【TechWeb报道】8月8日消息,据国外媒体报道,IBM研究所已经在分布式深度学习(DDL)中取得了一个新的里程碑,在接近交易效率的情况下,构建了一种可通过上百个处理器扩展DDL的软件。
|
深度学习技术是人工智能(AI)的一个分支,可模仿人脑的工作原理。它也是微软、Facebook、亚马逊和谷歌的重大关注焦点。
IBM的这项研究解决了深度学习的主要挑战之一:虽然大型神经网络和大型数据集有助于深度学习,但也会带来更长的训练时间。
培训大规模、深度学习的人工智能模型可能需要几天或几周的时间。
这个过程需要很长时间,因为扩展的处理器会相互通信。
事实上,随着处理器的加速,情况变得更糟。更快的处理器可以学习得更快,但与传统软件一样,它们之间的通信无法跟上。
IBM研究所的IBM研究员和系统加速及记忆主管Hillery Hunter在一篇博客文章中写道:“基本上,更聪明、更快的处理器需要更好的交流方式,或者他们不同步,大部分时间都在等待对方的结果。”
“所以,如果没有速度可能降低性能。”
新的DDL软件解决了这个问题,它应该可以运行流行的开源代码,比如Tensorflow、“咖啡因”、Torch和Chainer(而不是大量的神经网络和数据集),性能和准确性都非常高。
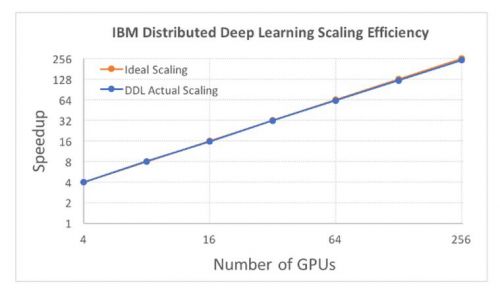
IBM研究所演示了使用“咖啡因”框架,如何在64个IBM Power系统中通过256个处理器实现性能提升和95%的扩展效率。
之前的记录是由Facebook人工智能研究设定的,该研究在2月2日的训练中实现了近90%的扩展效率。
此外,在这个新软件中,IBM 研究所在一个750万张图片训练的神经网络获得了33.8%的新图像识别精度,并在7小时内完成。微软的纪录是在10天内显示了29.8%的准确性。
“精度提高4%是一个巨大的飞跃,过去的典型改善一直不到1%,”亨特写道。(yoyo)
编译稿源:http://www.zdnet.com/article/ibm-research-achieves-new-milestone-in-deep-learning-performance/