 )
)
����һ����ͬ������鷽����ʹ�����
����Lin�����о�����[1]��2014������Ӣ����ҽѧ��־��Lancet��JAMA������224��RCT�У�ʹ�ü���������ֻ��12����6%�������ֲ㣨���飩����������156����70%����ͼ1����

����ͼ1. 2014��NEJM��Lancet��JAMA�Ϸ���RCT��������鷽����N=224��
�������������ݿ�2014��ȫ�ꡰҽҩ����������ġ��ڿ����ġ����֣������Ϊ����� and������ or �ֲ㣩��������������ռ�������Ϊ�������������������1%��ͼ2����
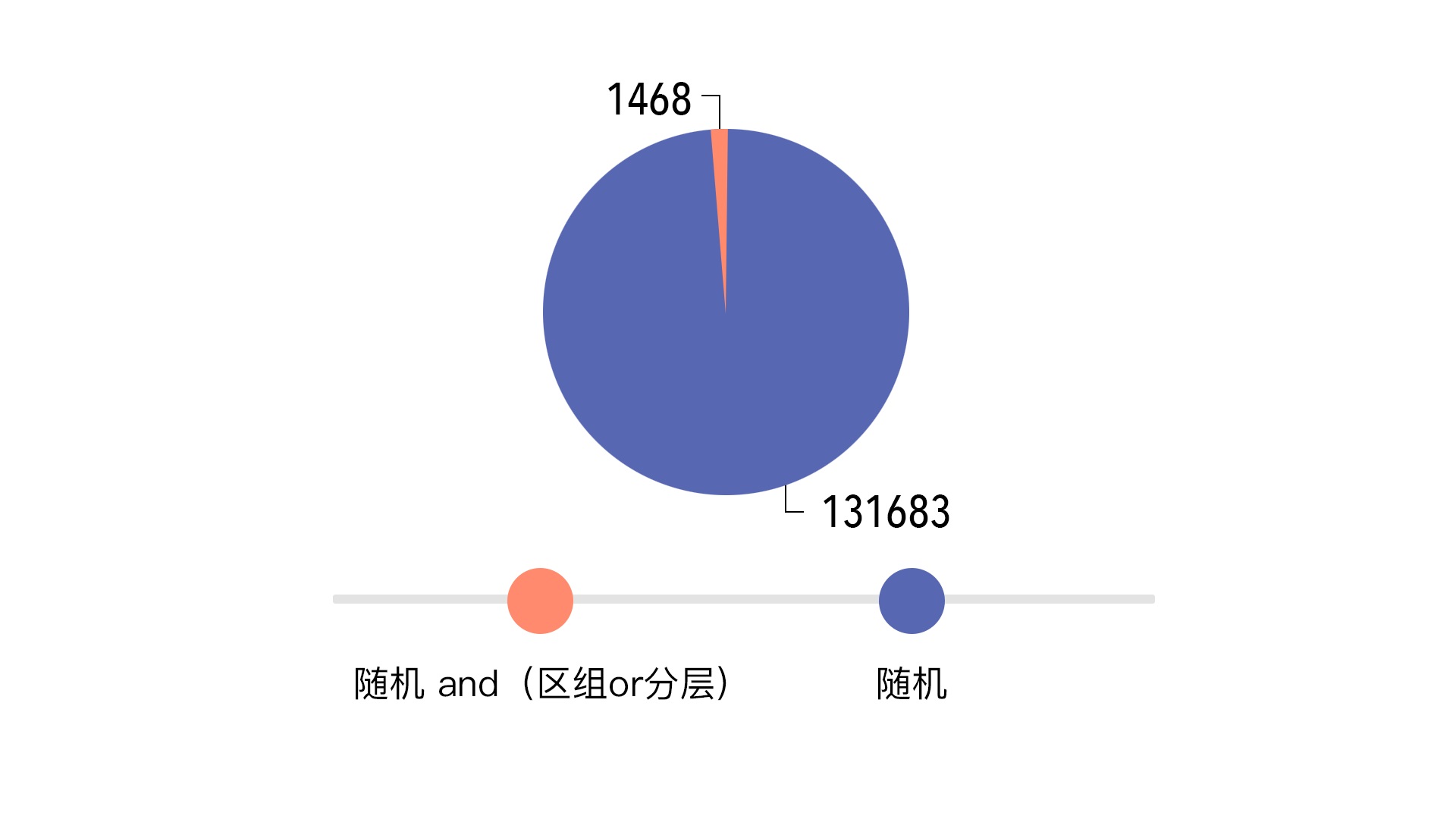
����ͼ2. 2014�������ݿ�ҽҩ���������ڿ����ĵ�����ʼ������
��������������֣�����ʰ�������� and������ or �ֲ㣩������1%�����ף����������Ϊ��������С�������顱�͡��ֲ�����������������������ǡ��ֲ����������
�������Բ�����ǣ����ı������о��У�����ʹ�÷ֲ㣨���飩������飬����ʹ���˵�δ��ϸ������
������ֻ����������Naive!�����Ѿ����ܣ����������ʱ�������������Ȳ��Ǵ�����¼�����ô��Ϊʲô���������У����ֲ��ü�������飬��������������ȫ��ȵ��о�������ô���أ�
��������ΪʲôҪʵʩ���������
������������£�������������ʹ1�������������������⣻2���������������ȣ� 3�������ҪЭ�������⡣����ҪЭ����ָ��������Ҫ����ָ����н�ǿ��ع�ϵ��Ԥ�����ӣ������䡢�������س̶ȵȡ���Ȼ����ʵ����������������ġ��෴�����������ʱ�������������Ȳ��Ǵ�����¼���
��������������ijRCT����10���о�����������������Ϊ��Ԥ�飨A���Ͷ����飨B��������8.8%�ĸ��ʲ����������������������Ԥ��8����������2�������߸�Ԥ��2����������8��������������ȫ��ȵĸ���ֻ��24.6%�����⣬�����ͬ�������о���������ʱ�����Բ�ͬ�������ڽ����о��Ķ�������أ���Ҳ�������������Ӱ�졣
����������������ܽ��������⡣
����ʵ���ϣ�������������ٴ�������ʹ���Ѿ����٣����ֲ������������(Stratified Blocked Randomization)����Ŀǰ�ٴ�������Ӧ�������㷺�ķ�����
��������������������ʵʩ
������ν���� (Block)�����ǿ����������һЩ���ӣ�ͼ3-1�����ڷ����о�����ʱ���Ƚ��о�����װ����Щ�����У���������䣬�����Ա�֤ÿ�������еĸ�Ԥ�飨A���Ͷ����飨B�����о�����������ȫ��ȡ�
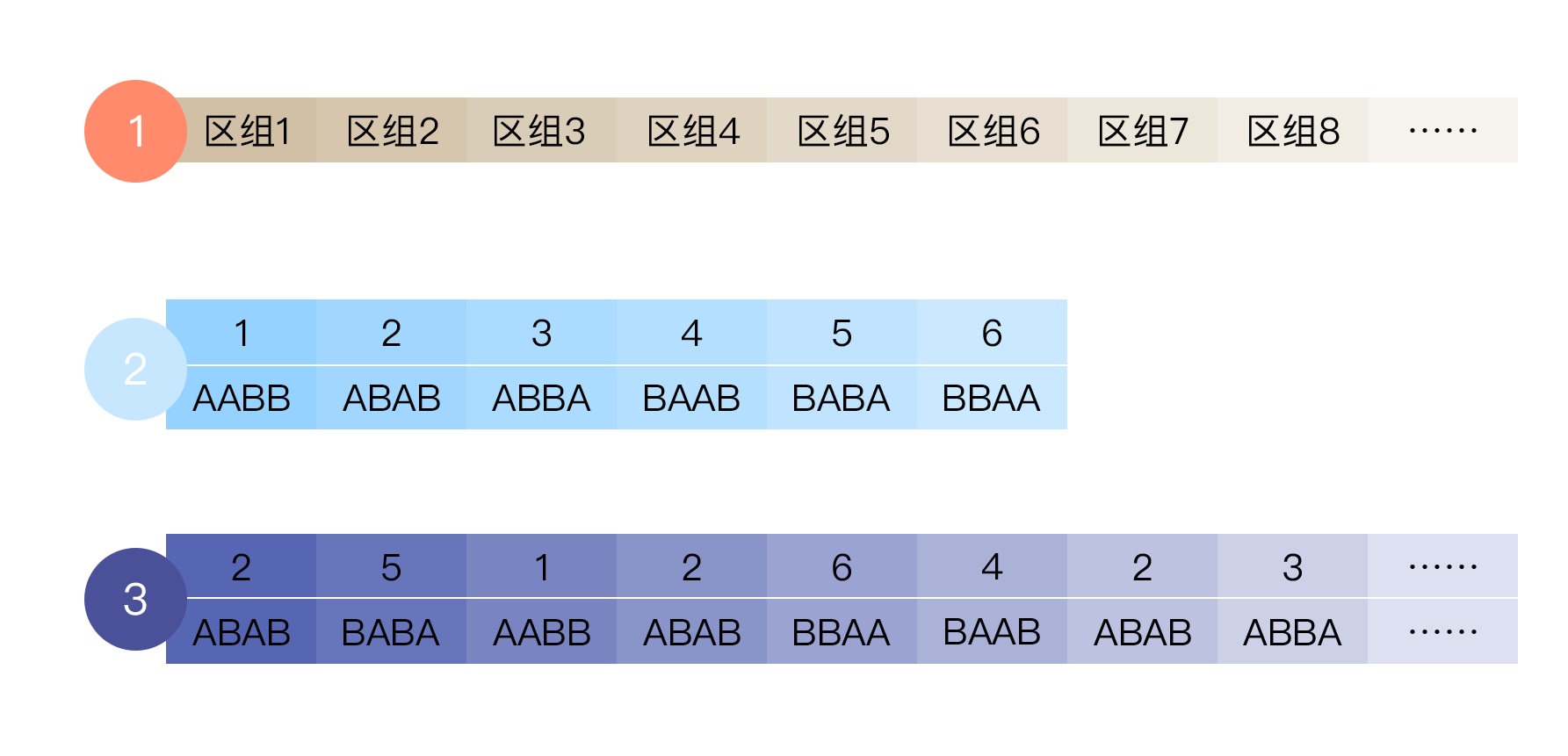
����ͼ3. �����������ʾ��ͼ
�������������ʱ��Ҫ���趨���鳤�ȣ���һ��������Ҫװ���ٸ��о��������鳤���������о�������2�����������鳤������Ϊ4-10����ֻ������ʱ�����鳤�ȿ�����4��6��8����
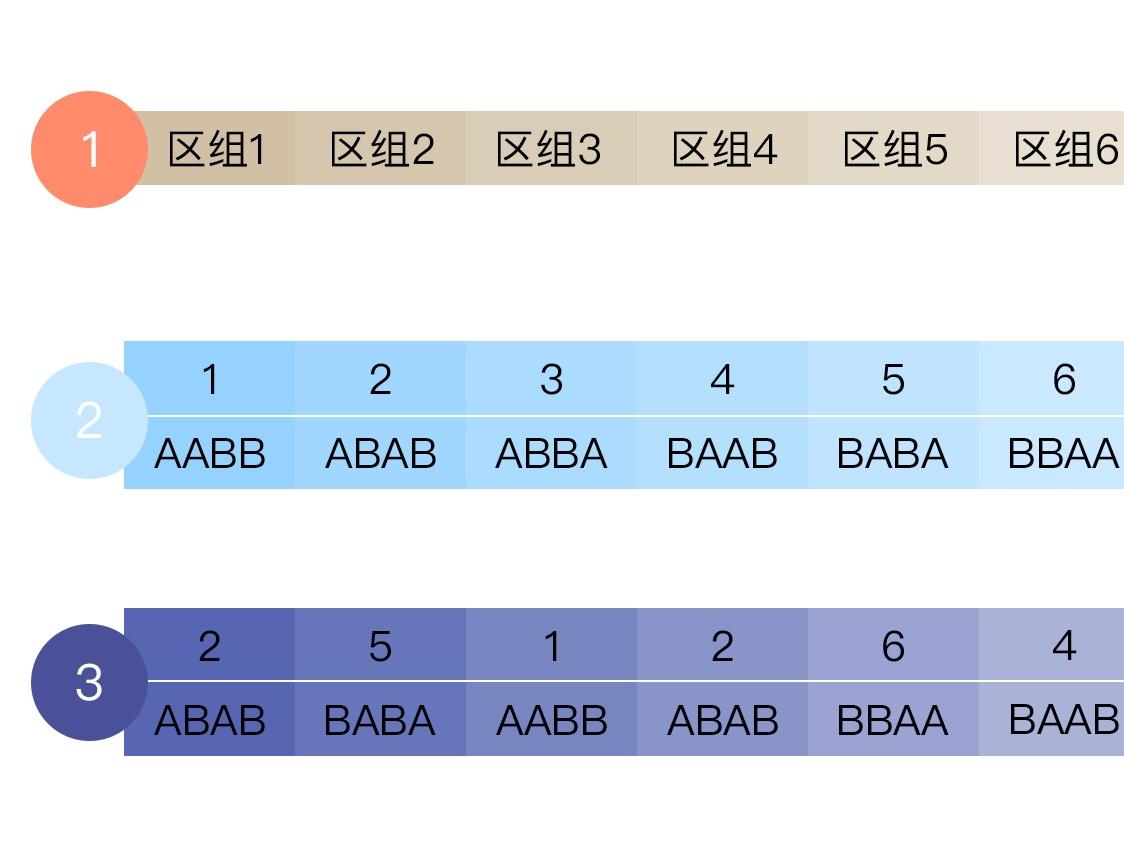
�������������鳤��4Ϊ����
����1��һ�������ڵ�4���о����������6�����з�ʽ��1. AABB, 2. ABAB, 3. ABBA, 4. BAAB, 5. BABA, 6. BBAA ��ͼ3-2��
����2��ȷ�������е�������ʽ��������Ҫ��6������������С����ǿ����ø��ַ�ʽ����SPSS��Excel��SAS�ȣ�����һ��������֣����磺92591264823981721367278057575098834352688429029����
����3����Ϊֻ��6�����з�ʽ����˿���ֻѡ��1-6֮������֣�25126423121362555343526422����
����4������������������������飨ͼ3-3������Ȼ��Ҳ���Բ���������������������顣
�������ˣ����������������ˣ�����������ȫ��ȡ�
�����ġ��������������������
����������о�δ����ä���������鳤�ȱ������ء����������������������飬���鳤��=4Ϊ����
����B A B ? �϶���A��
����A A ? ? �϶���B B��
�������������ѡ��ƫ�С���α�����������أ�
�����������Ϊ������ȵ����飬�����鳤������Ϊ4��6��6��8��6��4��8��8��4����
���������
����1. Lin Y, et al. The pursuit of balance: An overview of covariate-adaptive randomization techniques in clinical trials. Contemp Clin Trials. 2015;45:21-5.
�����������������עҽ�����ţ���������Ȥ����ʽ����ҽѧ֪ʶ���о���չ��̽���ٴ��о�����ѧ����






























����˵�������а�