred)
����{
����while(!__pred())
����{
����if(wait_until(__lk,__t)== cv_status::timeout)
����return__pred();
����}
����returntrue;
����}
����std::condition_variable_any
����std::condition_variable_any�Ľӿں�std::condition_variableһ������ͬ����std::condition_variableֻ��ʹ��std::unique_lock����std::condition_variable_any����ʹ���κε�������
��������������Ϊʲôstd::condition_variable_any����ʹ�������������
����class_LIBCPP_TYPE_VIScondition_variable_any
����{
����condition_variable __cv_;
����shared_ptr __mut_;
����public:
����condition_variable_any();
����voidnotify_one()_NOEXCEPT;
����voidnotify_all()_NOEXCEPT;
����template<class_Lock>
����voidwait(_Lock& __lock);
����template<class_Lock, class_Predicate>
����voidwait(_Lock& __lock,_Predicate __pred);
����template<class_Lock, class_Clock, class_Duration>
����cv_status wait_until(_Lock& __lock,
����constchrono::time_point& __t);
����template<class_Lock, class_Clock, class_Duration, class_Predicate>
����bool wait_until(_Lock& __lock,
����constchrono::time_point& __t,
����_Predicate __pred);
����template<class_Lock, class_Rep, class_Period>
����cv_status wait_for(_Lock& __lock,
����constchrono::duration& __d);
����template<class_Lock, class_Rep, class_Period, class_Predicate>
����bool wait_for(_Lock& __lock,
����constchrono::duration& __d,
����_Predicate __pred);
����};
�������Կ�������std::condition_variable_any���shared_ptr __mut_����װ��mutex������һ�ж������ˣ��ع�std::unique_lock������װ��mutex��������ʱ�Զ��ͷ�mutex����std::condition_variable_any���ݹ�����shared_ptr�����ˡ�
������ˣ�Ҳ���Ժ����ɵó�std::condition_variable_any���std::condition_variable�����Ľ����ˡ�
���������Ķ�����
����sched_yield()������man�ֲ
����sched_yield() causes the calling thread to relinquish the CPU. The thread is moved to the end of the queue for its
����static priority and a new thread gets to run.
������C++14�ﻹ��std::shared_lock��std::shared_timed_mutex������libc++�ﻹû�ж�Ӧ��ʵ�֣���˲���������
�����ܽ�
����llvm libc++�еĸ���mutex, lock, condition variableʵ�����Ƿ����posix��Ķ�Ӧʵ�֡���װ�ļ��ɺ�һЩϸ��ֵ��ϸϸ����ѧϰ��
����������ʵ��Դ��֮�������ʹ�þ��������ˡ�
�������
����https://en.cppreference.com/w/cpp
����https://libcxx.llvm.org/
��ע��CPP�����ߡ�
�����ྫѡC/C++��������
������






























����˵�������а�